简单线性回归模型

数据集
每一行数据表示一个学生的学习时间和考试分数。
|Hours |Scores |
|——-|——-|
|2.5 |21 |
|5.1 |47 |
|3.2 |27 |
|8.5 |75 |
|3.5 |30 |
|1.5 |20 |
|9.2 |88 |
|5.5 |60 |
|8.3 |81 |
|2.7 |25 |
|7.7 |85 |
|5.9 |62 |
|4.5 |41 |
|3.3 |42 |
|1.1 |17 |
|8.9 |95 |
|2.5 |30 |
|1.9 |24 |
|6.1 |67 |
|7.4 |69 |
|2.7 |30 |
|4.8 |54 |
|3.8 |35 |
|6.9 |76 |
|7.8 |86 |
第 1 步:数据预处理
这里导入我们需要的库,值得注意的是,这里多了一个 matplotlib.pyplot, matplotlib 是 python 上的一个 2D 绘图库, matplotlib 下的模块 pyplot 是一个有命令样式的函数集合, matplotlib.pyplot 是为我们对结果进行图像化作准备的。1
2
3import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
导入相关数据
1 | dataset = pd.read_csv('studentscores.csv') |
打印数据集,运行代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 Hours Scores
0 2.5 21
1 5.1 47
2 3.2 27
3 8.5 75
4 3.5 30
5 1.5 20
6 9.2 88
7 5.5 60
8 8.3 81
9 2.7 25
10 7.7 85
11 5.9 62
12 4.5 41
13 3.3 42
14 1.1 17
15 8.9 95
16 2.5 30
17 1.9 24
18 6.1 67
19 7.4 69
20 2.7 30
21 4.8 54
22 3.8 35
23 6.9 76
24 7.8 86
切分数据为输入特征 X 与标签 Y
这里我们需要使用 pandas 的 iloc(区分于 loc 根据 index 来索引, iloc 利用行号来索引)方法来对数据进行处理,第一个参数为行号,: 表示全部行,第二个参数 :1 表示截到第 1 列(也就是取第 0 列)1
2X = dataset.iloc[:, : 1].values
Y = dataset.iloc[:, 1].values
打印 X 和 Y 运行结果如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28X:
[[2.5]
[5.1]
[3.2]
[8.5]
[3.5]
[1.5]
[9.2]
[5.5]
[8.3]
[2.7]
[7.7]
[5.9]
[4.5]
[3.3]
[1.1]
[8.9]
[2.5]
[1.9]
[6.1]
[7.4]
[2.7]
[4.8]
[3.8]
[6.9]
[7.8]]
Y:
[21 47 27 75 30 20 88 60 81 25 85 62 41 42 17 95 30 24 67 69 30 54 35 76 86]
划分训练集与测试集
导入 sklearn 库的 cross_validation 类来对数据进行训练集、测试集划分1
2from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=1/4, random_state=0)
第 2 步:训练集使用简单线性回归模型来训练
1 | from sklearn.linear_model import LinearRegression |
在 sklearn 线性回归还有一种模型 SGDRegressor ,它可以完成线性回归的随机梯度下降,代码如下:1
2
3from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(n_iter=50, penalty=None, eta0=0.1)
sgd_reg.fit(X_train, Y_train)
上面的参数说明如下:
- n_iter:迭代轮数
- penalty:正则化项,可选
nonel2l1elasticnet - eta0:学习率 $\eta$
比较线性回归的不同梯度下降算法,如下表:
第 3 步:预测结果
1 | Y_pred = regressor.predict(X_test) |
第 4 步:可视化
训练集结果可视化
1 | # 散点图 |
运行结果如下图所示: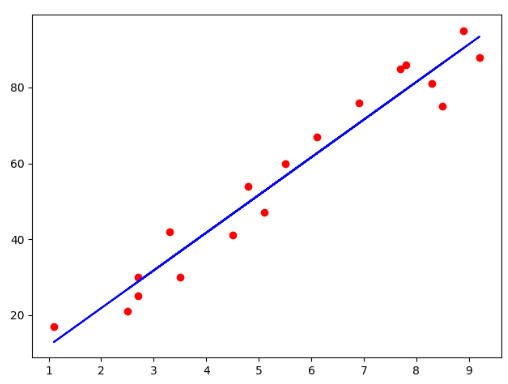
测试集结果可视化
1 | # 散点图 |
测试集结果如下图所示: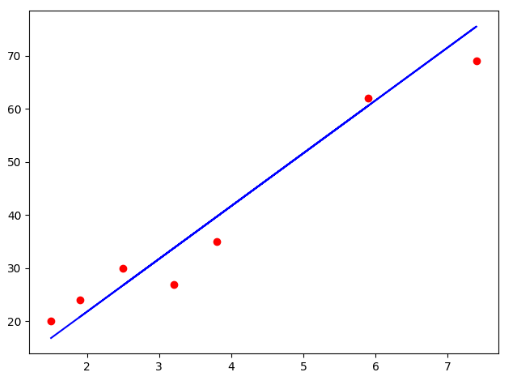
多元线性回归

数据集
| R&D Spend | Administration | Marketing Spend | State | Profit | |
|---|---|---|---|---|---|
| 165349.2 | 136897.8 | 471784.1 | New York | 192261.83 | |
| 162597.7 | 151377.59 | 443898.53 | California | 191792.06 | |
| 153441.51 | 101145.55 | 407934.54 | Florida | 191050.39 | |
| 144372.41 | 118671.85 | 383199.62 | New York | 182901.99 | |
| 142107.34 | 91391.77 | 366168.42 | Florida | 166187.94 | |
| 131876.9 | 99814.71 | 362861.36 | New York | 156991.12 | |
| 134615.46 | 147198.87 | 127716.82 | California | 156122.51 | |
| 130298.13 | 145530.06 | 323876.68 | Florida | 155752.6 | |
| 120542.52 | 148718.95 | 311613.29 | New York | 152211.77 | |
| 123334.88 | 108679.17 | 304981.62 | California | 149759.96 | |
| 101913.08 | 110594.11 | 229160.95 | Florida | 146121.95 | |
| 100671.96 | 91790.61 | 249744.55 | California | 144259.4 | |
| 93863.75 | 127320.38 | 249839.44 | Florida | 141585.52 | |
| 91992.39 | 135495.07 | 252664.93 | California | 134307.35 | |
| 119943.24 | 156547.42 | 256512.92 | Florida | 132602.65 | |
| 114523.61 | 122616.84 | 261776.23 | New York | 129917.04 | |
| 78013.11 | 121597.55 | 264346.06 | California | 126992.93 | |
| 94657.16 | 145077.58 | 282574.31 | New York | 125370.37 | |
| 91749.16 | 114175.79 | 294919.57 | Florida | 124266.9 | |
| 86419.7 | 153514.11 | 0 | New York | 122776.86 | |
| 76253.86 | 113867.3 | 298664.47 | California | 118474.03 | |
| 78389.47 | 153773.43 | 299737.29 | New York | 111313.02 | |
| 73994.56 | 122782.75 | 303319.26 | Florida | 110352.25 | |
| 67532.53 | 105751.03 | 304768.73 | Florida | 108733.99 | |
| 77044.01 | 99281.34 | 140574.81 | New York | 108552.04 | |
| 64664.71 | 139553.16 | 137962.62 | California | 107404.34 | |
| 75328.87 | 144135.98 | 134050.07 | Florida | 105733.54 | |
| 72107.6 | 127864.55 | 353183.81 | New York | 105008.31 | |
| 66051.52 | 182645.56 | 118148.2 | Florida | 103282.38 | |
| 65605.48 | 153032.06 | 107138.38 | New York | 101004.64 | |
| 61994.48 | 115641.28 | 91131.24 | Florida | 99937.59 | |
| 61136.38 | 152701.92 | 88218.23 | New York | 97483.56 | |
| 63408.86 | 129219.61 | 46085.25 | California | 97427.84 | |
| 55493.95 | 103057.49 | 214634.81 | Florida | 96778.92 | |
| 46426.07 | 157693.92 | 210797.67 | California | 96712.8 | |
| 46014.02 | 85047.44 | 205517.64 | New York | 96479.51 | |
| 28663.76 | 127056.21 | 201126.82 | Florida | 90708.19 | |
| 44069.95 | 51283.14 | 197029.42 | California | 89949.14 | |
| 20229.59 | 65947.93 | 185265.1 | New York | 81229.06 | |
| 38558.51 | 82982.09 | 174999.3 | California | 81005.76 | |
| 28754.33 | 118546.05 | 172795.67 | California | 78239.91 | |
| 27892.92 | 84710.77 | 164470.71 | Florida | 77798.83 | |
| 23640.93 | 96189.63 | 148001.11 | California | 71498.49 | |
| 15505.73 | 127382.3 | 35534.17 | New York | 69758.98 | |
| 22177.74 | 154806.14 | 28334.72 | California | 65200.33 | |
| 1000.23 | 124153.04 | 1903.93 | New York | 64926.08 | |
| 1315.46 | 115816.21 | 297114.46 | Florida | 49490.75 | |
| 0 | 135426.92 | 0 | California | 42559.73 | |
| 542.05 | 51743.15 | 0 | New York | 35673.41 | |
| 0 | 116983.8 | 45173.06 | California | 14681.4 |
第 1 步: 数据预处理
导入库
1 | import pandas as pd |
导入数据集
1 | dataset = pd.read_csv('50_Startups.csv') |
通过 print(X[:10]) print(Y[:10]) 打印 X 和 Y 前 10 行数据1
2
3
4
5
6
7
8
9
10
11
12
13
14X前10行数据
[[165349.2 136897.8 471784.1 'New York']
[162597.7 151377.59 443898.53 'California']
[153441.51 101145.55 407934.54 'Florida']
[144372.41 118671.85 383199.62 'New York']
[142107.34 91391.77 366168.42 'Florida']
[131876.9 99814.71 362861.36 'New York']
[134615.46 147198.87 127716.82 'California']
[130298.13 145530.06 323876.68 'Florida']
[120542.52 148718.95 311613.29 'New York']
[123334.88 108679.17 304981.62 'California']]
Y前10行数据
[192261.83 191792.06 191050.39 182901.99 166187.94 156991.12 156122.51
155752.6 152211.77 149759.96]
将类别数据数字化
1 | from sklearn.preprocessing import LabelEncoder, OneHotEncoder |
分别打印 labelencoder 和 onehotencoder 处理后 X 的前 10 行结果1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32labelencoder:
[[165349.2 136897.8 471784.1 2]
[162597.7 151377.59 443898.53 0]
[153441.51 101145.55 407934.54 1]
[144372.41 118671.85 383199.62 2]
[142107.34 91391.77 366168.42 1]
[131876.9 99814.71 362861.36 2]
[134615.46 147198.87 127716.82 0]
[130298.13 145530.06 323876.68 1]
[120542.52 148718.95 311613.29 2]
[123334.88 108679.17 304981.62 0]]
onehot:
[[0.0000000e+00 0.0000000e+00 1.0000000e+00 1.6534920e+05 1.3689780e+05
4.7178410e+05]
[1.0000000e+00 0.0000000e+00 0.0000000e+00 1.6259770e+05 1.5137759e+05
4.4389853e+05]
[0.0000000e+00 1.0000000e+00 0.0000000e+00 1.5344151e+05 1.0114555e+05
4.0793454e+05]
[0.0000000e+00 0.0000000e+00 1.0000000e+00 1.4437241e+05 1.1867185e+05
3.8319962e+05]
[0.0000000e+00 1.0000000e+00 0.0000000e+00 1.4210734e+05 9.1391770e+04
3.6616842e+05]
[0.0000000e+00 0.0000000e+00 1.0000000e+00 1.3187690e+05 9.9814710e+04
3.6286136e+05]
[1.0000000e+00 0.0000000e+00 0.0000000e+00 1.3461546e+05 1.4719887e+05
1.2771682e+05]
[0.0000000e+00 1.0000000e+00 0.0000000e+00 1.3029813e+05 1.4553006e+05
3.2387668e+05]
[0.0000000e+00 0.0000000e+00 1.0000000e+00 1.2054252e+05 1.4871895e+05
3.1161329e+05]
[1.0000000e+00 0.0000000e+00 0.0000000e+00 1.2333488e+05 1.0867917e+05
3.0498162e+05]]
躲避虚拟变量陷阱
在回归预测中我们需要所有的数据都是 numeric 的,但是会有一些非 numeric 的数据,比如国家,省,部门,性别。这时候我们需要设置虚拟变量(Dummy variable)。做法是将此变量中的每一个值,衍生成为新的变量,是设为 1,否设为 0。举个例子,“性别”这个变量,我们可以虚拟出“男”和”女”两虚拟变量,男性的话“男”值为 1,”女”值为 0;女性的话“男”值为 0,”女”值为 1。
但是要注意,这时候虚拟变量陷阱就出现了。就拿性别来说,其实一个虚拟变量就够了,比如 1 的时候是“男”, 0 的时候是”非男”,即为女。如果设置两个虚拟变量“男”和“女”,语义上来说没有问题,可以理解,但是在回归预测中会多出一个变量,多出的这个变量将会对回归预测结果产生影响。一般来说,如果虚拟变量要比实际变量的种类少一个。
在多重线性回归中,变量不是越多越好,而是选择适合的变量。这样才会对结果准确预测。如果 category 类的特征都放进去,拟合的时候,所有权重的计算,都可以有两种方法实现,一种是提高某个 category 的 w,一种是降低其他 category 的 w,这两种效果是等效的,也就是发生了共线性,虚拟变量系数相加和为 1,出现 完全共线陷阱。1
X = X[:, 1:]
拆分数据集为训练集和测试集
1 | from sklearn.model_selection import train_test_split |
第 2 步: 在训练集上训练多元线性回归模型
1 | from sklearn.linear_model import LinearRegression |
第 3 步: 在测试集上预测结果
1 | y_pred = regressor.predict(X_test) |
打印预测结果:1
2
3
4y_pred:
[103015.20159795 132582.27760816 132447.73845175 71976.09851258
178537.48221056 116161.24230165 67851.69209676 98791.73374687
113969.43533013 167921.06569552]
多项式回归模型
多项式回归就是线性回归的特殊情况,我们依然使用线性回归的优化器,但是在训练数据之前,我们使用 Scikit-Learning 的 PolynomialFeatures 类进行训练数据集的转换,让训练集中每个特征的平方(2 次多项式)作为新特征:1
2
3from sklearn.preprocessing import PolynomialFeatures
poly_features = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly_features.fit_transform(X) # X为训练数据
请注意,当存在多个特征时,多项式回归能够找出特征之间的关系(这是普通线性回归模型无法做到的)。 这是因为 LinearRegression 会自动添加当前阶数下特征的所有组合。例如,如果有两个特征 $a,b$,使用 3 阶(degree=3)的 LinearRegression 时,不仅有 $a^2,a^3,b^2$ 以及 $b^3$,同时也会有它们的其他组合项 $ab,a^2b,ab^2$ 。
PolynomialFeatures(degree=d) 把一个包含 $n$ 个特征的数组转换为一个包含 $\frac{(n+d)!}{d!n!}$ 特征的数组,$n!$ 表示 n 的阶乘,等于 $1 2 3 \cdots * n$ 。小心大量特征的组合爆炸!
线性模型的正则化
岭(Ridge)回归
第一种写法1
2
3from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha=1, solver="cholesky")
ridge_reg.fit(X, y)
第二种写法1
2
3from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(penalty="l2")
sgd_reg.fit(X, y.ravel())
Lasso 回归
第一种写法1
2
3from sklearn.linear_model import Lasso
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X, y)
第二种写法1
2
3from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(penalty="l1")
sgd_reg.fit(X, y)
弹性网络 ElasticNet
1 | from sklearn.linear_model import ElasticNet |
