HAN 概述
本文参考论文为 Hierarchical Attention Networks for Document Classification,来自
本篇论文是基于论文 Document Modeling with Gated Recurrent Neural Network for Sentiment Classification 作了一些改进,区别在于,本篇论文在其基础之上增加了 Attention 机制。
这里主要结合两篇论文分别对有注意力机制和没有注意力机制的文档的分层架构模型进行介绍。
Non-Attention HAN 模型
使用两个神经网络分别建模句子和文档,采用一种自下向上的基于向量的文本表示模型。首先使用 CNN/LSTM 来建模句子表示,接下来使用双向 GRU 模型对句子表示进行编码得到文档表示,这里论文中提到在情感分类任务中, GRU 往往比 RNN 效果要好。模型架构如下图所示:
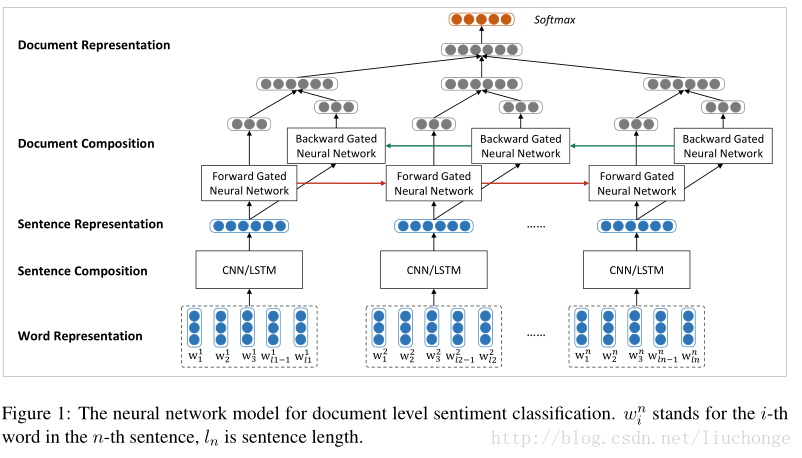
再上图中,词向量是从语料库中使用 Word2vec 模型训练出来的,保存在词嵌入矩阵中。然后使用 CNN/LSTM 模型学习句子表示,这里会将变长的句子表示成相同维度的向量,以消除句子长度不同所带来的不便。也就是说之后的 GRU 模型的输入是长度相同的句子向量。
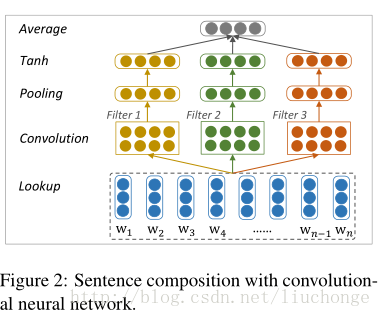
卷积模型如下图所示, filter 的宽度分别取 1,2,3 来编码 unigrams,bigrams 和 trigrams 的语义信息。最后使用一个Average层捕获全局信息并转化为固定长度的输出向量。
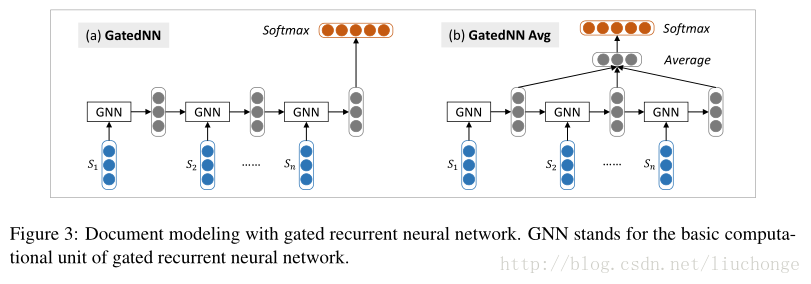
接下来进行文本层面建模,使用 GRU 模型,输入是变长的句子向量,输出固定长度的文本向量,这里会对最后每个单元的输出向量进行取平均操作,虽然会忽略句子顺序的信息,但是相对来说较为简单方便,如下图所示,其中 GNN 代表 GRU 的一个基础计算单元:
With-Attention HAN 模型 ★
接下来我们介绍一下本篇文章的模型架构,其实主要的思想和上面的差不多,也是分层构建只不过加上了两个Attention层,用于分别对句子和文档中的单词、句子的重要性进行建模。其主要思想是,首先考虑文档的分层结构:单词构成句子,句子构成文档,所以建模时也分这两部分进行。其次,不同的单词和句子具有不同的信息量,不能单纯的统一对待所以引入Attention机制。而且引入Attention机制除了提高模型的精确度之外还可以进行单词、句子重要性的分析和可视化,让我们对文本分类的内部有一定了解。模型主要可以分为下面四个部分,如下图所示:
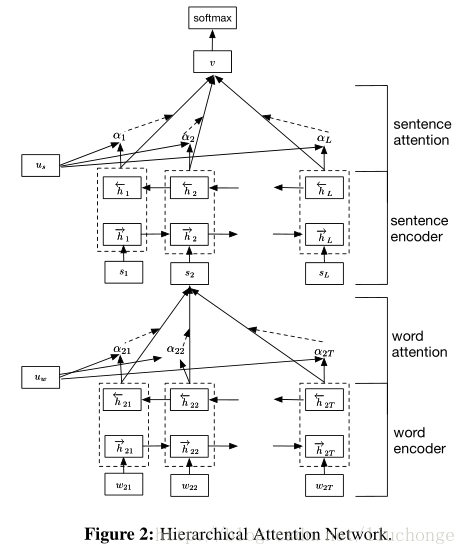
说明:
- a word sequence encoder,
- a word-level attention layer,
- a sentence encoder
- a sentence-level attention layer.
想了解 Attention 机制的同学可以参考我的另一篇文章 《图解 Attention》 。
