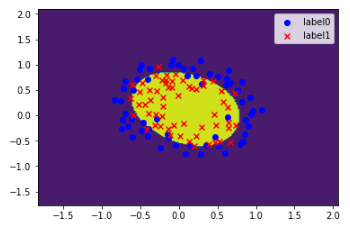
线性可分 SVM
导入包
1 | import numpy as np |
支持向量机的内置算法主要封装在 sklearn 中,直接导入 svm 即可。
生成样本数据
1 | # 创建40个点 |
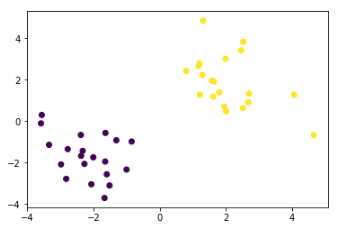
np.r_ 函数用于按列链接两个矩阵,绘制数据图如下:
训练模型
1 | # fit the model |
直接掉包,训练过程非常简单,输出为:
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=’ovr’, degree=3, gamma=’auto’, kernel=’linear’,
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
输出模型训练好的参数
1 | model.coef_ |
coef 为权值, intercept 为偏置值,输出结果如下:
array([[0.46732084, 0.45985473]])
array([-0.15579273])
画出分离平面
1 | # 获取分离平面 |
运行结果如下图: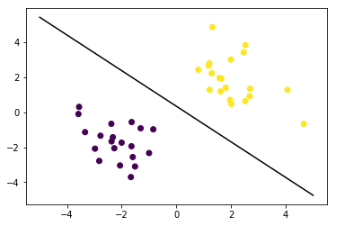
输出支持向量
1 | model.support_vectors_ |
输出结果如下:
array([[-0.84486093, -0.97715396],
[ 2.00694095, 0.47369914],
[ 1.2155688 , 1.27816325]])
画出间隔边界
1 | # 画出通过支持向量的分界线 |
运行结果如下图: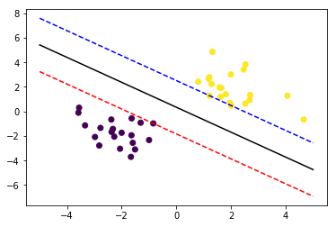
非线性可分 SVM
导入包
导入包
1 | import matplotlib.pyplot as plt |
载入数据
1 | # 载入数据 |
运行结果如下图: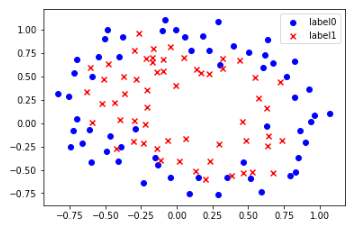
训练模型
1 | # fit the model |
kernel 有 5 个参数可选,分别对应不同的核函数: 'linear', 'poly', 'rbf', 'sigmoid', 'precomputed' 。 C 和 gamma 对应两个超参数,可以调整使得准确率最优。
获得模型准确率
1 | model.score(x_data,y_data) |
输出结果为:
0.847457627118644
画出决策边界
1 | # 获取数据值所在的范围 |
代码运行结果如下图: