LeNET-5模型
简介
LeNet-5 出自论文 Gradient-Based Learning Applied to Document Recognition,是一种用于手写体字符识别的非常高效的卷积神经网络。
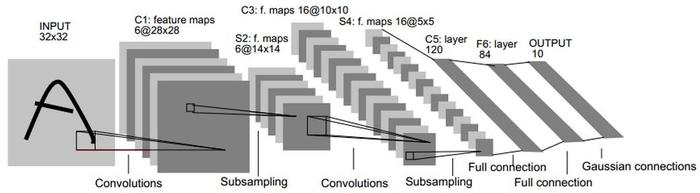
下面的代码根据 LeNET-5 模型结构在每层卷积层的卷积核数量上做了相应调整,以 MNIST 数据集为例展示了 LeNET-5 在 Tensorflow 框架下的手写数字体识别。
模型代码 Tensorflow
1 | import tensorflow as tf |
AlexNet模型
简介
AlexNet 是2012年 ImageNet 竞赛冠军获得者 Hinton 和他的学生 Alex Krizhevsky 设计的。也是在那年之后,更多的更深的神经网路被提出,比如优秀的 VGG, GoogLeNet。
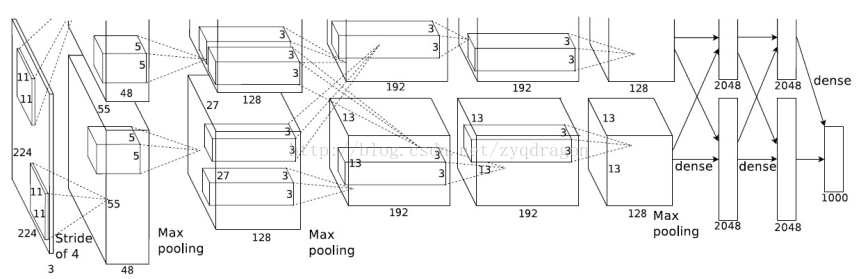
模型代码 tensorflow.contrib.slim
1 | import tensorflow.contrib.slim as slim |
VGG16模型
简介
在 2014 年提出来的模型。当这个模型被提出时,由于它的简洁性和实用性,马上成为了当时最流行的卷积神经网络模型。它在图像分类和目标检测任务中都表现出非常好的结果。在 2014 年的 ILSVRC 比赛中,VGG 在 Top-5 中取得了 92.3% 的正确率。
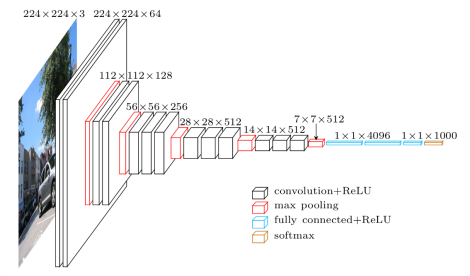
模型代码 Tensorflow
1 | import tensorflow as tf |
模型代码 Keras
1 | from keras import Sequential |
Keras.application中的VGG16模型
VGG16模型的权重由ImageNet训练而来。该模型在Theano和TensorFlow后端均可使用,并接受channels_first和channels_last两种输入维度顺序,模型的默认输入尺寸是224x224。
1 | import keras |
参数说明
- include_top:是否保留顶层的3个全连接网络
- weights:None代表随机初始化,即不加载预训练权重。’imagenet’代表加载预训练权重
- input_tensor:可填入Keras tensor作为模型的图像输出tensor
- input_shape:可选,仅当include_top=False有效,应为长为3的tuple,指明输入图片的shape,图片的宽高必须大于48,如(200,200,3)
返回值
- pooling:当include_top=False时,该参数指定了池化方式。None代表不池化,最后一个卷积层的输出为4D张量。‘avg’代表全局平均池化,‘max’代表全局最大值池化。
- classes:可选,图片分类的类别数,仅当include_top=True并且不加载预训练权重时可用。
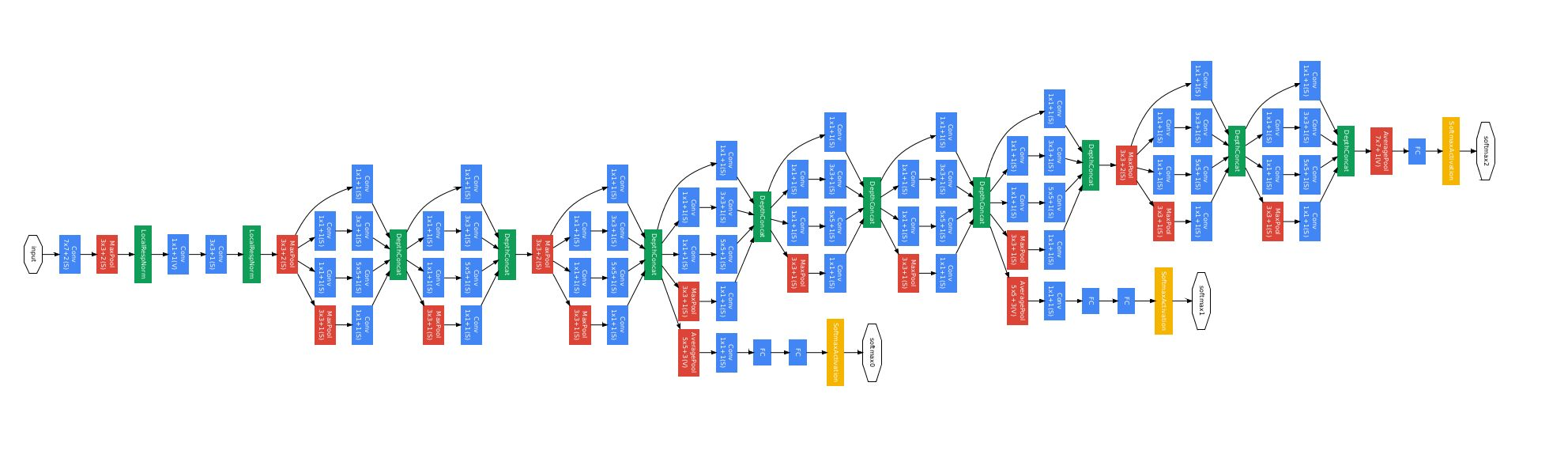
GoogleNet/Inception