数据结构与算法
基本数据结构类型
基本数据结构关系
Data Structure & Algorithm
Data Structure
- Array
- Stack / Queue
- PriorityQueue
- LinkedList
- Queue / Priority queue
- Stack
- Tree / Binary Search Tree
- HashTable
- Disjoint Set
- Trie
- BloomFilter
- LRU Cache
Algorithm
- Greedy
- Recursion/Backtrace
- Traversal
- Breadth-first/Depth-first search
- Divide and Conquer
- Dynamic ProgrammingBinary Search
- Graph
System Design
- System architecture overview
- Design+ scalability + flexibility
- Typical system design questions
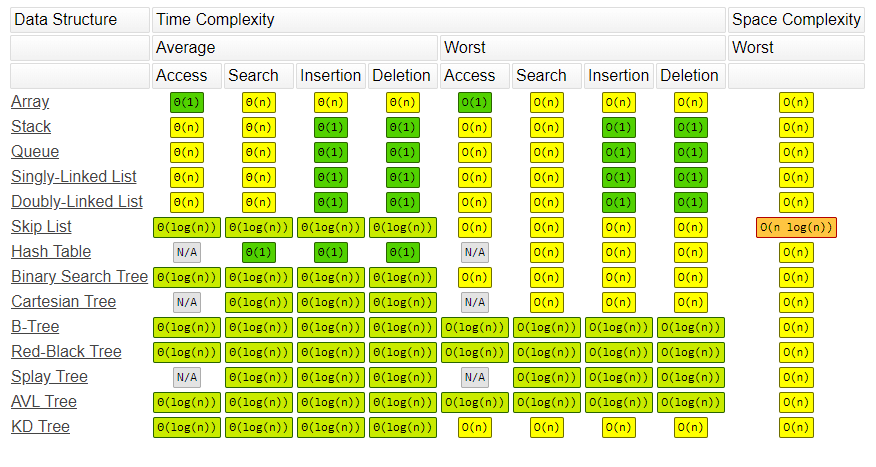
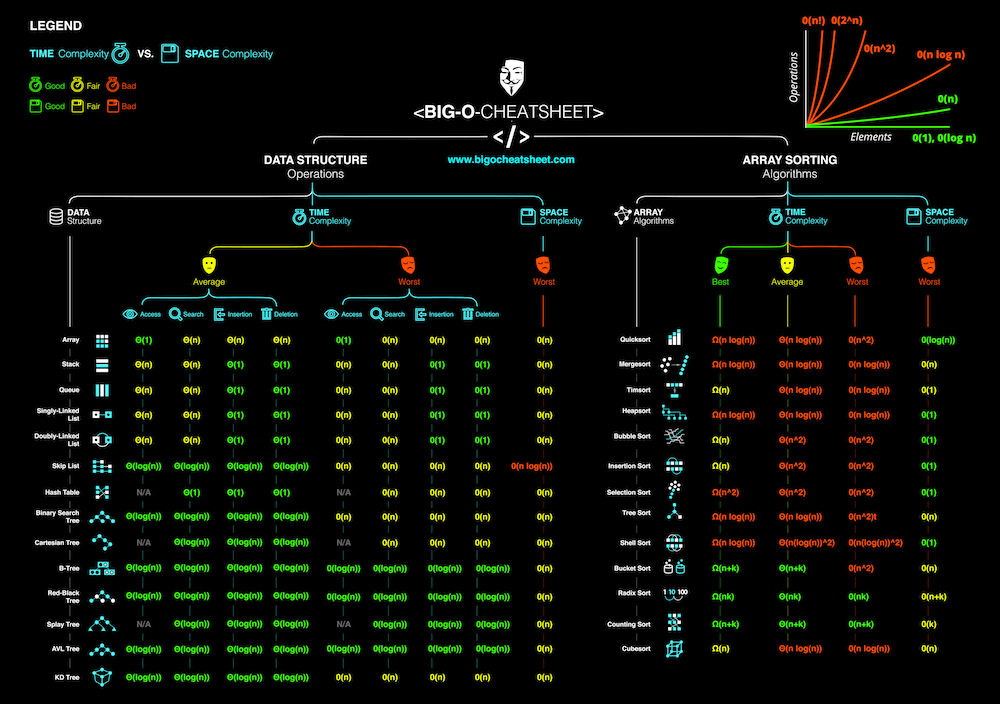
时间复杂度
常用数据结构运行的时间复杂度如下图所示
数组、链表(Array、 Linked List)
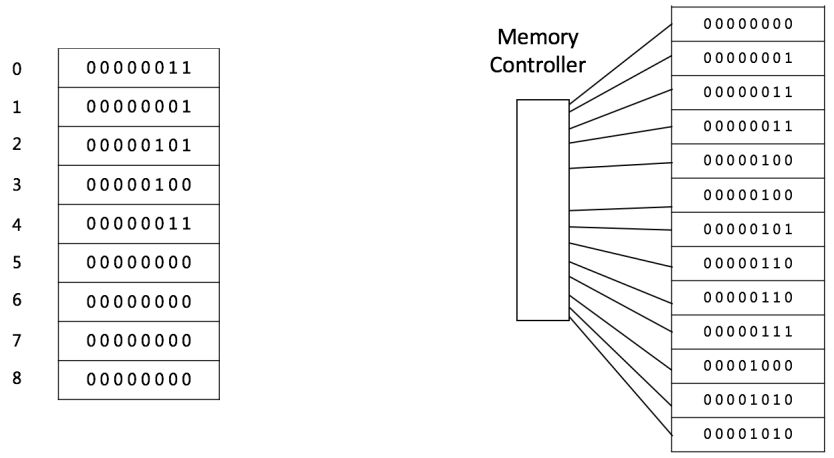
数组 Array
基本结构如下图所示:
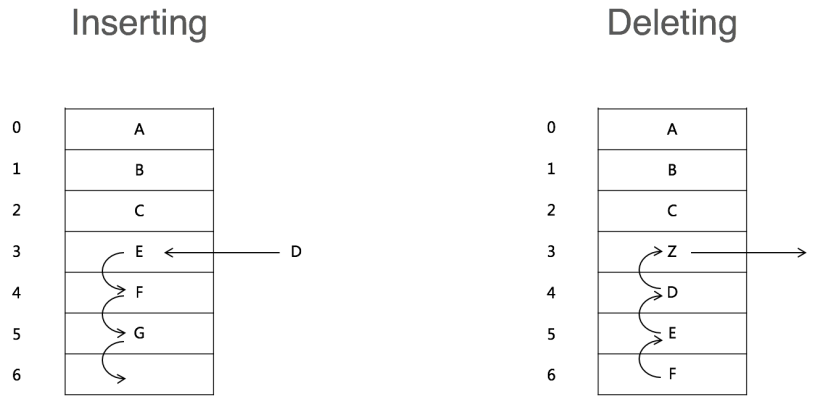
插入与删除操作:
Array 时间复杂度
- Access: O(1)
- Insert: 平均 O(n)
- Delete: 平均 O(n)
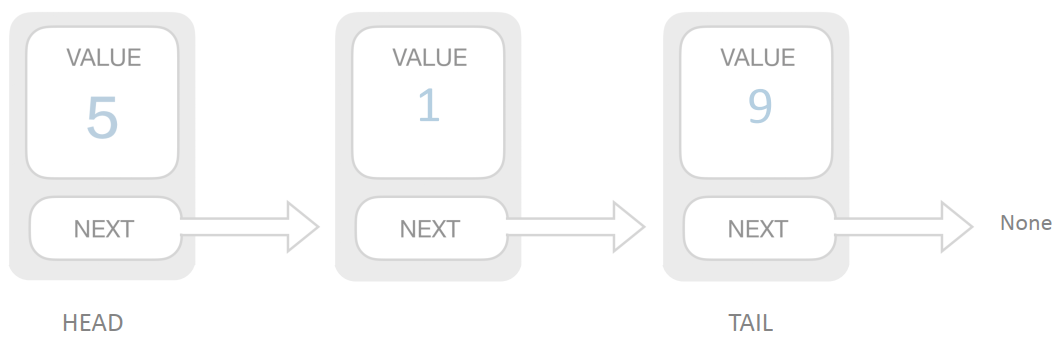
链表 Linked List
基本链表结构如下图所示:
节点的插入:
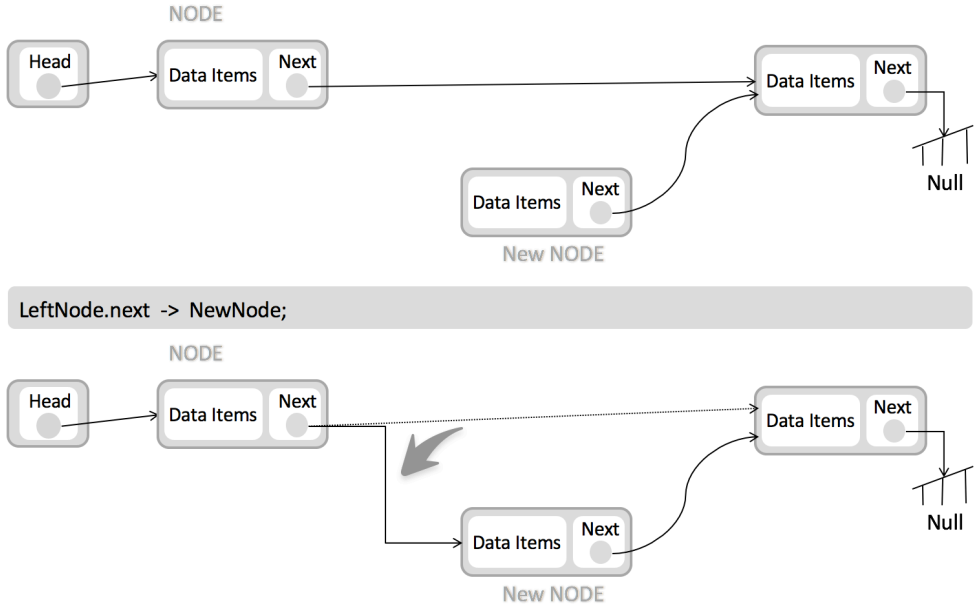
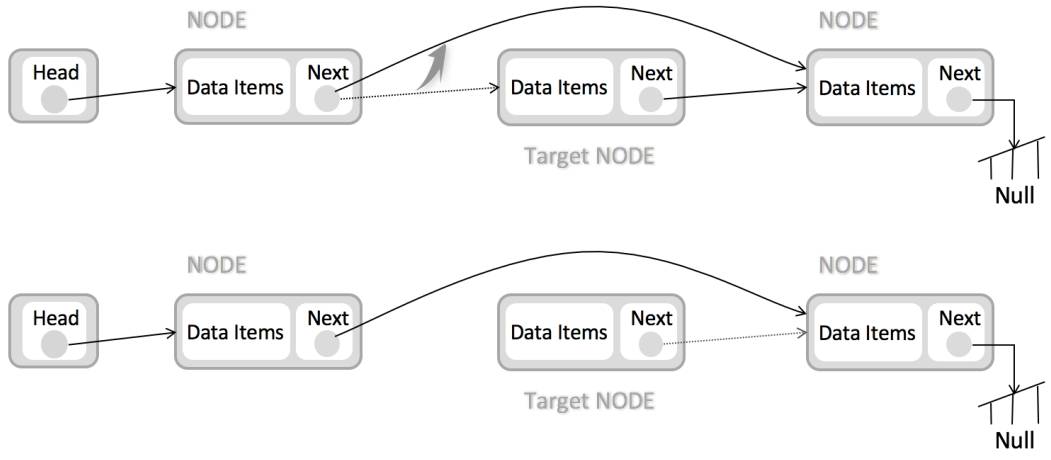
节点的删除:
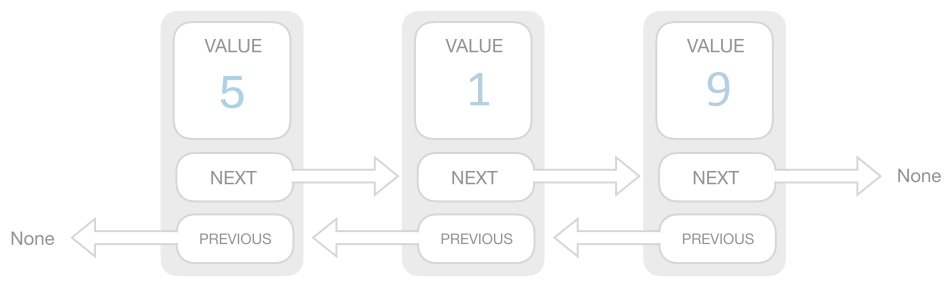
双链表基本结构如下图所示:
Linked List 时间复杂度
| space | prepend | append | lookup | insert | delete |
|---|---|---|---|---|---|
| O(n) | O(1) | O(1) | O(n) | O(1) | O(1) |
代码实战
问题一 反转链表(206)
问题描述
反转一个单链表。
示例
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
解法代码
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
ListNode cur = head;
ListNode prev = null;
while (cur != null){
ListNode temp = cur.next;
cur.next = prev;
prev = cur;
cur = temp;
}
return prev;
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11
12# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def reverseList(self, head: ListNode) -> ListNode:
cur, prev = head, None
while cur:
cur.next, prev, cur = prev, cur, cur.next
return prev
总结:Python 的代码比较特殊,在移动“指针”变量 cur 和 prev 的时候只需要一行代码(11行),而 Java 和 C++ 由于断开“指针”的时候可能会造成后续节点地址丢失,所以要用一个临时变量记录被断开的节点地址。
问题二 两两交换链表中的节点(24)
问题描述
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
示例
给定 1->2->3->4, 你应该返回 2->1->4->3.
解法代码
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode swapPairs(ListNode head) {
ListNode self = new ListNode(0);
ListNode pre = self;
pre.next = head;
while(pre.next != null && pre.next.next != null){
ListNode a = pre.next;
ListNode b = a.next;
ListNode temp = b.next;
pre.next = b;
b.next = a;
a.next = temp;
pre = a;
}
return self.next;
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def swapPairs(self, head: ListNode) -> ListNode:
pre, pre.next = self, head
while pre.next and pre.next.next:
a = pre.next
b = a.next
pre.next, b.next, a.next = b, a, b.next
pre = a
return self.next
总结: a 和 b 指向相邻两个节点, pre 指向相邻两个节点的前驱节点。其中 Python 代码中的创建一个新节点的语句比较特别 pre = self 相当于 Java 中的 ListNode self = new ListNode(0); ListNode pre = self; 这两句话。最后注意循环语句的终止条件。
问题三 环形链表(141)
问题描述
给定一个链表,判断链表中是否有环。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
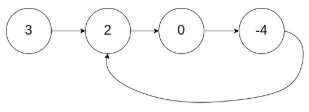
示例 2:
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = [1], pos = -1
输出:false
解释:链表中没有环。

解题思路分析
- 总结:(硬做)
从头指针开始往后遍历后续节点,在指定时间内找到空指针 null,证明有环;否则无环。 - 方法二(set,判重)
利用集合 set 判断是否遍历到重复节点,从头节点开始遍历链表,每遍历一个节点,将其放入集合 set,若遍历指针在找到空指针null前,set 出现重复元素,证明有环;若遍历到null时,set 中没有出现重复元素,证明无环。 - 方法三(快慢指针,龟兔赛跑)
快慢指针开始均指向头节点,遍历时快指针走两步,慢指针走一步,若快慢指针到达null没有相遇,证明无环;否则(相遇),证明有环。
解法一:龟兔赛跑
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public boolean hasCycle(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while(fast != null && slow !=null && fast.next !=null){
fast = fast.next.next;
slow = slow.next;
if(fast == slow)
return true;
}
return false;
}
}
Python代码
1 | # Definition for singly-linked list. |
解法二:利用集合
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Solution {
public boolean hasCycle(ListNode head) {
Set<ListNode> set = new HashSet<ListNode>();
ListNode p = head;
while(p != null){
if(set.contains(p))
return true;
else
set.add(p);
p = p.next;
}
return false;
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11class Solution(object):
def hasCycle(self, head):
collection = set([])
p = head
while p:
if p in collection:
return True
else:
collection.add(p)
p = p.next
return False
在以上代码的基础上做了点修改,先把遍历指针 p 加入集合 collection ,使用 len() 方法计算 collection 长度,如果 p 不在集合中,长度自然增加,利用集合存放不重复元素的性质,也可以解题。1
2
3
4
5
6
7
8
9
10
11
12class Solution(object):
def hasCycle(self, head):
collection = set([])
p = head
while p:
len1 = len(collection)
collection.add(p)
len2 = len(collection)
if len1 == len2:
return True
p = p.next
return False
问题四 环形链表Ⅱ(142)
问题描述
给定一个链表,返回链表开始入环的第一个节点。如果链表无环,则返回 null。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
说明:不允许修改给定的链表。
示例同 问题三
解法代码
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Solution {
public ListNode detectCycle(ListNode head) {
Set set = new HashSet();
ListNode p = head;
while(p != null){
if(set.contains(p))
return p;
else
set.add(p);
p = p.next;
}
return null;
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11class Solution(object):
def detectCycle(self, head):
collection = set([])
p = head
while p:
if p in collection:
return p
else:
collection.add(p)
p = p.next
return None
总结:该解题思路与 问题三 一致,只对上题代码稍作修改。
问题五 k个一组翻转链表(25)
问题描述
给出一个链表,每 k 个节点一组进行翻转,并返回翻转后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么将最后剩余节点保持原有顺序。
示例 :
给定这个链表:1->2->3->4->5
当 k = 2 时,应当返回: 2->1->4->3->5
当 k = 3 时,应当返回: 3->2->1->4->5
说明 :
你的算法只能使用常数的额外空间。
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
解题思路分析
- 方法一:直接反转
- 方法二:利用栈
新建一个新链表头节点,将原链表元素顺序入栈(一次进入k个),栈满后依次弹出栈顶元素加入新链表直至栈空,然后再将原链表前k个节点依次入栈,重复上述步骤。
解法一:直接反转
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
ListNode self = new ListNode(0);
self.next = null;
ListNode rear = self;
ListNode cur = head;
while(head != null){
int cnt = 0;
while(cnt < k && cur != null){
cnt ++;
cur = cur.next;
}
if(cnt != k){
rear.next = head;
return self.next;
}
else{
ListNode temp = null;
while(head != cur){
temp = head.next;
head.next = rear.next;
rear.next = head;
head = temp;
}
while(rear.next != null) rear = rear.next;
}
}
return self.next;
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def reverseKGroup(self, head: ListNode, k: int) -> ListNode:
rear = self
rear.next = None
cur = head
while head:
i = 0
while cur and i<k:
cur = cur.next
i += 1
if i != k:
rear.next = head
return self.next
else:
while head != cur:
head.next, rear.next, head = rear.next, head, head.next
while rear.next:
rear = rear.next
return self.next
解法二:利用栈
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
ListNode self = new ListNode(0);
self.next = null;
ListNode rear = self;
ListNode p = head;
Stack<ListNode> stack = new Stack<>();
while (p != null) {
int i = 0;
while (p !=null && i<k) {
stack.push(p);
p = p.next;
i += 1;
}
if (i < k) {
rear.next = head;
return self.next;
}
while (i>0) {
rear.next = stack.pop();
rear = rear.next;
i -= 1;
}
head = p;
}
rear.next = null;
return self.next;
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Solution:
def reverseKGroup(self, head: ListNode, k: int) -> ListNode:
stack = []
rear = self
rear.next = None
p = head
while p:
i = 0
while p and i<k:
stack.append(p)
p = p.next
i += 1
if i < k:
rear.next = head
return self.next
while i>0:
rear.next = stack.pop()
rear = rear.next
i -= 1
head = p
rear.next = None
return self.next
堆栈、队列(Stack、Queue)
- Stack - First In First Out (FIFO)
• Array or Linked List - Queue - First In Last Out (FILO)
• Array or Linked List
堆栈 Stack
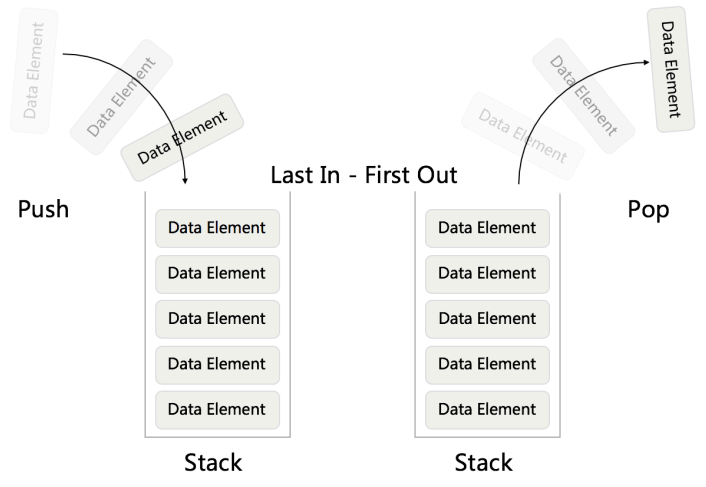
队列 Queue

代码实战
问题一 有效的括号(20)
问题描述
给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
注意空字符串可被认为是有效字符串。
示例 1:
输入: “()”
输出: true
示例 2:
输入: “()[]{}”
输出: true
示例 3:
输入: “(]”
输出: false
示例 4:
输入: “([)]”
输出: false
示例 5:
输入: “{[]}”
输出: true
解题思路分析
该题目最好的解法是利用堆栈,将字符串依次入栈:① 遇到左括号压入堆栈;② 遇到右括号,查看堆栈栈顶的括号是否与之匹配,若匹配,栈顶元素出栈,若不匹配直接返回 false;③ 若所有元素走完,栈内还有元素返回 false,否则返回 true 。
解法代码
Java代码
1 | class Solution { |
上述代码中的解题思路比较特殊,利用循环消去匹配括号的方法。虽然思路比较巧妙,但是运行效果却没下面 Python 的方法好。
Python代码1
2
3
4
5
6
7
8
9
10class Solution:
def isValid(self, s: str) -> bool:
stack = []
paren_map = {'(':')', '{':'}', '[':']'}
for c in s:
if c in paren_map.keys():
stack.append(c)
elif stack == [] or paren_map[stack.pop()] != c:
return False
return not stack
总结:在 LeetCode 上写了好久这段代码都没有通过,也不是思路问题,原因在于 stack == [] 这句话(判断栈是否为空),之前错误的方式是 stack is [] ,原因在于在 Python 语言中 == 判断值是否相等, is 判断 id 是否相等,两者是有本质区别的。
问题二 用栈实现队列(232)
问题描述
使用栈实现队列的下列操作:
- push(x) – 将一个元素放入队列的尾部。
- pop() – 从队列首部移除元素。
- peek() – 返回队列首部的元素。
- empty() – 返回队列是否为空。
示例:
MyQueue queue = new MyQueue();
queue.push(1);
queue.push(2);
queue.peek(); // 返回 1
queue.pop(); // 返回 1
queue.empty(); // 返回 false
说明:
- 你只能使用标准的栈操作 – 也就是只有
push to top,peek/pop from top,size, 和is empty操作是合法的。 - 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
- 假设所有操作都是有效的 (例如,一个空的队列不会调用 pop 或者 peek 操作)。
解题思路分析
利用两个栈解题,一个进栈一个出栈,元素只能从进栈进入,从出栈出去。
解法代码
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46class MyQueue {
Stack<Integer> stack_in = null;
Stack<Integer> stack_out = null;
/** Initialize your data structure here. */
public MyQueue() {
this.stack_in = new Stack();
this.stack_out = new Stack();
}
/** Push element x to the back of queue. */
public void push(int x) {
stack_in.push(x);
}
/** Removes the element from in front of queue and returns that element. */
public int pop() {
if(!stack_out.empty())
return stack_out.pop();
else if(!stack_in.empty()){
while(!stack_in.empty())
stack_out.push(stack_in.pop());
return stack_out.pop();
}
return Integer.MIN_VALUE;
}
/** Get the front element. */
public int peek() {
if(!stack_out.empty())
return stack_out.peek();
else if(!stack_in.empty()){
while(!stack_in.empty())
stack_out.push(stack_in.pop());
return stack_out.peek();
}
return Integer.MIN_VALUE;
}
/** Returns whether the queue is empty. */
public boolean empty() {
if(stack_in.empty() && stack_out.empty())
return true;
else return false;
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47class MyQueue:
def __init__(self):
"""
Initialize your data structure here.
"""
self.stack_in = []
self.stack_out = []
def push(self, x: int) -> None:
"""
Push element x to the back of queue.
"""
self.stack_in.append(x)
def pop(self) -> int:
"""
Removes the element from in front of queue and returns that element.
"""
if self.stack_out:
return self.stack_out.pop()
elif self.stack_in:
while self.stack_in:
self.stack_out.append(self.stack_in.pop())
return self.stack_out.pop()
else: return None
def peek(self) -> int:
"""
Get the front element.
"""
if self.stack_out:
return self.stack_out[-1]
elif self.stack_in:
while self.stack_in:
self.stack_out.append(self.stack_in.pop())
return self.stack_out[-1]
else: return None
def empty(self) -> bool:
"""
Returns whether the queue is empty.
"""
if not self.stack_in and not self.stack_out:
return True
else:
return False
问题三 用队列实现栈(225)
问题描述
使用队列实现栈的下列操作:
- push(x) – 元素 x 入栈
- pop() – 移除栈顶元素
- top() – 获取栈顶元素
- empty() – 返回栈是否为空
注意:
- 你只能使用队列的基本操作– 也就是 push to back, peek/pop from front, size, 和 is empty 这些操作是合法的。
- 你所使用的语言也许不支持队列。 你可以使用 list 或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
- 你可以假设所有操作都是有效的(例如, 对一个空的栈不会调用 pop 或者 top 操作)。
解题思路分析
利用两个队列解题,一个进队列一个出队列,元素只能从进队列进入,从出队列出去。
解法代码
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36class MyStack {
Queue<Integer> qIn = null;
Queue<Integer> qOut = null;
/** Initialize your data structure here. */
public MyStack() {
this.qIn = new LinkedList();
this.qOut = new LinkedList();
}
/** Push element x onto stack. */
public void push(int x) {
qIn.offer(x);
while(!qOut.isEmpty())
qIn.offer(qOut.poll());
Queue temp = qIn;
qIn = qOut;
qOut = temp;
}
/** Removes the element on top of the stack and returns that element. */
public int pop() {
return qOut.poll();
}
/** Get the top element. */
public int top() {
return qOut.peek();
}
/** Returns whether the stack is empty. */
public boolean empty() {
return qOut.isEmpty();
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31class MyStack:
def __init__(self):
"""
Initialize your data structure here.
"""
self.queue = []
def push(self, x: int) -> None:
"""
Push element x onto stack.
"""
self.queue.append(x)
def pop(self) -> int:
"""
Removes the element on top of the stack and returns that element.
"""
return self.queue.pop()
def top(self) -> int:
"""
Get the top element.
"""
return self.queue[-1]
def empty(self) -> bool:
"""
Returns whether the stack is empty.
"""
return not self.queue
1 | class MyStack: |
总结:Python 的第一段代码非常简洁,使用了双端队列 deque ,这种数据结构本身即可以做栈也可以作为队列使用。当然链表 list 也是一样,这样写总觉得不符合题目的要求,所以用与 Java 不一样的思路重新写了代码二(有点复杂)。
优先队列(PriorityQueue)
PriorityQueue - 优先队列:正常⼊、按照优先级出
- Heap (Binary, Binomial, Fibonacci)
- Binary Search Tree
Heap
Mini Heap
Max Heap
复杂度分析

代码实战
问题一 数据流中的第K大元素(703)
问题描述
设计一个找到数据流中第K大元素的类 class。注意是排序后的第 K 大元素,不是第 K 个不同的元素。
你的 KthLargest 类需要一个同时接收整数 k 和整数数组 nums 的构造器,它包含数据流中的初始元素。每次调用 KthLargest.add,返回当前数据流中第 K 大的元素。
示例:
int k = 3;
int[] arr = [4,5,8,2];
KthLargest kthLargest = new KthLargest(3, arr);
kthLargest.add(3); // returns 4
kthLargest.add(5); // returns 5
kthLargest.add(10); // returns 5
kthLargest.add(9); // returns 8
kthLargest.add(4); // returns 8
说明:
你可以假设 nums 的长度 ≥ k-1 且 k ≥ 1 。
解题思路分析
利用小顶堆维护一个优先队列,始终保持堆里的元素为 k 个,那么对顶的元素即为第 k 大元素。
解法代码
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class KthLargest {
final PriorityQueue<Integer> q;
final int k;
public KthLargest(int k, int[] nums) {
this.k = k;
this.q = new PriorityQueue<Integer>();
for(int n: nums)
add(n);
}
public int add(int val) {
if(q.size() < k)
q.offer(val);
else if(q.peek() < val){
q.poll();
q.offer(val);
}
return q.peek();
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class KthLargest:
def __init__(self, k: int, nums: List[int]):
self.k = k
self.heap = []
for num in nums:
heapq.heappush(self.heap, num)
while len(self.heap) > k:
heapq.heappop(self.heap)
def add(self, val: int) -> int:
if len(self.heap) < self.k:
heapq.heappush(self.heap, val)
elif val > self.heap[0]:
heapq.heappop(self.heap)
heapq.heappush(self.heap, val)
return self.heap[0]
总结:Java 代码的 PriorityQueue 和 Python 代码的 heapq 都是构造的小根堆,利用小根堆首先弹出最小元素解题。
问题二 滑动窗口最大值(239)
问题描述
给定一个数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口 k 内的数字。滑动窗口每次只向右移动一位。
返回滑动窗口最大值。
示例:
输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3
输出: [3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7
解题思路分析
解法代码
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if(nums.length == 0 || k==0)
return new int[0];
PriorityQueue<Integer> max_heap = new PriorityQueue<>((a,b)->b-a);
for(int i=0; i<k; i++)
max_heap.add(nums[i]);
int[] res = new int[nums.length-k+1];
int j = 0;
res[j++] = max_heap.peek();
for(int i=k; i<nums.length; i++){
max_heap.remove(nums[i-k]);
max_heap.add(nums[i]);
res[j++] = max_heap.peek();
}
return res;
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11
12
13class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
if not nums: return []
window, res = [], []
for i, x in enumerate(nums):
if i >= k and window[0] <= i-k:
window.pop(0)
while window and nums[window[-1]] <= x:
window.pop(-1)
window.append(i)
if i >= k-1:
res.append(nums[window[0]])
return res
总结:Python 解题的代码方法与 Java 思路有所不同,Java 代码维护了一个大小为 k 的大顶堆,思路比较清晰。而 Python 用了更加简单的数据结构——队列或栈,时间复杂度更低,为 O(n) 。
问题三 前K个高频单词(692)
问题描述
给一非空的单词列表,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字母顺序排序。
示例 1:
输入: [“i”, “love”, “leetcode”, “i”, “love”, “coding”], k = 2
输出: [“i”, “love”]
解析: “i” 和 “love” 为出现次数最多的两个单词,均为2次。
注意,按字母顺序 “i” 在 “love” 之前。
示例 2:
输入: [“the”, “day”, “is”, “sunny”, “the”, “the”, “the”, “sunny”, “is”, “is”], k = 4
输出: [“the”, “is”, “sunny”, “day”]
解析: “the”, “is”, “sunny” 和 “day” 是出现次数最多的四个单词,
出现次数依次为 4, 3, 2 和 1 次。
注意:
- 假定 k 总为有效值, 1 ≤ k ≤ 集合元素数。
- 输入的单词均由小写字母组成。
解题思路分析
- 方法一:利用优先队列
- 方法二:利排序
解法代码
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Solution {
public List<String> topKFrequent(String[] words, int k) {
HashMap<String, Integer> map = new HashMap();
for (String word: words) {
map.put(word, map.getOrDefault(word,0)+1);
}
PriorityQueue<String> q = new PriorityQueue(new Comparator<String>(){
public int compare(String a, String b) {
if (map.get(a) == map.get(b))
return a.compareTo(b);
return map.get(b)-map.get(a);
}
});
for (String word:map.keySet())
q.add(word);
List<String> res = new ArrayList();
for (int i=0; i<k; i++)
res.add(q.poll());
return res;
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11
12
13class Solution:
def topKFrequent(self, words: List[str], k: int) -> List[str]:
dic = {}
for word in words:
if word in dic:
dic[word] += 1
else:
dic[word] = 1
dic = sorted(dic.items(), key=lambda item:(-item[1],item[0]))
res = []
for i in range(k):
res.append(dic[i][0])
return res
总结:Java 代码先利用哈希 Map 存储单词及词频,在利用优先队列对元素进行排序,最后将结果写入一个数组,解题的关键在于优先队列中构造的比较器 ;Python 代码利用 sorted 函数直接将词频字典进行排序,这里不得不感慨 Python 代码的简洁,排序功能强大有没有!
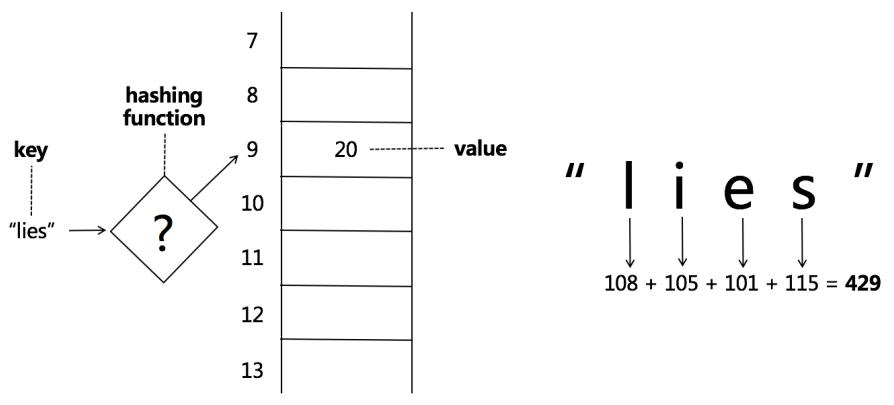
哈希表(HashTable) & 集合(Set)
- 哈希函数:Hash Function
- 哈希碰撞:Hash Collisions
Hash Function
Hash Collisions

HashMap best practices
HashSet best practices

代码实战
问题一 有效的字母异位词(242)
问题描述
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的一个字母异位词。
示例 1:
输入: s = “anagram”, t = “nagaram”
输出: true
示例 2:
输入: s = “rat”, t = “car”
输出: false
说明:
你可以假设字符串只包含小写字母。
解题思路分析
- 方法一,利用排序
- 方法二,Map 计数 {letter:count}
解法一:利用排序
Java代码1
2
3
4
5
6
7
8
9
10
11class Solution {
public boolean isAnagram(String s, String t) {
if(s.length()!=t.length())
return false;
char[] as = s.toCharArray();
char[] ts = t.toCharArray();
Arrays.sort(as);
Arrays.sort(ts);
return Arrays.equals(as, ts);
}
}
Python代码1
2
3class Solution:
def isAnagram(self, s: str, t: str) -> bool:
return sorted(s) == sorted(t)
总结:Python 排序的代码非常简洁,但是这种方法时间复杂度比 解法二 要高。
解法二:利用 Map
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution {
public boolean isAnagram(String s, String t) {
Map<Character, Integer> map_s = new HashMap();
Map<Character, Integer> map_t = new HashMap();
for(char item : s.toCharArray()){
if(map_s.get(item) == null)
map_s.put(item, 1);
else
map_s.put(item, map_s.get(item)+1);
}
for(char item : t.toCharArray()){
if(map_t.get(item) == null)
map_t.put(item, 1);
else
map_t.put(item, map_t.get(item)+1);
}
return map_s.equals(map_t);
}
}
Python代码1
2
3
4
5
6
7
8class Solution:
def isAnagram(self, s: str, t: str) -> bool:
dic_s, dic_t = {}, {}
for item in s:
dic_s[item] = dic_s.get(item, 0) +1
for item in t:
dic_t[item] = dic_t.get(item, 0) +1
return dic_s == dic_t
1 | class Solution: |
总结:这里 Python 的代码写了两种方式,前者使用字典,后者使用链表,解题思路是一致的,只不过后者使用链表利用下标构造了一个字典。从运行时间来看,后者优于前者。
问题二 两数之和(1)
问题描述
给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,你不能重复利用这个数组中同样的元素。
示例:
给定 nums = [2, 7, 11, 15], target = 9
因为 nums[0] + nums[1] = 2 + 7 = 9
所以返回 [0, 1]
解题思路分析
- 方法一,暴力解法:两层嵌套循环,例举所有可能的情况
- 方法二,利用 Set,判断 9-x 是否在 Set 中
解法代码
Java代码1
2
3
4
5
6
7
8
9class Solution {
public int[] twoSum(int[] nums, int target) {
for(int i=0; i<nums.length -1; i++)
for(int j=i+1; j<nums.length; j++)
if(nums[i] + nums[j] == target)
return new int[] {i, j};
return new int[0];
}
}
Python代码1
2
3
4
5
6
7class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
hash_map = dict()
for i, x in enumerate(nums):
if target - x in hash_map:
return [i, hash_map[target - x]]
hash_map[x] = i
总结:Java 代码使用的是 方法一 暴力解法,Python 代码使用的 方法二。
问题三 三数之和(15)
问题描述
给定一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?找出所有满足条件且不重复的三元组。
注意:答案中不可以包含重复的三元组。
例如, 给定数组 nums = [-1, 0, 1, 2, -1, -4],
满足要求的三元组集合为:
[
[-1, 0, 1],
[-1, -1, 2]
]
解题思路分析
- 方法一,暴力解题:三重循环,时间复杂度 $O(N^3)$
- 方法二,利用
Set:枚举a和b,c = -(a+b),将所有元素放入Set,查询c是否在Set内。时间负载度 $O(N^2)$,空间复杂度 $O(N)$。 - 方法三,先排序再查找:数组从小到大排序,顺序枚举
a,右侧剩下的数组查找bc,b从左侧向右,c从右侧向左,若a+b+c > 0移动 c ,若a+b+c < 0移动b,直到a+b+c = 0。
解法一:利用集合
Java代码1
2
Python代码1
2
解法二:先排序再查找
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33class Solution {
public List<List<Integer>> threeSum(int[] nums) {
Arrays.sort(nums);
List<List<Integer>> res = new ArrayList();
for (int i=0; i<nums.length-2; i++) {
if (i>0 && nums[i] == nums[i-1]) continue;
int low = i+1;
int high = nums.length - 1;
while(low<high) {
if (nums[i] + nums[low] + nums[high] > 0) {
high -= 1;
while(nums[high]==nums[high+1] && low<high) high--;
}
else if (nums[i] + nums[low] + nums[high] < 0) {
low += 1;
while(nums[low]==nums[low-1] && low<high) low++;
}
else {
List<Integer> temp = new ArrayList();
temp.add(nums[i]);
temp.add(nums[low]);
temp.add(nums[high]);
res.add(temp);
low += 1;
while(nums[low]==nums[low-1] && low<high) low++;
high -= 1;
while(nums[high]==nums[high+1] && low<high) high--;
}
}
}
return res;
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
nums.sort()
res = []
for i in range(len(nums)-2):
if i>0 and nums[i]==nums[i-1]: continue
low, high = i+1, len(nums)-1
while low<high:
if nums[i] + nums[low] + nums[high] < 0:
low += 1
elif nums[i] + nums[low] + nums[high] > 0:
high -= 1
else :
res.append([nums[i],nums[low],nums[high]])
low += 1
high -= 1
while low<high and nums[low]==nums[low-1]: low += 1
while low<high and nums[high]==nums[high+1]: high -= 1
return res
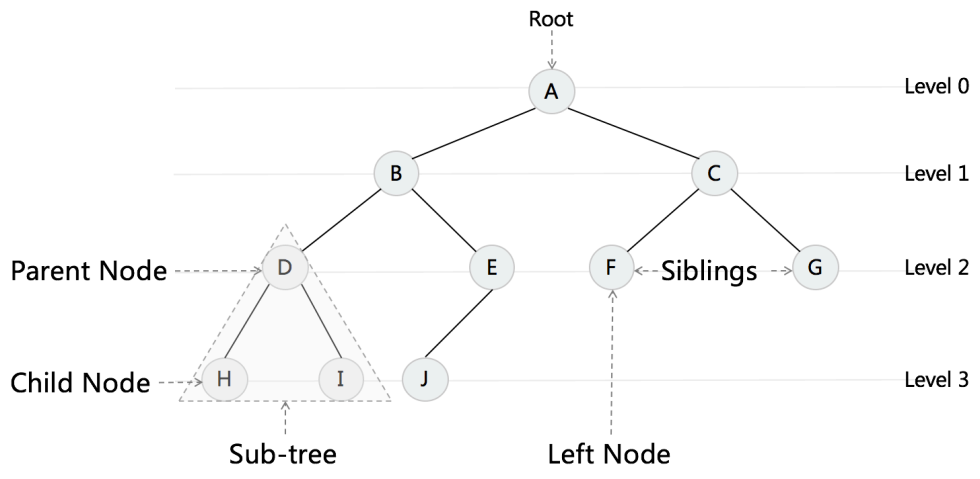
树与图
- Tree, Binary Tree, Binary Search Tree
- Graph
树、⼆叉树、⼆叉搜索树
Tree
Binary Tree
Binary Search Tree
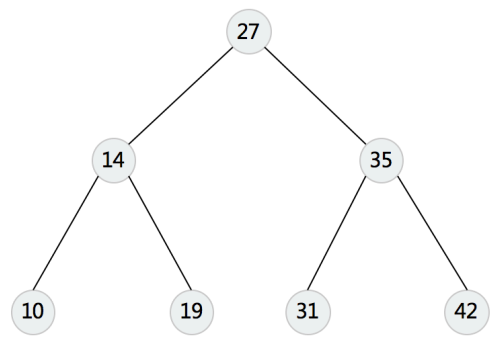
⼆叉搜索树(英语:Binary Search Tree),也称⼆叉搜索树、有序⼆叉树(英语:ordered binary tree),排序⼆叉树(英语:sorted binary tree),是指⼀棵空树或者具有下列性质的⼆叉树:
- 若任意节点的左⼦树不空,则左⼦树上所有结点的值均⼩于它的根结点的值;
- 若任意节点的右⼦树不空,则右⼦树上所有结点的值均⼤于它的根结点的值;
- 任意节点的左、右⼦树也分别为⼆叉查找树。
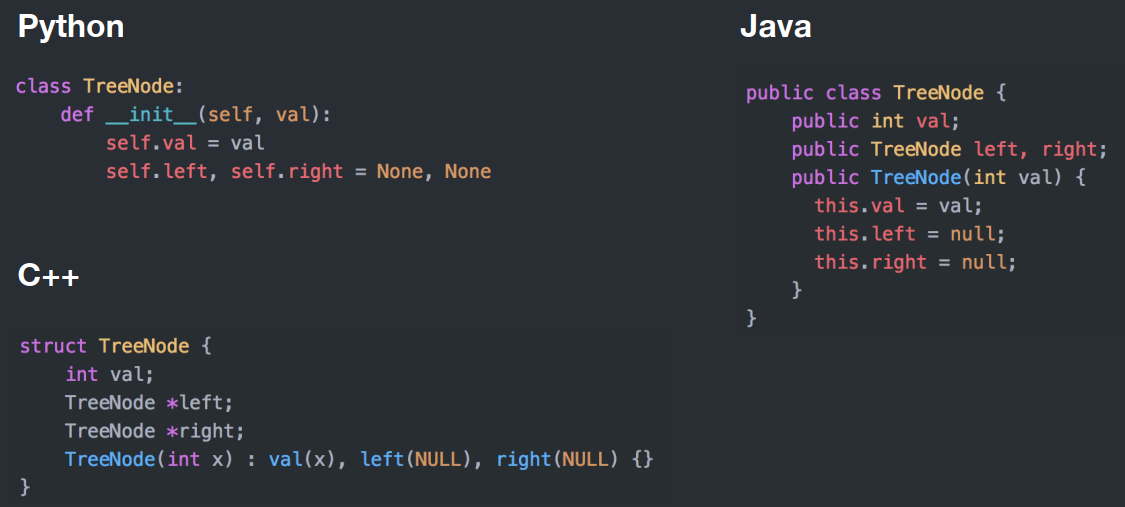
树结构在不同语言中的定义
图
Graph
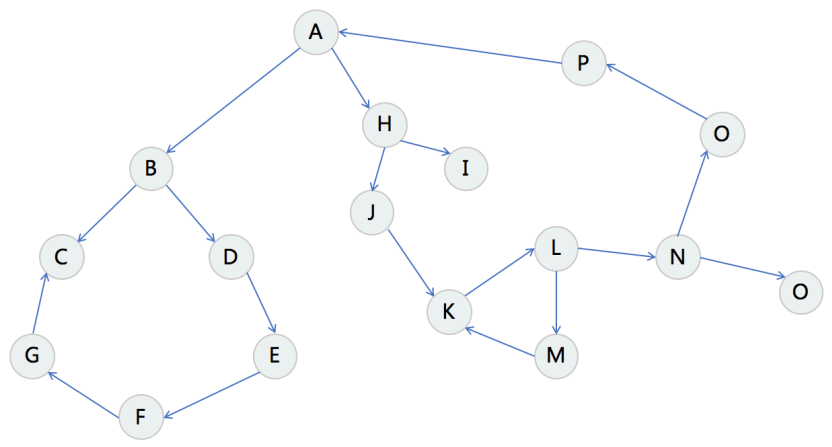
Linked List 就是特殊化的 Tree,Tree 就是特殊化的 Graph 。
代码实战
问题一 验证二叉搜索树(98)
问题描述
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
假设一个二叉搜索树具有如下特征:
- 节点的左子树只包含小于当前节点的数。
- 节点的右子树只包含大于当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:
输入:
输出: true

示例 2:
输入:
输出: false
解释: 输入为: [5, 1, 4, null, null, 3, 6]。
根节点的值为 5 ,但是其右子节点值为 4 。

解题思路分析
- 方法一,中序遍历:
判断输出队列是否为升序(遍历过程中判断后续节点大于前继节点)。 - 方法二,利用递归:
注意递归函数需要返回两个值min和max, 递归调用左孩子返回max,递归调用右孩子返回min,判断max < root,min > root。
解法代码
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
double last = -Double.MAX_VALUE;
public boolean isValidBST(TreeNode root) {
if(root == null) return true;
if(isValidBST(root.left)){
if(last < root.val){
last = root.val;
return isValidBST(root.right);
}
}
return false;
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def isValidBST(self, root: TreeNode) -> bool:
inorder = self.inorder(root)
return inorder == list(sorted(set(inorder)))
def inorder(self, root):
if root is None:
return []
return self.inorder(root.left) + [root.val] + self.inorder(root.right)
1 | class Solution: |
总结:Python 的第一段代码采用中序遍历树方法,然后判断遍历结果是否有序,但是要注意,该方法需要利用集合的不重复元素的特性,过滤掉重复的节点。第二段代码利用递归的思想。
问题二 二叉搜索树的最近公共祖先(235)
问题描述
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“ 对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6, 2, 8, 0, 4, 7, 9, null, null, 3, 5]
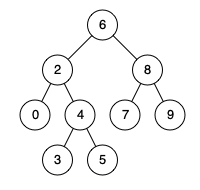
示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输出: 6
解释: 节点 2 和节点 8 的最近公共祖先是 6
示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
输出: 2
解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
说明:
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉搜索树中。
解题思路分析
- 方法一,父节点路径:
p、q节点分别找父节点直至根节点,得到两条路径,两条路径最早出现的公共节点即为所求。 - 方法二,子节点路径:
从根节点开始找目标节点路径,两条路径的最后一个公共节点即为所求。 - 方法三,Recursion:
利用辅助函数 findPorQ(root, p, q)
解法代码
Java代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root == null || root == p || root == q) return root;
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
return left == null ? right : right == null ? left : root;
}
}
Python代码1
2
3
4
5
6
7
8
9
10
11
12
13
14# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
if p.val < root.val > q.val:
return self.lowestCommonAncestor(root.left, p, q)
if p.val > root.val < q.val:
return self.lowestCommonAncestor(root.right, p, q)
return root
1 | class Solution: |
总结:Python 的第二段代码思路与第一段一样,不同点在于第二段代码将第一段代码的递归改写成了循环形式,效率提高了很多。另外需要注意,Java 代码的递归适用于所有的树形结构(具有普遍性),而 Python 的代码仅仅针对二叉搜索树而言。
二叉树的遍历
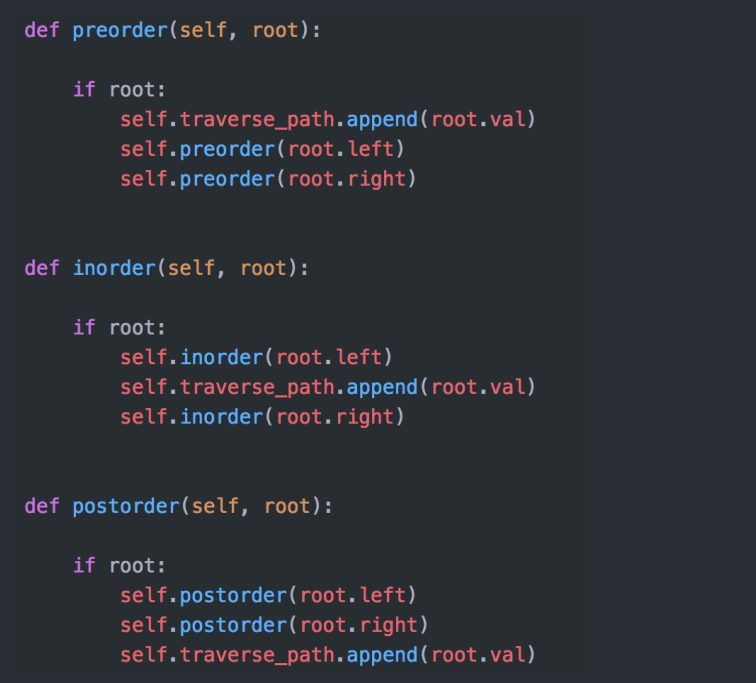
- Pre-order:前序,根-左-右
- In-order:中序,左-根-右
- Post-order:后序,左-右-根
Pre-order Traversal
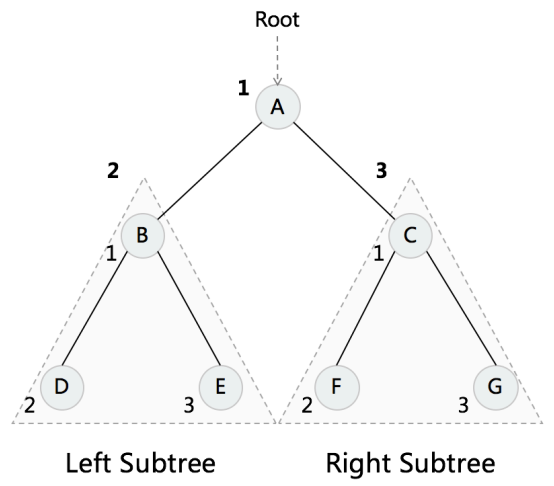
In-order Traversal
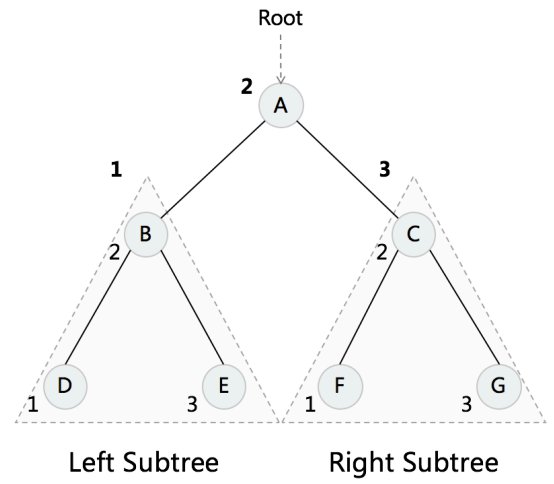
Post-order Traversal
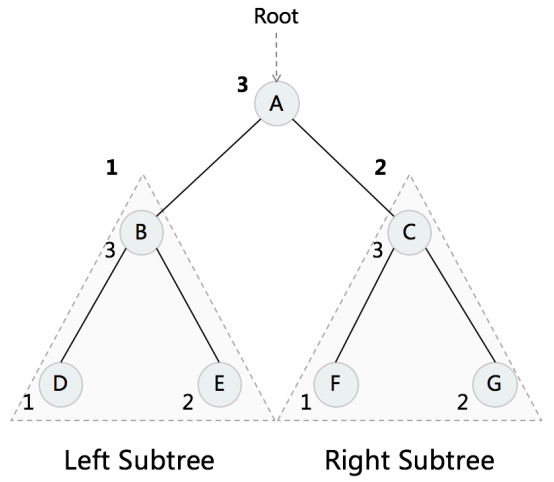
代码实现