数据集
Titanic 数据集是源自 1912 年泰坦尼克号沉没事故的存亡情况统计,1500 多人死于这场灾难。我们的训练数据集提供了共 891 名乘客的具体信息,包括姓名、性别、船舱等级、船票价格等,最重要的是 survived 信息:0/1 代表着死亡与幸存,我们的任务就是从这 891 名乘客信息中寻找特征,确定模型,用以预测测试数据集中其他 418 名乘客的幸存/死亡情况。
数据预处理
载入数据集
1 | # 载入数据集 |

1
2
3# 查看训练集和测试集信息
train.info()
test.info()

查看信息后发现 Age Cabin Embarked 数据不全,后续需要填充或者删除。
特征工程 Feature Engineering
Pclass
1 | train[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean() |

Name
在这个特征中,我们可以发现乘客的头衔。1
2
3for dataset in full_data:
dataset['Title'] = dataset['Name'].str.split(", ", expand=True)[1].str.split(".", expand=True)[0]
pd.crosstab(train['Sex'], train['Title'])

有些头衔的人数太少,我们将其合并为 Rare ,这里有两种写法
写法一:1
2
3
4
5
6
7for dataset in full_data:
dataset['Title'] = dataset['Title'].replace(['Capt', 'Col', 'Don', 'Dr', 'Jonkheer',\
'Lady', 'Major', 'Rev', 'Sir', 'the Countess', 'Dona'], 'Rare')
dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')
dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')
dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')
train[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()

写法二:1
2
3title_names = (data1['Title'].value_counts() < 10)
for dataset in full_data:
data1['Title'] = data1['Title'].apply(lambda x: 'Rare' if title_names.loc[x] == True else x)
以上两种写法,第一种修改比较细致,还将错误的类别修改正确;而第二种处理方式直接根据相应类别的数量小于一个阀值(这里是 10)进行判断,代码简洁,但是无法检查出错误的类。
Sex
1 | train[["Sex", "Survived"]].groupby(['Sex'], as_index=False).mean() |

Age
这部分特征缺失值较多,我们计算该特征的均值和标准差,并在 [均值-标准差,均值+标准差] 范围内产生随机整数。然后将年龄分成 5 个区间。1
2
3
4
5
6
7
8
9
10
11
12for dataset in full_data:
age_avg = dataset['Age'].mean()
age_std = dataset['Age'].std()
age_null_count = dataset['Age'].isnull().sum()
age_null_random_list = np.random.randint(age_avg - age_std, age_avg + age_std, size=age_null_count)
dataset['Age'][np.isnan(dataset['Age'])] = age_null_random_list
dataset['Age'] = dataset['Age'].astype(int)
dataset['AgeBin'] = pd.cut(dataset['Age'], 5)
train[['AgeBin', 'Survived']].groupby(['AgeBin'], as_index=False).mean()

SibSp and Parch
通过 SibSp (兄妹和配偶)的数量和 Parch (父母与子女)的数量,我们能够计算出一个新特征 Family Size (家庭人数)1
2
3for dataset in full_data:
dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1
train[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean()

由此我们可以计算出一个新特征,是否孤身一人1
2
3
4for dataset in full_data:
dataset['IsAlone'] = 0
dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1
train[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()

Fare
这部分特征在测试集上少量缺失,我们用中位数进行填充。然后将其分成 4 个区间。1
2
3
4for dataset in full_data:
dataset['Fare'] = dataset['Fare'].fillna(train['Fare'].median())
dataset['FareBin'] = pd.qcut(train['Fare'], 4)
train[['FareBin', 'Survived']].groupby(['FareBin'], as_index=False).mean()

Embarked
该特征少量缺失,我们用出现频率最多的值进行填充。1
2
3for dataset in full_data:
dataset['Embarked'] = dataset['Embarked'].fillna(dataset['Embarked'].mode()[0])
train[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean()

Ticket and Cabin
这两个特征 Ticket 为随机产生的数字,与分析无关,直接删除。 Cabin 缺失值太多,无法补全,也直接删除。1
2
3drop_columns = ['Ticket', 'Cabin']
for dataset in full_data:
dataset.drop(drop_columns, axis = 1, inplace=True)
最后通过代码 train.isnull().sum() 查看是否所有缺失值已处理完毕。
特征数值化
我们先打印下特征工程后处理的训练集,如下: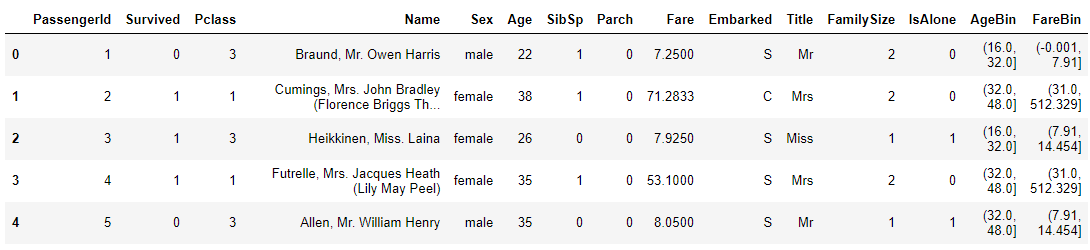
其中 Sex Embarked Title Title AgeBin FareBin 均为非数值,算法无法处理这种类型的数据,需要进行编码,转换为数值。1
2
3
4
5
6
7label = LabelEncoder()
for dataset in data_cleaner:
dataset['Sex_Code'] = label.fit_transform(dataset['Sex'])
dataset['Embarked_Code'] = label.fit_transform(dataset['Embarked'])
dataset['Title_Code'] = label.fit_transform(dataset['Title'])
dataset['AgeBin_Code'] = label.fit_transform(dataset['AgeBin'])
dataset['FareBin_Code'] = label.fit_transform(dataset['FareBin'])
导入所有模型预训练
对于同一个数据集,不同的模型表现效果不尽相同,对于一个问题到底选用何种模型是机器学习的一个难点。我们不妨将所有可能的模型导入,查看下在默认参数的情况下,各种机器学习算法表现优劣。
导入需要的库
1 | from sklearn import svm, tree, linear_model, neighbors, naive_bayes, ensemble, discriminant_analysis, gaussian_process |
定义机器学习算法列表
1 | MLA = [ |
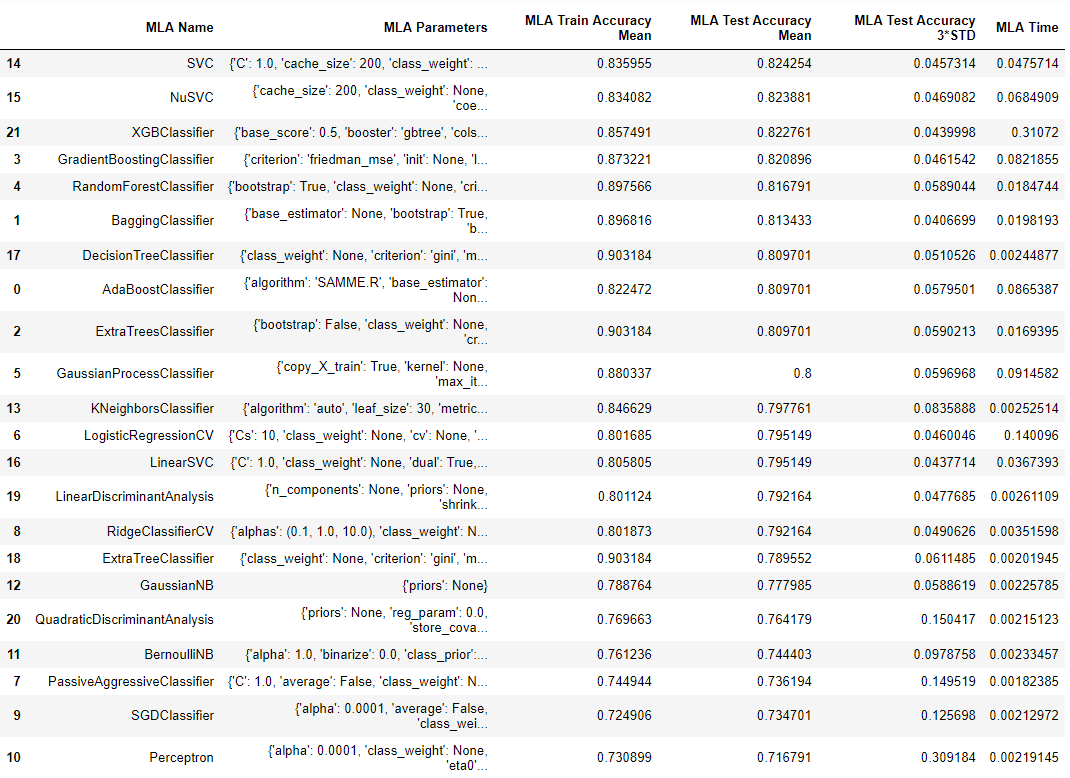
预训练并打印算法对比效果
用 sklearn.model_selection.ShuffleSplit 类将数据集进行交叉验证分割,详见官方文档说明,该方法可以作为 train_test_split 的替代,数据集 10 等分,其中 3 份作为测试,7 份作为训练集,1 份丢弃。1
cv_split = model_selection.ShuffleSplit(n_splits = 10, test_size = .3, train_size = .6, random_state = 0 )
创建算法比较表的表头,以及所有预测结果汇总表1
2
3
4
5
6# create table to compare MLA metrics
MLA_columns = ['MLA Name', 'MLA Parameters','MLA Train Accuracy Mean', 'MLA Test Accuracy Mean', 'MLA Test Accuracy 3*STD' ,'MLA Time']
MLA_compare = pd.DataFrame(columns = MLA_columns)
# create table to compare MLA predictions
MLA_predict = train[Target]
开始训练1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29# index through MLA and save performance to table
row_index = 0
train_X, train_y = train[Feature_x_bin], train[Target]
for alg in MLA:
#set name and parameters
MLA_name = alg.__class__.__name__
MLA_compare.loc[row_index, 'MLA Name'] = MLA_name
MLA_compare.loc[row_index, 'MLA Parameters'] = str(alg.get_params())
#score model with cross validation: http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_validate.html#sklearn.model_selection.cross_validate
cv_results = model_selection.cross_validate(alg, train_X, train_y, cv = cv_split)
MLA_compare.loc[row_index, 'MLA Time'] = cv_results['fit_time'].mean()
MLA_compare.loc[row_index, 'MLA Train Accuracy Mean'] = cv_results['train_score'].mean()
MLA_compare.loc[row_index, 'MLA Test Accuracy Mean'] = cv_results['test_score'].mean()
#if this is a non-bias random sample, then +/-3 standard deviations (std) from the mean, should statistically capture 99.7% of the subsets
MLA_compare.loc[row_index, 'MLA Test Accuracy 3*STD'] = cv_results['test_score'].std()*3 #let's know the worst that can happen!
#save MLA predictions - see section 6 for usage
alg.fit(train_X, train_y)
MLA_predict[MLA_name] = alg.predict(train_X)
row_index+=1
#print and sort table: https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.sort_values.html
MLA_compare.sort_values(by = ['MLA Test Accuracy Mean'], ascending = False, inplace = True)
MLA_compare
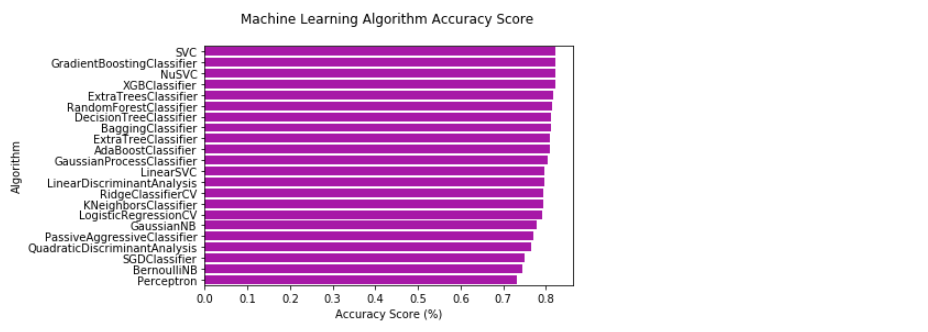
画出比较图:1
2
3
4
5
6
7
8
9import matplotlib.pyplot as plt
import seaborn as sns
#barplot using https://seaborn.pydata.org/generated/seaborn.barplot.html
sns.barplot(x='MLA Test Accuracy Mean', y = 'MLA Name', data = MLA_compare, color = 'm')
#prettify using pyplot: https://matplotlib.org/api/pyplot_api.html
plt.title('Machine Learning Algorithm Accuracy Score \n')
plt.xlabel('Accuracy Score (%)')
plt.ylabel('Algorithm')