基础
创建常量
1 | # 创建一个(1,2)维常量 |
定义变量
1 | # 定义一个(2,)形状的变量 |
运算
基本运算
1 | # 矩阵乘法op,m1,m2为可相乘的张量,product为结果张量 |
逻辑运算
1 | # 返回input在axis所在维度上的最大值坐标 |
所有变量初始化
1 | # 在会话中必须要执行的第一步 |
创建会话
1 | ## 第一种方式 |
Fetch & Feed
Fetch: 可以在session中同时计算多个tensor或执行多个操作1
2
3
4
5
6
7
8
9
10
11
12# 定义三个常量
input1 = tf.constant(3.0)
input2 = tf.constant(2.0)
input3 = tf.constant(5.0)
# 加法op
add = tf.add(input2,input3)
# 乘法op
mul = tf.multiply(input1, add)
with tf.Session() as sess:
result1, result2 = sess.run([mul, add])
print(result1,result2)
Feed: 先定义占位符,等需要的时候再传入数据1
2
3
4
5
6
7
8# 定义两个tensor,不传入数据
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
# 乘法op
output = tf.multiply(input1, input2)
with tf.Session() as sess:
print(sess.run(output, feed_dict={input1:8.0,input2:2.0}))
神经网络
变量初始化器
随机数生成函数
- tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32)
- tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32)
- tf.random_uniform(shape, minval=0, maxval=None, dtype=tf.float32)
- tf.random_gamma(shape, alpha, beta=None, dtype=tf.float32)
与 tf.Variable() 配合使用
变量初始化函数
- tf.constant_initializer(value=0, dtype=tf.float32)
- tf.random_normal_initializer(mean=0.0, stddev=1.0, dtype=tf.float32)
- tf.truncated_normal_initializer(mean=0.0, stddev=1.0, dtype=tf.float32)
- tf.random_uniform_initializer(minval=0, maxval=None, dtype=tf.float32)
- tf.ones_initializer()
- tf.zeros_initializer()
与 tf.get_variable() 配合使用
常数生成函数
- tf.ones(shape, dtype=tf.float32)
- tf.zeros(shape, dtype=tf.float32)
- tf.fill(dims, value)
- tf.constant(value, dtype=None, shape=None)
1 | # 生成全1张量,shape为张量形状 |
以函数的形式定义变量的初始化1
2
3def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1) # 生成一个截断的正态分布
return tf.Variable(initial)
激活函数
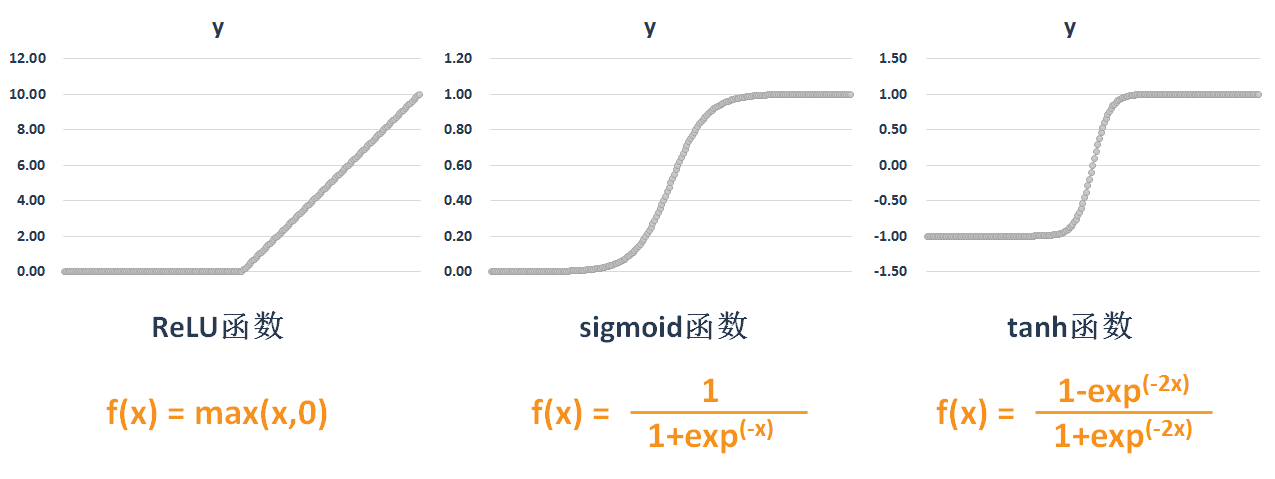
1 | # tensor为需要激活的神经元 |
损失函数
1 | # 二次代价函数,y_actual为真实值,y_predict为预测值 |
防止过拟合
Dropout
1 | # 定义L1层神经元按比例失活,失活比例为keep_prob |
keep_prob建议使用占位符方式传入
正则化
1 | # L1正则项损失 |
由于偏置项b较权重W而言,参数少很多,在计算正则化时可以不予考虑
优化器
优化器列表
- tf.train.GradientDescentOptimizer
- tf.train.AdadeltaOptimizer
- tf.train.AdagradOptimizer
- tf.train.AdagradDAOptimizer
- tf.train.MomentumOptimizer
- tf.train.FtrlOptimizer
- tf.train.ProximalGradientDescentOptimizer
- tf.train.ProximalAdagradOptimizer
- tf.train.RMSPropOptimizer
1 | # 定义一个梯度下降法优化器,η为学习率,一般取值0.01 |
一般情况下Adam优化器比梯度下降优化器的学习率取值小,Adam优化器也是一个整体性能较优的优化器,如果不知道如何选择优化器,可以首先考虑Adam
其他优化器
1 | optimizer = tf.train.GradientDescentOptimizer(η) |
图片预处理
图像解码
在图片预处理之前,需要将图片读取为张量的形式1
2
3
4
5
6# 读取图片,其中filename为图片完整路径
image = tf.read_file(filename)
# 效果同上
image = tf.gfile.FastGFile(filename, 'rb').read()
# 将图像解码,或者tf.image.decode_png
image = tf.image.decode_jpeg(image, channels=3)
注:解码函数根据图像格式的选取有所不同
读取图片为张量后,将其数值进行调整1
2
3
4
5
6# 将 0~255 的像素转化为 0.0~1.0 范围内的实数
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
# 下述三步骤同上述步骤效果
image = tf.cast(image, tf.float32) / 255.0
image = tf.subtract(image, 0.5)
image = tf.multiply(image, 2.0)
图像大小调整
1 | # 调整图像大小,method有四中模式,可取值0,1,2,3 |
图像大小调整 tensorflow.image.resize_images 提供四种模式选择
- 0:双线性插值
- 1:最近邻居法
- 2:双三次插值法
- 3:面积插值法
先看原始图片:
各种方法的对比结果:
1 | # 通过tf.image.resize_image_with_crop_or_pad函数调整图像大小 |
该函数有三个参数,images 表示原始图像,target_height 表示调整后目标图像高度,target_width 表示调整后目标图像宽度。如果原始图像尺寸大于目标图像,那么这个函数会自动截取原始图像居中的部分;反之,函数会自动在原始图像的四周填充全0背景。
输出结果:
图像裁减
1 | 通过tf.image.central_crop函数按比例裁减图像 |
该函数有两个参数,images 表示原始图像,central_fraction 表示调整比例。按比例裁减图像,参数 central_fraction 是一个介于 (0,1] 之间的实数,该函数也是自动截取中心部分。
输出结果:

1 | # 通过tf.image.crop_to_bounding_box裁减图像 |
上述两个函数五参数相同,分别为:images 表示原始图像,offset_height 表示距离上边高度,offset_width 表示距离左边宽度,target_height 表示目标图像高度,target_width 表示目标图像宽度。
crop_to_bounding_box 要求原始图像尺寸大于目标图像, pad_to_bounding_box 要求原始图像尺寸小于目标图像,并按照 offset_h / offset_w 的值截取或填充原始图像。
输出结果:

图片翻转
1 | # 上下翻转 |
在很多图像识别问题中,图像的翻转不应该影响识别的结果。于是在训练神经网络模型时,可随机翻转训练图像,这样训练得到的模型可以识别不同角度的实体。
输出结果:

图片色彩调整
亮度
1 | # 将图像亮度-0.5,并截断取值之0~1之间 |
函数 tf.image.adjust_brightness 包含两个参数, images 表示原始图像, delta 表示亮度大小。 delta 绝对值的范围应该在 [0,1) 之内色彩调整的API可能导致像素的实数值超出 0~1 的范围,所以要用上述第二个函数,将取值截断。否则不仅图像无法可视化,输入的神经网络训练质量也会受到影响。

对比度
1 | # 将图像的对比度减少到0.5倍或增加5倍 |
函数 tf.image.adjust_contrast 包含两个参数, images 表示原始图像, contrast_factor 表示对比度调整参数。
对比度的调整,官方文档解释如下:
For each channel, this Op computes the mean of the image pixels in the channel and then adjusts each component x of each pixel to (x - mean) * contrast_factor + mean
输出结果:

色相
1 | # 将图像的色相相加一个值,调整值在[-1, 1]之间 |
函数 tf.image.adjust_hue 包含两个参数, images 表示原始图像, delta 表示增加的色相大小。
色相的调整,官方文档解释如下:
image is an RGB image. The image hue is adjusted by converting the image to HSV and rotating the hue channel (H) by delta. The image is then converted back to RGB.
输出结果:

饱和度
1 | # 将图像的饱和度-5或+5 |
函数 tf.image.adjust_saturation 包含两个参数, images 表示原始图像, saturation_factor 表示饱和度调整参数。
饱和度的调整,官方文档解释如下:
image is an RGB image. The image saturation is adjusted by converting the image to HSV and multiplying the saturation (S) channel by saturation_factor and clipping. The image is then converted back to RGB.
输出结果:

图像预处理完整样例
1 | import tensorflow as tf |
卷积神经网络 CNN
定义卷积层
1 | # 定义一层卷积层神经网络,input为输入数据,filter为滤波器即权重,strides步长为1,padding可以取'SAME'和'VALID' |
定义池化层
1 | # 定义一层池化层神经网络,value为输入数据,ksize为池化窗口大小,strides步长为2,padding可以取'SAME'和'VALID' |
循环神经网络 RNN
LSTM
1 | # 初始化输出层权值 |
模型的保存与载入
使用tensorflow过程中,训练结束后我们需要用到模型文件。有时候,我们可能也需要用到别人训练好的模型,并在这个基础上再次训练。这时候我们需要掌握如何操作这些模型数据。看完本文,相信你一定会有收获!
Tensorflow模型文件
我们在checkpoint_dir目录下保存的文件结构如下:1
2
3
4
5--checkpoint_dir
| |--checkpoint
| |--MyModel.meta
| |--MyModel.data-00000-of-00001
| |--MyModel.index
meta文件
MyModel.meta文件保存的是图结构,meta文件是pb(protocol buffer)格式文件,包含变量、op、集合等。
ckpt文件
ckpt文件是二进制文件,保存了所有的weights、biases、gradients等变量。在tensorflow 0.11之前,保存在.ckpt文件中。0.11后,通过两个文件保存,如:1
2MyModel.data-00000-of-00001
MyModel.index
checkpoint文件
我们还可以看,checkpoint_dir目录下还有checkpoint文件,该文件是个文本文件,里面记录了保存的最新的checkpoint文件以及其它checkpoint文件列表。在inference时,可以通过修改这个文件,指定使用哪个model。
保存Tensorflow模型
tensorflow 提供了 tf.train.Saver 类来保存模型,值得注意的是,在tensorflow中,变量是存在于Session环境中,也就是说,只有在Session环境下才会存有变量值,因此,保存模型时需要传入session:
1 | saver = tf.train.Saver() |
上面第二句写入会话中,执行后,在checkpoint_dir目录下创建模型文件如下:
1 | checkpoint |
另外,如果想要在1000次迭代后,再保存模型,只需设置global_step参数即可:
1 | saver.save(sess, './checkpoint_dir/MyModel', global_step=1000) |
保存的模型文件名称会在后面加-1000,如下:
1 | checkpoint |
在实际训练中,我们可能会在每1000次迭代中保存一次模型数据,但是由于图是不变的,没必要每次都去保存,可以通过如下方式指定不保存图:
1 | saver.save(sess, './checkpoint_dir/MyModel', global_step=step, write_meta_graph=False) |
另一种比较实用的是,如果你希望每2小时保存一次模型,并且只保存最近的5个模型文件:
1 | tf.train.Saver(max_to_keep=5, keep_checkpoint_every_n_hours=2) |
如果我们不对tf.train.Saver指定任何参数,默认会保存所有变量。如果你不想保存所有变量,而只保存一部分变量,可以通过指定variables/collections。在创建tf.train.Saver实例时,通过将需要保存的变量构造list或者dictionary,传入到Saver中:
1 | w1 = tf.Variable(tf.random_normal(shape=[2]), name='w1') |
导入训练好的模型
在第1小节中我们介绍过,tensorflow将图和变量数据分开保存为不同的文件。因此,在导入模型时,也要分为2步:构造网络图和加载参数
构造网络图
一个比较笨的方法是,手敲代码,实现跟模型一模一样的图结构。其实,我们既然已经保存了图,那就没必要在去手写一次图结构代码。
1 | saver=tf.train.import_meta_graph('./checkpoint_dir/MyModel-1000.meta') |
上面一行代码,就把图加载进来了
加载参数
仅仅有图并没有用,更重要的是,我们需要前面训练好的模型参数(即weights、biases等),本文第2节提到过,变量值需要依赖于Session,因此在加载参数时,先要构造好Session:1
2
3
4
5with tf.Session() as sess:
# 保存模型结构
saver = tf.train.import_meta_graph('./checkpoint_dir/MyModel-1000.meta')
# 加载模型参数
saver.restore(sess,tf.train.latest_checkpoint('./checkpoint_dir'))
使用恢复的模型
前面我们理解了如何保存和恢复模型,很多时候,我们希望使用一些已经训练好的模型,如prediction、fine-tuning以及进一步训练等。这时候,我们可能需要获取训练好的模型中的一些中间结果值,可以通过graph.get_tensor_by_name(‘w1:0’)来获取,注意w1:0是tensor的name。
假设我们有一个简单的网络模型,代码如下:
1 | import tensorflow as tf |
接下来我们使用graph.get_tensor_by_name()方法来操纵这个保存的模型。用graph.get_tensor_by_name()方法来获取之前模型定义的操作。
1 | import tensorflow as tf |
注意:保存模型时,只会保存变量的值,placeholder里面的值不会被保存。若没有./checkpoint_dir/MyModel-1000.meta文件,则需要手动编写模型结构代码。
第二种保存Tensorflow模型方式
模型训练好后,直接在Session的最后写入:1
2
3
4
5
6# 保存模型参数和结构,把变量变成常量
# output_node_names设置可以输出tensor
output_graph_def = tf.graph_util.convert_variables_to_constants(sess, sess.graph_def, output_node_names=['output', 'accuracy'])
# 保存模型到目录的models文件夹
with tf.gfile.FastGFile('pb_models/my_model.pb', mode='wb') as f:
f.write(output_graph_def.SerializeToString())
第二种模型载入方式
1 | # 载入数据集 |
第二种模型载入方式,比较简单,但是由于载入的常量,所以模型只能用于做预测,而不能用来做训练。
