强化学习概述
强化学习模型分类
通过价值选行为:
- Q learning
- Sarsa
- Deep Q Network
直接选行为:
- Policy Gradients
想象环境并从中学习:
- Model based RL
强化学习方法
不理解环境(Model-Free) vs 理解环境(Model-Based)
不理解环境
- Q Learning
- Sarsa
- Policy Gradients
基于概率(Policy-Based) vs 基于价值(Value-Based)
基于概率
- Policy Gradients
基于价值
- Q Learning
- Sarsa
两者结合
- Actor-Critic
回合更新(Monte-Carlo update) vs 单步更新(Temporal-Difference update)
回合更新
- Monte-Carlo Learning
- 基础版的 Policy Gradients
单步更新
- Qlearning, Sarsa
- 升级版的 Policy Gradients
在线学习(On-Policy) vs 离线学习(Off-Policy)
在线学习
- Sarsa
- Sarsa lambda
离线学习
- Q Learning
- Deep Q Network
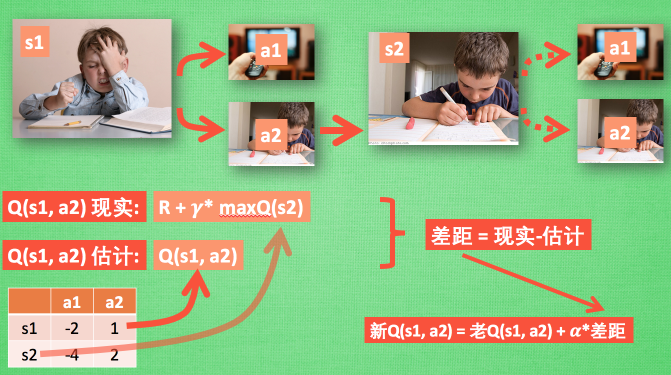
Q Learning
行为准则

决策

更新
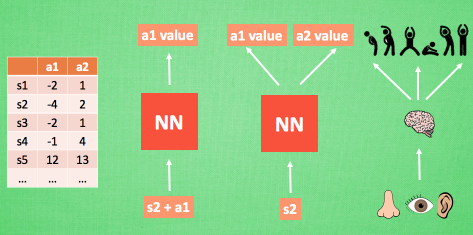
算法

Sarsa
决策
Sarsa 的决策部分和 Q learning 一模一样, 因为我们使用的是 Q 表的形式决策, 所以我们会在 Q 表中挑选值较大的动作值施加在环境中来换取奖惩. 但是不同的地方在于 Sarsa 的更新方式是不一样的.
更新行为准则
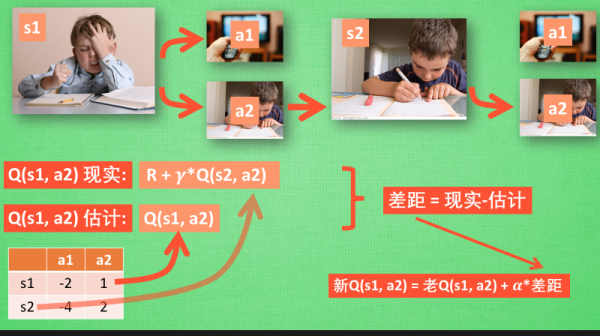
对比 Sarsa 和 Q-learning 算法

DQN
什么是 DQN
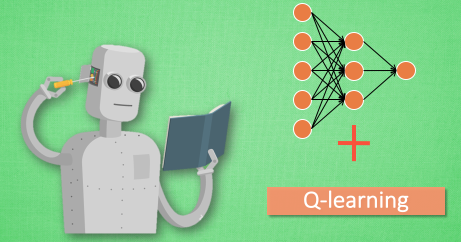
DQN = DNN + Q Learning,一种融合了神经网络和 Q learning 的方法, 名字叫做 Deep Q Network。