论文背景
论文 “Convolutional Neural Networks for Sentence Classification” 由 Yoon Kim 在 2014 年 EMNLP 会议上提出。
将卷积神经网络 CNN 应用到文本分类任务,利用多个不同 size 的 kernel 来提取句子中的关键信息(类似于多窗口大小的 ngram ),从而能够更好地捕捉局部相关性。
网络结构
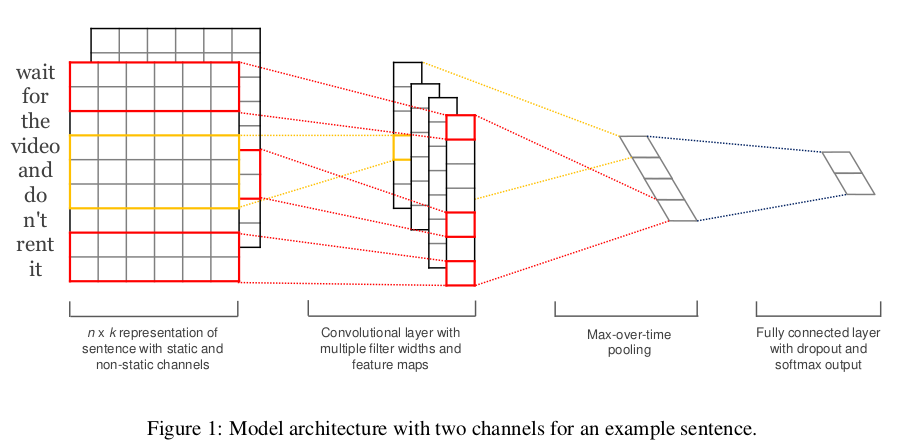
TextCNN 的详细过程原理图如下:
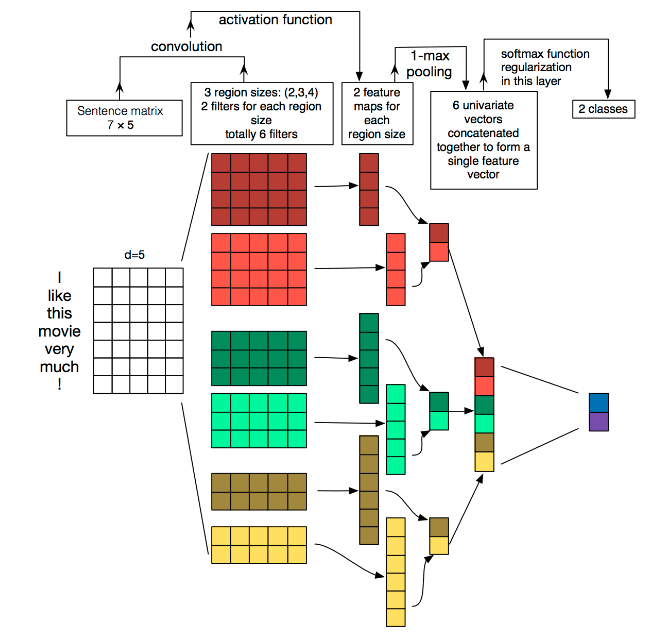
说明:
- Embedding:第一层是图中最左边的 7 乘 5 的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
- Convolution:然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出 channel 。
- MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过 pooling 层之后都能变成定长的表示。
- FullConnection and Softmax:最后接一层全连接的 softmax 层,输出每个类别的概率。
嵌入层(embedding layer)
TextCNN 使用预先训练好的词向量作 embedding layer 。对于数据集里的所有词,因为每个词都可以表征成一个向量,因此我们可以得到一个嵌入矩阵 M, M 里的每一行都是词向量。这个 M 可以是静态 (static) 的,也就是固定不变。可以是非静态 (non-static) 的,也就是可以根据反向传播更新。
论文给出了几种模型,其实这里基本都是针对 Embedding layer 做的变化。
- CNN-rand
作为一个基础模型,Embedding layer 所有 words 被随机初始化,然后模型整体进行训练。 - CNN-static
模型使用预训练的 word2vec 初始化 Embedding layer,对于那些在预训练的 word2vec 没有的单词,随机初始化。然后固定 Embedding layer,fine-tune 整个网络。 - CNN-non-static
同(CNN-static),只是训练的时候,Embedding layer跟随整个网络一起训练。 - CNN-multichannel
Embedding layer 有两个 channel,一个 channel 为 static,一个为 non-static 。然后整个网络 fine-tune 时只有一个 channel 更新参数。两个 channel 都是使用预训练的 word2vec 初始化的。
卷积层(convolution)
通道 Channels
- 图像中可以利用 (R, G, B) 作为不同 channel;
- 文本的输入的channel通常是不同方式的 embedding 方式(比如 word2vec 或 Glove),实践中也有利用静态词向量和 fine-tunning 词向量作为不同 channel 的做法。
- channel 也可以一个是词序列,另一个 channel 是对应的词性序列。接下来就可以通过加和或者拼接进行结合。
一维卷积 conv-1d
我们可以把嵌入层矩阵 M 看成是一幅图像,使用卷积神经网络去提取特征。由于句子中相邻的单词关联性总是很高的,因此可以使用一维卷积,即文本卷积与图像卷积的不同之处在于只在文本序列的一个方向(垂直)做卷积。卷积核的宽度固定为词向量的维度 d,高度是超参数,可以设置。
- 图像是二维数据;
- 文本是一维数据,因此在TextCNN 卷积用的是一维卷积(在word-level上是一维卷积;虽然文本经过词向量表达后是二维数据,但是在 embedding-level 上的二维卷积没有意义)。一维卷积带来的问题是需要通过设计不同 kernel_size 的 filter 获取不同宽度的视野。
池化层(pooling)
不同尺寸的卷积核得到的特征 (feature map) 大小也是不一样的,因此我们对每个 feature map 使用池化函数,使它们的维度相同。
Max Pooling
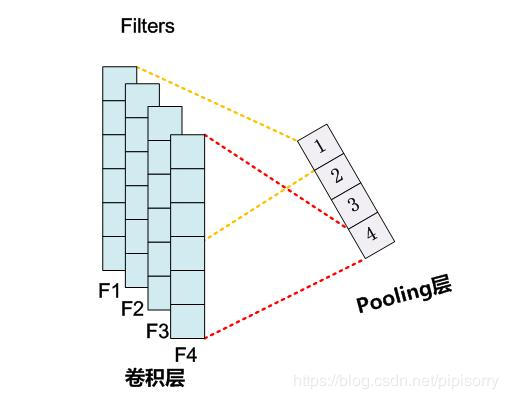
最常用的就是 1-max pooling,提取出 feature map 照片那个的最大值,通过选择每个 feature map 的最大值,可捕获其最重要的特征。这样每一个卷积核得到特征就是一个值,对所有卷积核使用 1-max pooling,再级联起来,可以得到最终的特征向量。
K-Max Pooling
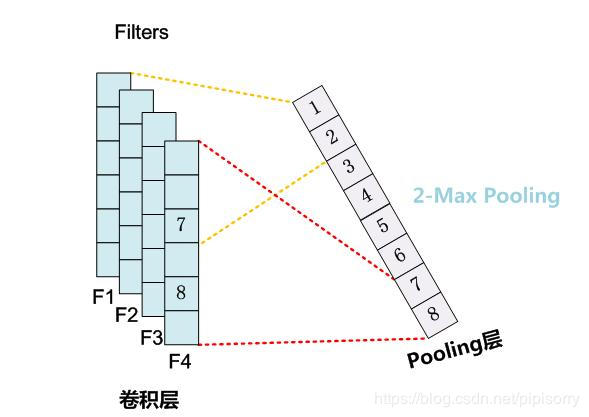
取所有特征值中得分在 Top–K 的值,并(保序拼接)保留这些特征值原始的先后顺序(即多保留一些特征信息供后续阶段使用)。
参见论文 A Convolutional Neural Network for Modelling Sentences
Chunk-MaxPooling
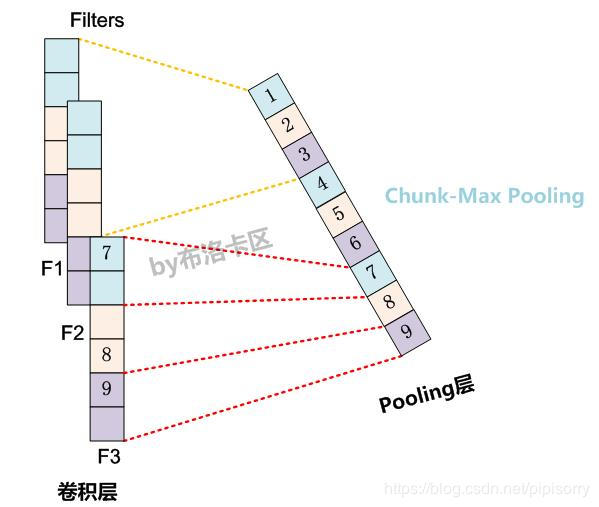
把某个 Filter 对应的 Convolution 层的所有特征向量进行分段,切割成若干段后,在每个分段里面各自取得一个最大特征值,比如将某个 Filter 的特征向量切成 3 个 Chunk,那么就在每个Chunk里面取一个最大值,于是获得 3 个特征值。因为是先划分 Chunk 再分别取 Max 值的,所以保留了比较粗粒度的模糊的位置信息;当然,如果多次出现强特征,则也可以捕获特征强度。至于这个Chunk怎么划分,可以有不同的做法,比如可以事先设定好段落个数,这是一种静态划分 Chunk 的思路;也可以根据输入的不同动态地划分 Chunk 间的边界位置,可以称之为动态 Chunk-Max 方法。 “Local Translation Prediction with Global Sentence Representation” 这篇论文也用实验证明了静态 Chunk-Max 性能相对 MaxPooling Over Time 方法在机器翻译应用中对应用效果有提升。
Dynamic Pooling
卷积时如果碰到 triggle 词,可以标记下不同色,max-pooling 时按不同标记划分 chunk。“Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks” 这篇论文提出的是一种 ChunkPooling 的变体,就是动态 Chunk-Max Pooling 的思路,实验证明性能有提升。
代码实现
代码结构
- data_tools.py: 数据预处理
- modules.py: 模型网络结构
- run.py: 运行文件,主程序入口
数据预处理
数据集使用复旦大学中文文本分类数据集,该数据集共 9833 篇文档,分为19个类别。训练语料和测试语料基本按照1:1的比例来划分。详细的代码解析参考我的另外一篇博客,关于如何预处理中文语料库的文章。
中文数据集1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246import os
import re
import jieba
from collections import Counter
from sklearn.utils import shuffle
def is_chinese(char):
"""
判断一个字符是否为中文汉字
:param char: str
:return: bool, 是返回 True, 否返回 False
"""
punctuation = [u'\u300a', u'\u2014', u'\u201c'] # ['《', '—', '“']
if u'\u4e00' <= char <= u'\u9fff' \
or u'\uff10' <= char <= u'\uff19' \
or char in punctuation:
return True
else:
return False
def get_listdir(path):
"""
获取一个路径下所有文件或文件夹的名字列表
:param path: str
:return: list
"""
return os.listdir(path)
def get_listpath(path):
"""
获取一个路径下所有文件或文件夹的路径列表
:param path: str
:return: list
"""
dirname = os.listdir(path)
path_ = [os.path.join(path, x) for x in dirname]
return path_
def parser_file2para(file):
"""
将文件 file 解析为段落列表
:param file: str, 文件名
:return: list, 段落列表
"""
start = (' ', ' ', ' ', ' ', ' ')
text = ""
s = False
paras = []
with open(file) as f:
# 处理文件中的每一行
for line in f:
if line.startswith(start) and len(line) > 4 and is_chinese(line[4]):
if text is not "":
text = re.sub('(.*?)', '', text)
if len(text) <= 10: # 假如 text 长度小于 10 文本丢弃
pass
else:
paras.append(text.replace(' ', ''))
text = ""
text += line.lstrip().rstrip('\n')
s = True
continue
if line.startswith(start) and len(line) > 4 and not is_chinese(line[4]):
if text is not "":
text = re.sub('(.*?)', '', text)
if len(text) <= 10:
pass
else:
paras.append(text.replace(' ', ''))
text = ""
s = False
continue
if s == True and line[0] is not ' ':
text += line.rstrip('\n')
continue
# 处理最后一段
if text is not "":
text = re.sub('(.*?)', '', text)
if len(text) <= 10:
pass
else:
paras.append(text.replace(' ', ''))
return paras
def parser_file2sentence(file, low, high):
"""
将文件 file 解析为句子列表
:param file: str, 文件名
:param low: 句子长度下限
:param high: 句子长度上限
:return: list, 句子列表
"""
sentences = []
paras = parser_file2para(file)
for para in paras:
sentence = re.split('(。”|!”|?”|。)|。|!|?)', para)
sentence = [x.strip() for x in sentence]
if len(sentence) == 1 and low <= len(*sentence) <= high:
sentences.extend(sentence)
continue
sentence = ["".join(i) for i in zip(sentence[0::2], sentence[1::2])]
sentence = [x for x in sentence if low <= len(x) <= high and x[0] != '(']
sentences.extend(sentence)
return sentences
def text_save(dirpath, filename, data):#filename为写入CSV文件的路径,data为要写入数据列表.
"""
将数据列表 data 写入 filename 文件中, 文件中的一行为数据 data 中的一列数据
:param dir: str, 文件夹路径
:param filename: str, 文件名
:param data: list, 数据列表
:return: None
"""
if not os.path.exists(dirpath):
os.makedirs(dirpath)
print(dirpath, "路路径已创建")
filepath = os.path.join(dirpath, filename)
file = open(filepath, 'a')
for line in data:
line = line + '\n' # 每行末尾追加换行符
file.write(line)
file.close()
print("保存文件成功")
def count_word_sentence(filepath):
"""
计算一个文件包含的句子数量和单词数量,该文件一句一行
:param filepath: str, 文件路径
:return: int, 单词数量, 句子数量, 句子平均长度, 句子最大长度, 句子最小长度
"""
num_word, num_sent = 0, 0
max_sent = -float('inf')
min_sent = float('inf')
with open(filepath, 'r') as f:
for line in f:
l = len(line)
max_sent = max(max_sent, l)
min_sent = min(min_sent, l)
num_word += l
num_sent += 1
if num_sent == 0:
ave_sent = 0
else:
ave_sent = num_word // num_sent
return num_word, num_sent, ave_sent, max_sent, min_sent
def cut_words(rawpath, datapath):
"""
将原路径的文件进行分词,然后存入新的文件,词语以空格分割.
:param rawpath: str, 原始数据路径
:param datapath: str, 处理后数据路径
:return: list, 词表
"""
words = []
if not os.path.exists(datapath):
for dirpath, dirnames, filenames in os.walk(rawpath):
if filenames is []:
continue
filepaths = [os.path.join(dirpath, filename) for filename in filenames]
for filepath, filename in zip(filepaths, filenames):
text = []
with open(filepath, 'r') as f:
for line in f:
sentence = jieba.lcut(line)
sentence = sentence[:-1]
words.extend(sentence)
sentence = ' '.join(sentence)
text.append(sentence)
data_path = os.path.join(datapath, os.path.basename(dirpath))
text_save(data_path, filename, text)
return words
else:
for dirpath, dirnames, filenames in os.walk(datapath):
if filenames is []:
continue
filepaths = [os.path.join(dirpath, filename) for filename in filenames]
for filepath, filename in zip(filepaths, filenames):
with open(filepath, 'r') as f:
for line in f:
sentence = line.split(' ')
sentence = sentence[:-1]
words.extend(sentence)
return words
def read_dataset(rawpath, datapath, vocab_size):
"""
读取数据集,制作成训练集,验证集和测试集
:param rawpath: str, 原始数据路径
:param datapath: str, 处理后数据路径
:param vocab_size: int, 词表大小
:return: word2index, 单词到编码的映射
label2index, 标签到编码的映射
x_train_, 训练集输入
y_train, 训练集标签
x_dev_, 验证集输入
y_dev, 验证集标签
x_test_, 测试集输入
y_test, 测试集标签
"""
if not os.path.exists(datapath):
cut_words(rawpath, datapath)
x_train, y_train = [], []
x_test, y_test = [], []
words = []
for dirpath, dirnames, filenames in os.walk(datapath):
if filenames is []:
continue
filepaths = [os.path.join(dirpath, filename) for filename in filenames]
for filepath, filename in zip(filepaths, filenames):
tag = filename.split('-')[0]
with open(filepath, 'r') as f:
for line in f:
sentence = line.split(' ')
sentence = sentence[:-1]
if dirpath == os.path.join(datapath, 'train'):
x_train.append(sentence)
y_train.append(tag)
elif dirpath == os.path.join(datapath, 'test'):
x_test.append(sentence)
y_test.append(tag)
else:
pass
words.extend(sentence)
# 构建训练集,验证集,测试集
x_train, y_train = shuffle(x_train, y_train)
x_test, y_test = shuffle(x_test, y_test)
cut = len(y_test) // 2
x_dev, y_dev = x_test[:cut], y_test[:cut]
x_test, y_test = x_test[cut:], y_test[cut:]
# 构建词表映射
vocab = Counter(words).most_common(vocab_size)
word2index = {k_v[0]: i+2 for i, k_v in enumerate(vocab)}
word2index.update({"PAD": 0, "UNK": 1})
# 构建标签映射
label = sorted(list(set(y_train + y_dev + y_test)))
label2index = {tag: i for i, tag in enumerate(label)}
# 对数据集,验证机,测试集进行编码
max_sent_len = max([len(sent) for sent in x_train + x_dev + x_test])
x_train_ = [[word2index.get(w, 1) for w in sent] + [0] * (max_sent_len - len(sent)) for sent in x_train]
x_dev_ = [[word2index.get(w, 1) for w in sent] + [0] * (max_sent_len - len(sent)) for sent in x_dev]
x_test_ = [[word2index.get(w, 1) for w in sent] + [0] * (max_sent_len - len(sent)) for sent in x_test]
y_train = [label2index[tag] for tag in y_train]
y_dev = [label2index[tag] for tag in y_dev]
y_test = [label2index[tag] for tag in y_test]
return word2index, label2index, x_train_, y_train, x_dev_, y_dev, x_test_, y_test
附上该代码配套的英文数据集的预处理代码
英文数据集1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75from sklearn.utils import shuffle
from collections import Counter
import pickle
def read_TREC():
data = {}
def read(mode):
x, y = [], []
with open("data/TREC/TREC_" + mode + ".txt", "r", encoding="utf-8") as f:
for line in f:
if line[-1] == "\n":
line = line[:-1]
y.append(line.split()[0].split(":")[0])
x.append(line.split()[1:])
x, y = shuffle(x, y)
if mode == "train":
dev_idx = len(x) // 10
data["dev_x"], data["dev_y"] = x[:dev_idx], y[:dev_idx]
data["train_x"], data["train_y"] = x[dev_idx:], y[dev_idx:]
else:
data["test_x"], data["test_y"] = x, y
read("train")
read("test")
return data
def read_MR():
data = {}
x, y = [], []
with open("data/MR/rt-polarity.pos", "r", encoding="utf-8") as f:
for line in f:
if line[-1] == "\n":
line = line[:-1]
x.append(line.split())
y.append(1)
with open("data/MR/rt-polarity.neg", "r", encoding="utf-8") as f:
for line in f:
if line[-1] == "\n":
line = line[:-1]
x.append(line.split())
y.append(0)
x, y = shuffle(x, y)
dev_idx = len(x) // 10 * 8
test_idx = len(x) // 10 * 9
data["train_x"], data["train_y"] = x[:dev_idx], y[:dev_idx]
data["dev_x"], data["dev_y"] = x[dev_idx:test_idx], y[dev_idx:test_idx]
data["test_x"], data["test_y"] = x[test_idx:], y[test_idx:]
data["vocab"] = sorted(list(set([w for sent in data["train_x"] + data["dev_x"] + data["test_x"] for w in sent])))
# data["vocab"] = Counter([w for sent in data["train_x"] + data["dev_x"] + data["test_x"] for w in sent]).most_common(5000)
# data["vocab"] = [x for x, y in data["vocab"]]
data["classes"] = sorted(list(set(data["train_y"])))
data["word_to_idx"] = {w: i+2 for i, w in enumerate(data["vocab"])}
data["word_to_idx"].update({"PAD": 0, "UNK": 1})
data["label_to_idx"] = {l: i+2 for i, l in enumerate(data["classes"])}
# data["idx_to_word"] = {i: w for i, w in enumerate(data["vocab"])}
max_sent_len = max([len(sent) for sent in data["train_x"] + data["dev_x"] + data["test_x"]])
data["train_x_"] = [[data["word_to_idx"][w] for w in sent] + [0] * (max_sent_len - len(sent)) for sent in data["train_x"]]
data["dev_x_"] = [[data["word_to_idx"][w] for w in sent] + [0] * (max_sent_len - len(sent)) for sent in data["dev_x"]]
data["test_x_"] = [[data["word_to_idx"][w] for w in sent] + [0] * (max_sent_len - len(sent)) for sent in data["test_x"]]
return data
模型搭建
1 | from __future__ import print_function |
主程序入口
1 | import tensorflow as tf |
