预备知识
本节介绍 word2vec 中将用到的一些重要知识点,包括 sigmoid 函数、Beyes 公式和 Huffman 编码等。
sigmoid 函数
sigmoid 函数是神经网络中常用的激活函数之一,其定义为
$$ \sigma ( x ) = \frac { 1 } { 1 + e ^ { - x } } $$
该函数的定义域为 $( - \infty , + \infty )$,值域为 $( 0,1 )$。下图给出了 sigmoid 函数的图像。
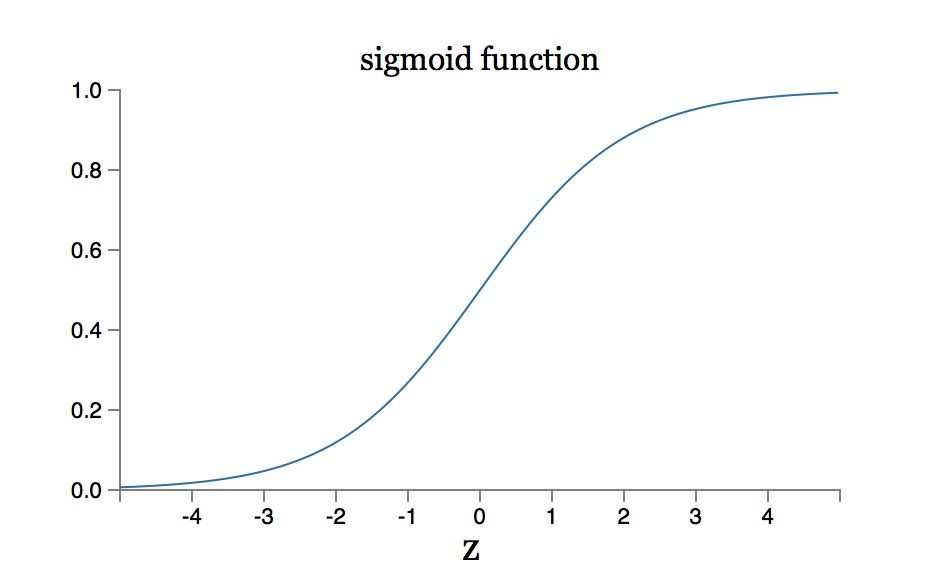
sigmoid 函数的导函数具有以下形式
$$ \sigma ^ { \prime } ( x ) = \sigma ( x ) [ 1 - \sigma ( x ) ] $$
由此易得,函数 $\log \sigma ( x )$ 和 $\log ( 1 - \sigma ( x ) )$ 的导函数分别为:
$$ [ \log \sigma ( x ) ] ^ { \prime } = 1 - \sigma ( x ) , \quad [ \log ( 1 - \sigma ( x ) ) ] ^ { \prime } = - \sigma ( x ) \tag{2.1} $$
公式(2.1) 在后面的推导中将用到。
逻辑回归
生活中经常会碰到二分类问题,例如,某封电子邮件是否为垃圾邮件,某个客户是否为潜在客户,某次在线交易是否存在欺诈行为,等等。设 $ \lbrace \left( \mathrm { x } _ { i } , y _ { i } \right) \rbrace _ { i = 1 } ^ { m } $ 为一个二分类问题的样本数据,其中 $ \mathbf { x } _ { i } \in \mathbb { R } ^ { n } , y _ { i } \in \lbrace 0,1 \rbrace $,当 $y_i = 1$ 时称相应的样本为正例,当 $y_i = 0$ 时称相应的样本为负例。
利用 sigmoid 函数,对于任意样本 $\mathbf { x } = \left( x_1, x_2,\cdots, x_n \right) ^ { \top }$,可将二分类问题的 $hypothesis$ 函数写成
$$h _ { \theta } ( \mathrm { x } ) = \sigma \left( \theta _ { 0 } + \theta _ { 1 } x _ { 1 } + \theta _ { 2 } x _ { 2 } + \cdots + \theta _ { n } x _ { n } \right)$$
其中 $\theta = \left( \theta _ { 0 } , \theta _ { 1 } , \cdots , \theta _ { n } \right) ^ { \top }$ 为待定参数。为了符号上简化起见,引入 $x_0= 1$ 将 $\mathbf { x }$ 扩展为 $\left( x_0, x_1, x_2,\cdots, x_n \right) ^ { \top }$,且在不引起混淆的情况下仍将其记为 $\mathbf { x }$。于是,$h_\theta$ 可简写为
$$h _ { \theta } ( \mathbf { x } ) = \sigma \left( \theta ^ { \top } \mathbf { x } \right) = \frac { 1 } { 1 + e ^ { - \theta ^ { \top } \mathbf { x } } }$$
取阀值 $T = 0.5$,则二分类的判别公式为 $\mathrm { x }$
$$ y ( \mathrm { x } ) = \begin{cases}
1 , & { h_\theta (\mathrm { x }) \geq 0.5 } \\
0 , & { h_\theta (\mathrm { x }) < 0.5 }
\end{cases} $$
那参数 $\theta$ 如何求呢?通常的做法是,先确定一个形如下式的整体损失函数
$$ J ( \theta ) = \frac { 1 } { m } \sum _ { i = 1 } ^ { m } \cos t \left( \mathbf { x } _ { i } , y _ { i } \right) $$
然后对其进行优化,从而得到最优的参数 $ \theta^* $。
实际应用中,单个样本的损失函数 $ cost \left( \mathbf { x } _ { i } , y _ { i } \right) $ 常取为对数似然函数
$$ cost \left( \mathbf { x } _ { i } , y _ { i } \right) = \begin{cases} { - \log( h _ { \theta } (\mathbf{ x } _ { i } ) ) , } & { y_i = 1 } \\ { - \log ( 1 - h_\theta ( \mathbf { x } _ { i } ) ) , } & { y_i = 0 } \end{cases} $$
注意,上式是一个分段函数,也可将其写成如下的整体表达式
$$ cost \left( \mathbf { x } _ { i } , y _ { i } \right) = - y _ { i } \cdot \log \left( h _ { \theta } \left( \mathbf { x } _ { i } \right) \right) - \left( 1 - y _ { i } \right) \cdot \log \left( 1 - h _ { \theta } \left( \mathbf { x } _ { i } \right) \right) $$
Bayes 公式
贝叶斯公式是英国数学家 贝叶斯(Thomas Bayes) 提出来的,用来描述两个条件概率之间的关系。若记 $P(A),P(B)$ 分别表示事件 $A$ 和事件 $B$ 发生的概率,$P(A|B)$ 表示事件 $B$ 发生的情况下事件 $A$ 发生的概率,$P(A, B)$ 表示事件 $A, B$ 同时发生的概率,则有
$$ P ( A | B ) = \frac { P ( A , B ) } { P ( B ) } , \quad P ( B | A ) = \frac { P ( A , B ) } { P ( A ) } $$
利用上式,进一步可得
$$ P ( A | B ) = P ( A ) \frac { P ( B | A ) } { P ( B ) } $$
这就是 Bayes 公式。
Huffman 编码
本节简单介绍 Huffman 编码,为此,首先介绍 Huffman 树的定义及其构造算法。
Huffman 树
在计算机科学中,树是一种重要的非线性数据结构,,它是数据元素(在树中称为结点)按分支关系组织起来的结构。若干棵互不相交的树所构成的集合称为森林。下面给出几个与树相关的常用概念
路径和路径长度
在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层号为 $1$,则从根结点到第 $L$ 层结点的路径长度为 $L-1$。结点的权和带权路径长度
若为树中结点赋予一个具有某种含义的(非负)数值,则这个数值称为该结点的权。结点的带权路径长度是指,从根结点到该结点之间的路径长度与该结点的权的乘积。树的带权路径长度
树的带权路径长度规定为所有叶子结点的带权路径长度之和。
二叉树是每个结点最多有两个子树的有序树。两个子树通常被称为“左子树”和“右子树”,定义中的“有序”是指两个子树有左右之分,顺序不能预倒。
给定 $n$ 个权值作为 $n$ 个叶子结点,构造一棵二叉树,若它的带权路径长度达到最小,则称这样的二叉树为最优二叉树,也称为Huffiman树。
Huffman树的构造
给定 $n$ 个权值 $ { w _ { 1 } , w _ { 2 } , \cdots , w _ { n } } $ 作为二叉树的 $n$ 个叶子结点,可通过以下算法来构造一颗 Huffman 树。
算法2.1 (Huffman 树构造算法)
- 将 $ { w _ { 1 } , w _ { 2 } , \cdots , w _ { n } } $ 看成是有 $n$ 稞树的森林(每棵树仅有一个结点);
- 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
- 从森林中删除选取的两棵树,并将新树加入森林。
- 重复2和3步,直到森林中只剩一稞树为止,该树即为所求的 Huffman 树。
接下来,给出算法2.1的一个具体实例
例2.1假设 2014 年世界杯期间,从新浪微博中抓取了若干条与足球相关的微博,经统计,“我”、“喜欢”、“观着”、“巴西”、“足球”、“世界杯”这六个词出现的次数分别为 $ 15,8,6,5,3,1 $。请以这6个词为叶子结点,以相应词频当权值,构造一棵Huffman树。
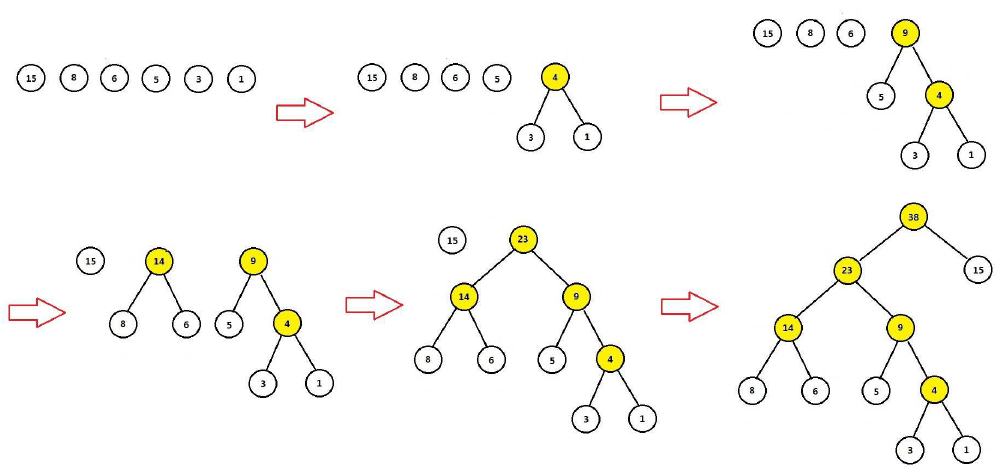
利用算法2.1, 易知其构造过程如上图所示。图中第六步给出了最终的 Huffman树,由图可见词频越大的词离根结点越近。
构造过程中,通过合并新增的结点被标记为黄色。由于每两个结点都要进行一次合并,因此,若叶子结点的个数为 $n$, 则构造的 Huffman树 中新增结点的个数为 $n-1$。本例中 $n=6$,因此新增结点的个数为 $5$ 。
注意,前面有提到,二叉树的两个子树是分左右的,对于某个非叶子结点来说,就是其两个孩子结点是分左右的,在本例中,统一将词频大的结点作为左孩子结点,词频小的作为右孩子结点。当然,这只是一个约定,你要将词频大的结点作为右孩子结点也没有问题。
Huffman 编码
在数据通信中,需要将传送的文字转换成二进制的字符串,用 0, 1 码的不同排列来表示字符。例如,需传送的报文为 “AFTER DATA EAR ARE ART AREA”,这里用到的字符集为 “A, E, R, T, F, D”,各字母出现的次数为 8, 4, 5, 3, 1, 1。现要求为这些字母设计编码。
要区别 6 个字母,最简单的二进制编码方式是等长编码,固定采用 3 位二进制($2^3 = 8>6$)。可分别用 000、001、010. 011、100、101 对 “A, E, R, T, F, D” 进行编码发送,当对方接收报文时再按照三位一分进行译码。
显然编码的长度取决报文中不同字符的个数。若报文中可能出现 26 个不同字符,则固定编码长度为 5 ($2^5 = 32 > 6$)。然而,传送报文时总是希望总长度尽可能短。在实际应用中,各个字符的出现频度或使用次数是不相同的,如 A、B、C 的使用频率远远高于 X、Y、Z,自然会想到设计编码时,让使用频率高的用短码,使用频率低的用长码,以优化整个报文编码。
为使不等长编码为前缀编码(即要求一个字符的编码不能是另一个字符编码的前缀),可用字符集中的每个字符作为叶子结点生成一棵编码二叉树,为了获得传送报文的最短长度,可将每个字符的出现频率作为字符结点的权值赋予该结点上,显然字使用频率越小权值越小,权值越小叶子就越靠下,于是频率小编码长,频率高编码短,这样就保证了此树的最小带权路径长度,效果上就是传送报文的最短长度。因此,求传送报文的最短长度问题转化为求由字符集中的所有字符作为叶子结点,由字符出现频率作为其权值所产生的 Huffman树 的问题。利用 Huffman 树设计的二进制前缎编码,称为 Huffman编码,它既能满足前缀编码的条件,又能保证报文编码总长最短。
本文将介绍的 word2vec 工具中也将用到 Huffman编码,它把训练语料中的词当成叶了结点,其在语料中出现的次数当作权值,通过构造相应的 Huffman树 来对每一个词进行 Huffman编码。
下图给出了 例2.1 中六个词的 Huffman编码,其中约定(词频较大的)左孩了结点编码为 1,(词频较小的)右孩子编码为 0。这样一来,“我”、“喜欢”、“观看”、“巴西”、“足球”、“世界杯”这六个词的 Huffman编码 分别为 0, 111, 110. 101, 1001和1000 。
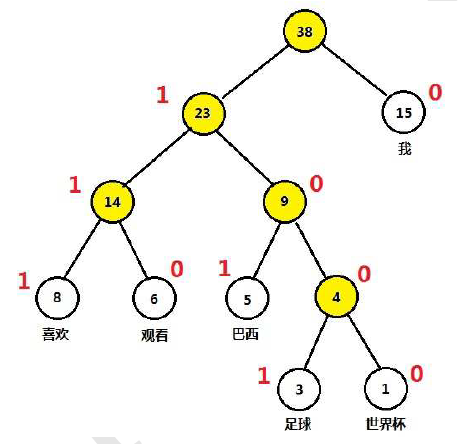
注意,到日前为止,关于 Huffman树 和 Huffman 编码,有两个约定:(1) 将权值大的结点作为左孩子结点,权值小的作为右孩子结点; (2) 左孩子结点编码为 1,右孩子结点编码为 0。在 word2vec 源码中将权值较大的孩子结点编码为 1,较小的孩子结点编码为 0 。为与上述约定统一起见,下文中提到的“左孩子结点”都是指权值较大的孩子结点。
背景知识
word2vec 是用来生成词向量的工具,而词向量与语言模型有着密切的关系,为此,不妨先来了解一些语言模型方的知识。
统计语言模型
当今的互联网迅猛发展,每天都在产生大量的文本、图片、语音和视频数据,要对这些数据进行处理并从中挖掘出有价值的信息,离不开白然语言处理 (Nature Language Processing, NLP) 技术,其中统计语言模型 (Statistical Language Model) 就是很重要的一环,它是所有 NLP 的基础,被广泛应用于语音识别、机器翻译、分词、词性标注和信息检索等任务。
例3.1在语音识别系统中,对于给定的语音段Voice,需要找到一个使概率 p(Tcxl Voicc) 最大的文本段 Text。利用 Bayes 公式,有
$$p ( \text {Text} | \text {Voice} ) = \frac { p ( \text {Voice} | T e x t ) \cdot p ( T e x t ) } { p ( \text {Voice} ) }$$
其中 $p ( \text {Voice} | \text { Text } )$ 为声学模型,而 $ p ( T e x t ) $ 为语言模型。
简单地说,统计语言模型是用来计算一个句子的概率的概率模型,它通常基于一个语料库来构建。那什么叫做一个句子的概率呢?假设 $W = w _ { 1 } ^ { T } = \left( w _ { 1 } , w _ { 2 } , \cdots , w _ { T } \right)$ 表示由 $T$ 个词 $w _ { 1 } , w _ { 2 } , \cdots , w _ { T }$ 按顺序构成的一个句子,则 $w _ { 1 } , w _ { 2 } , \cdots , w _ { T }$ 的联合概率
$$p ( W ) = p \left( w _ { 1 } ^ { T } \right) = p \left( w _ { 1 } , w _ { 2 } , \cdots , w _ { T } \right)$$
就是这个句子的概率。利用 Bayes 公式,上式可以被链式地分解为
$$p \left( w _ { 1 } ^ { T } \right) = p \left( w _ { 1 } \right) \cdot p \left( w _ { 2 } | w _ { 1 } \right) \cdot p \left( w _ { 3 } | w _ { 1 } ^ { 2 } \right) \cdots p \left( w _ { T } | w _ { 1 } ^ { T - 1 } \right) \tag{3.1}$$
其中的(条件)概率 $p \left( w _ { 1 } \right) , p \left( w _ { 2 } | w _ { 1 } \right) , p \left( w _ { 3 } | w _ { 1 } ^ { 2 } \right) , \cdots , p \left( w _ { T } | w _ { 1 } ^ { T - 1 } \right)$ 就是语言模型的参数,若这些参数已经全部算得,那么给定一个句子 $w _ { 1 } ^ { T }$,就可以很快地算出相应的 $p \left( w _ { 1 } ^ { T } \right)$了。
看起来好像很简单,是吧?但是,具体实现起来还是有点麻烦。例如,先来看看模型参数的个数。刚才是考虑一个给定的长度为 $T$ 的句子,就需要计算 $T$ 个参数。不妨假设语料库对应词典 $D$ 的大小(即词汇量)为 $N$,那么,如果考虑长度为 $T$ 的任意句子,理论上就有 $N^T$ 种可能,而每种可能都要计算 $T$ 个参数,总共就需要计算 $TN^T$ 个参数。当然,这里只是简单估算,并没有考虑重复参数,但这个量级还是有蛮吓人。此外,这些慨率计算好后,还得保存下来,因此,存储这些信息也需要很大的内存开销。
另外,这些参数如何计算呢?常见的方法有 n-gram 模型、决策树、最大熵模型、最大熵马尔科夫模型、条件随机场、神经网络等方法。本文只讨论 n-gram 模型和神经网络两种方法,首先来看看 n-gram 模型。
n-gram模型
考虑 $p \left( w _ { k } | w _ { 1 } ^ { k - 1 } \right) ( k > 1 )$ 的近似计算。利用 Bayes公式,有
$$p \left( w _ { k } | w _ { 1 } ^ { k - 1 } \right) = \frac { p \left( w _ { 1 } ^ { k } \right) } { p \left( w _ { 1 } ^ { k - 1 } \right) }$$
根据大数定理,当语料库是够大时,$p \left( w _ { k } | w _ { 1 } ^ { k - 1 } \right)$ 可近似地表示为
$$ p \left( w _ { k } | w _ { 1 } ^ { k - 1 } \right) \approx \frac { count \left( w _ { 1 } ^ { k } \right) } { count \left( w _ { 1 } ^ { k - 1 } \right) } \tag{3.2}$$
其中 $ count \left( w _ { 1 } ^ { k } \right)$ 和 $ count \left( w _ { 1 } ^ { k-1 } \right)$ 分别表示词串 $w_1^k$ 和 $w_1^{k-1}$ 在语料中出现的次数。可想而知,当 $k$ 很大时,$ count \left( w _ { 1 } ^ { k } \right)$ 和 $ count \left( w _ { 1 } ^ { k-1 } \right)$ 的统计将会多么耗时。
从 公式(3.1) 可以看出:一个词出现的概率与它前面的所有词都相关。如果假定一个词出现的慨率只与它前面固定数日的词相关呢?这就是 n-gram 模型的基本思想,它作了一个 $n- 1$ 阶的 Markov 假设,认为一个词出现的概率就只与它前面的 $n- 1$ 个词相关,即
$$p \left( w _ { k } | w _ { 1 } ^ { k - 1 } \right) \approx p \left( w _ { k } | w _ { k - n + 1 } ^ { k - 1 } \right)$$
于是,(3.2) 就变成了
$$p \left( w _ { k } | w _ { 1 } ^ { k - 1 } \right) \approx \frac { count \left( w _ { k - n + 1 } ^ { k } \right) } { count \left( w _ { k - n + 1 } ^ { k - 1 } \right) } \tag{3.3}$$
以 $n=2$ 为例,就有
$$p \left( w _ { k } | w _ { 1 } ^ { k - 1 } \right) \approx \frac { count \left( w _ { k - 1 } , w _ { k } \right) } { count \left( w _ { k - 1 } \right) }$$
这样一简化,不仅使得单个参数的统计变得更容易(统计时需要匹配的词串更短),也使得参数的总数变少了。
那么,n-gram 中的参数 $n$ 取多大比较合适呢?一般来说,$n$ 的选取需要同时考虑计算复杂度和模型效果两个因素。

在计算复杂度方面,表1给出了 n-gram 模型中模型参数数量随着 $n$ 的逐渐增大而变化的情况,其中假定词典大小 $N = 200000$ (汉语的词汇量大致是这个量级)。事实上,模型参数的量级是 $N$ 的指数函数 $(O(N^n))$,显然 $n$ 不能取得太大,实际应用中最多的是采用 $n=3$ 的三元模型。
在模型效果方面,理论上是 $n$ 越大,效果越好。现如今,互联网的海量数据以及机器性能的提升使得计算更高阶的语言模型(如$ n > 10 $)成为可能,但需要注意的是,当 $n$ 大到一定程度时,模型效果的提升幅度会变小。例如,当 $n$ 从 1 到 2,再从 2 到 3 时模型的效果上升显著,而从 3 到 4 时,效果的提升就不显著了(具体可参考吴军在《数学之美》中的相关章节)事实上,这里还涉及到一个可靠性和可区别性的问题,参数越多,可区别性越好,但同时单个参数的实例变少从而降低了可靠性,因此需要在可掌性和可区别性之问进行折中。
另外,n-gram 模型中还有一个叫做平滑化的重要环节。回到 公式(3.3),考虑两个问题:
- 若 $ count \left( w _ { k - n + 1 } ^ { k } \right) = 0 $,能否认为 $ p \left( w _ { k } | w _ { 1 } ^ { k - 1 } \right) $ 就等于 0 呢?
- 若$ count \left( w _ { k - n + 1 } ^ { k } \right) = count \left( w _ { k - n + 1 } ^ { k - 1 } \right) $,能否认为 $ p \left( w _ { k } | w _ { 1 } ^ { k - 1 } \right) $ 就等于 1 呢?
显然不能!但这是一个无法回避的问题,哪怕你的语料库有多么大。平滑化技术就是用来处理这个问题的,这里不展开讨论。
总结起米,n-gram 模型是这样一种模型,其主要工作是在语料中统计各种词串出现的次数以及平滑化处理。概率值计算好之后就有储起来,下次需要计算一个句子的概率时,只需找到相关的概率参数,将它们连乘起来就好了。
然而,在机器学习领域有一种通用的招数是这样的:对所考虑的问题建模后先为其构造一个目标函数,然后对这个目标函数进行优化,从而求得一组最优的参数,最后利用这组最优参数对应的模型来进行预测。
对于统计语言模型而言,利用最大似然,可把日标函数设为
$$\prod _ { w \in \mathcal { C } } p ( w | C o n t e x t ( w ) )$$
其中 $\mathcal { C }$ 表示语料 (Corpus),$Context(w)$ 表示词 $w$ 的上下文(Context),即 $w$ 周边的词的集合。当 $Context(w)$ 为空时,就取 $p ( w | Context ( w ) ) = p ( w )$ 。特别地,对于前面介绍的 n-gram 模型,就有 $Context(w_i) = w_{i-n+1}^{i-1}$
注3.1 语料 $\mathcal { C }$ 和词典 $\mathcal { D }$ 的区别:词典 $\mathcal { D }$ 是从浯料 $\mathcal { C }$ 中抽取出来的,不存在重复的词;而语料 $\mathcal { C }$ 是指所有的文本内容,包括重复的词。
当然,实际应用中常采用最大对数似然,即把日标函数设为
$$\mathcal { L } = \sum _ { w \in \mathcal { C } } \log p ( w | \text {Context} ( w ) ) \tag{3.4}$$
然后对这个函数进行最大化。
从 (3.4) 可见,概率 $ p(w|Context(w))$ 已被视为关于 $w$ 和 $Context(w)$ 的函数,即
$$p ( w | \text { Context } ( w ) ) = F ( w , \text { Context } ( w ) , \theta )$$
其中 $\theta $ 为待定参数集。这样一来,一旦对 (3.4) 进行优化得到最优参数集 $\theta^\ast $ 后,$F$ 也就唯一被确定了,以后任何概率 $ p(w|Context(w))$ 就可以通过函数 $ F(w, Context(w),\theta^\ast) $ 来计算了。与 n-gram 相比,这种方法不需要(事先计算并)保存所有的概率值,而是通过直接计算来获取,且通过选取合适的模型可使得 $\theta $ 中参数的个数远小于 n-gram 中模型参数的个数。
很显然,对于这样-一种方法,最关键的地方就在于函数 $F$ 的构造了。下一小节将介绍一种通过神经网络来构造 $F$ 的方法。之所以特意介绍这个方法,是因为它可以视为 word2vec 中算法框架的前身或者说基础。
神经概率语 言模型
本小节介绍 Bengio 等人在文《A neural probabilistic language model. Journal of Machine Learning Research》(2003)中提出的一种神经概率语言模型。该模型中用到了一个重要的工具——词向量。
什么是词向量呢?简单来说就是,对词典 $\mathcal { D }$ 中的任意词 $w$,指定一个固定长度的实值向量 $\mathbf { v } ( w ) \in \mathbb { R } ^ { m }$,$\mathbf { v } ( w )$ 就称为 $w$ 的词向量,$m$ 为词向量的长度。关于词向量的进一步理解将放到下一小节来讲解。
既然是神经概率语言模型,其中当然要用到一个神经网络啦。下图给出了这个神经网络的结构示意图,它包括四个层:输入(Input) 层、投影(Projection) 层、隐藏(Hidden)层和输出(OutPut)层。其中 $W, U$ 分别为投影层与隐藏层以及隐藏层和输出层之间的权值矩阵,$p, q$ 分别为隐藏层和输出层上的偏置向量。
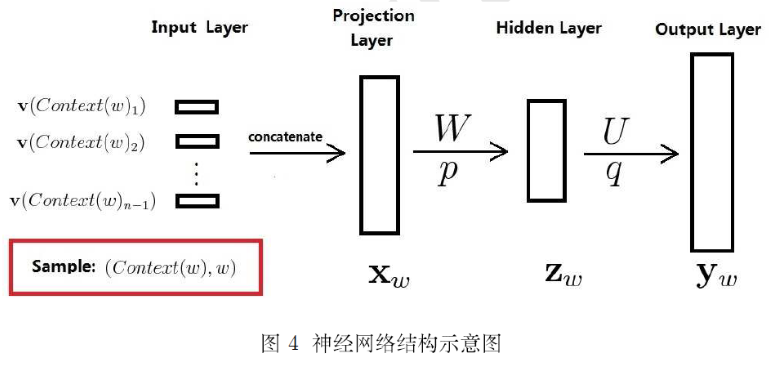
注3.2 当提及 Bengio 文中的神经网络时,人们更多将其视为如图5所示的三层结构。本文将其描述为如图4所示的四层结构,一方面是便于描述,另一方面是便于和 word2vec中使用的网络结构进行对比。
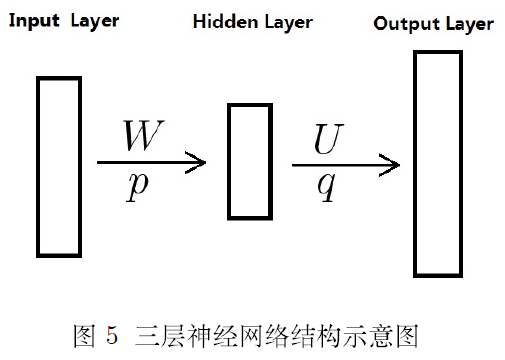
注3.3 作者在文中还考虑了投影层和输出层的神经元之问有边相连的情形,因而也会多出一个相应的权值矩阵,本文忽略了这种情形,但这并不影响对算法本质的理解。在数值实验中,作者发现引入投影层和输出层之间的权值矩阵虽然不能提高模型效果,但可以减少训练的选代次数。
对于语料 $\mathcal { C }$ 中的任意一个词 $w$,将 $Context(w)$ 取为其前面的 $n-1$ 个词(类似于n-gram),这样二元对 $(Context(w),w)$ 就是一个训练样本了。接下来,讨论样本 $(Context(w),w)$ 经过如图4所示的神经网络时是如何参与运算的。注意,一旦语料 $\mathcal { C }$ 和词向量长度 $m$ 给定后,投影层和输出层的规模就确定了,前者为 $(n- 1)m$,后者为 $N = | \mathcal { D } |$ 即语料 $\mathcal { C }$ 的词汇量大小。而急藏层的规模 $n_h$ 是可调参数由用户指定。
为什么投影层的规模是 $(n-1)m$ 呢?因为输入层包含 $Context(w)$ 中 $n-1$ 个词的词向量,而投影层的向量 $X_w$ 是这样构造的:将输入层的 $n-1$ 个词向量按顺序首尾相接地拼起来形成一个长向量,其长度当然就是 $(n-1)m$ 了,有了向量 $X_w$,接下来的计算过程就很平凡了,具体为
$$\left\lbrace \begin{array} { ll } { \mathbf { z } _ { w } = \tanh \left( W \mathbf { x } _ { w } + \mathbf { p } \right) } \\ { \mathbf { y } _ { w } = U \mathbf { z } _ { w } + \mathbf { q } } \end{array} \right. \tag{3.5}$$
其中 $tanh$ 为双曲正切函数,用来做隐藏层的激活函数,上式中,$tanh$ 作用在向量上表示它作用在向量的每一个分量上。
注3.4 有读者可能要问:对于语科中的一个给定句子的前几个词,其前面的词不足 $n-1$ 个怎么办?此时,可以人为地添加一个(或几个)填充向量就可以了,它们也参与训练过程。
经过上述两步计算得到的 $\mathbf { y } _ { w } = \left( y _ { w , 1 } , y _ { w , 2 } , \cdots , y _ { w , N } \right) ^ { \top }$ 只是一个长度为 $N$ 的向量,其分量不能表示概率。如果想要 $ \mathbf{ y } _ w $ 的分量 $y_{w,i}$,表示当上下文为 $Context(w)$ 时下一个词恰为词典 $\mathcal { D }$ 中第 $i$ 个词的慨率,则还需要做一个 softmax 归一化,归一化后,$p(w|Context(w))$就可以表示为
$$ p ( w | \text { Context } ( w ) ) = \frac { e ^ { y _ { w , i_w } } } { \sum _ { i = 1 } ^ { N } e ^ { y _ { w , i } } } \tag{3.6}$$
其中 $i_w$ 表示词 $w$ 在词典 $\mathcal { D }$ 中的索引。
公式(3.6) 给出了概率 $p(w|Context(w))$ 的函数表示,即找到了上一小节中提到的函数 $F(w, Context(w), \theta)$,那么其中待确定的参数 $\theta$ 有哪些呢?总结起来,包括两部分
- 词向量:$\mathbf { v } ( w ) \in \mathbb { R } ^ { m } , w \in \mathcal { D }$以及填允向量。
- 神经网络参数:$W \in \mathbb { R } ^ { n _ { h } \times ( n - 1 ) m } , \mathbf { p } \in \mathbb { R } ^ { n _ { h } } ; U \in \mathbb { R } ^ { N \times n _ { h } } , \mathbf { q } \in \mathbb { R } ^ { N }$
这些参数均通过圳练算法得到。值得一提的是,通常的机器学习算法中,输入都是已知的,而在上述神经概率语言模型中,输入 $ \mathbf { v } ( w )$ 也需要通过训练才能得到。
接下来,简要地分析一下上述模型的运算量。在如图4所示的神经网络中,投影层、隐藏层和输出层的规模分别为 $(n-1)m, n_h, N$,依次看看其中涉及的参数:
- $n$ 是一个词的上下文中包含的词数,通常不超过5;
- $m$ 是词向量长度,通常是 $10^1 \sim 10^2$ 量级;
- $n_h$ 由用户指定,通常不需取得太大,如 $10^2$ 量级;
- $N$ 是语料词汇量的大小,与语料相关,但通常是 $10^4 \sim 10^5$ 量级。
再结合 (3.5) 和 (3.6),不难发现,整个模型的大部分计算集中在隐藏层和输出层之间的矩阵向量运算,以及输出层上的 softmax 归一化运算。因此后续的相关研究工作中,有很多是针对这一部分进行优化的,其中就包括了 word2vec 的工作。
与 n-gram 模型相比,神经概率语言模型有什么优势呢?主要有以下两点:
词语之间的相似性可以通过词向量来体现
举例来说,如果某个(英语) 语料中 $S_1$ = “A dog is runing in the room” 出现了 10000 次,而 $S_1$ = “A cat is ruuning in the room” 只出现了 1 次。按照 n-gram 模型的做法,$p(S1)$ 肯定会远大于 $p(S2)$。注意,$S1$ 和 $S2$ 的唯一区别在于 dog 和 cat,而这两个词无论是句法还是语义上都扮演了相同的角色,因此,$p(S1)$ 和$p(S2)$ 应该很相近才对。
然而,由神经概率语言模型算得的 $p(S1)$ 和 $p(S2)$ 是大致相等的。原因在于:(1)在神经概率语言模型中假定了“相似的”的词对应的词向量也是相似的;(2)概率函数关于词向量是光滑的,即词向量中的一个小变化对概率的影响也只是一个小变化。这样一来,对于下面这些句子只要在语料库中出现一个,其他句子的概率也会相应地增大。A dog is running in the room
A cat is running in the room
The cat is running in a room
A dog is walking in a bedroom
The dog was walking in the room基于词向量的模型自带平滑化功能(由
(3.6)可知,$p(w|Context(w)) \in (0,1)$不会为零),不再需要像n-gram那样进行额外处理了。
最后,我们回过头来想想,词向量在整个神经概率语言模型中扮演了什么角色呢?训练时,它是用来帮助构造目标函数的辅助参数,训练完成后,它也好像只是语言模型的一个副产品。但这个副产品可不能小觑,下一小节将对其作进一步阐述。
词向量的理解
通过上一小节的讨论,相信大家对词向量已经有一个初步的认识了。接下来,对词向量做进一步介绍。
在 NLP 任务中,我们将自然语言交给机器学习算法来处理,但机器无法直接理解人类的语言,因此首先要做的事情就是将语言数学化,如何对自然语言进行数学化呢?词向量提供了一种很好的方式。
一种最简单的词向量是 one-hot representation,就是用一个很长的向量来表示一个词,向量的长度为词典 $\mathcal { D }$ 的大小 $N$,向量的分量只有一个 1,其它全为 0,1 的位置对应该词在词典中的索引。但这种词向量表示有一些缺点,如容易受维数灾难的因扰,尤其是将其用于 Deep Learning 场景时;又如,它不能很好地刻画词与词之间的相似性。
另一种词向量是 Distributed Representation, 它最早是 Hinton 于 1986 年提出的,可以克服 one-hot representation 的上述缺点其基本想法是:通过训练将某种语言中的每一个词映射成一个固定长度的短向量(当然这里的“短”是相对于 one-hot representation 的“长”而言的),所有这些向量构成一个词向量空间,而每一向量则可视为该空间中的一个点,在这个空间上引入“距离”,就可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性了。word2vec 中采用的就是这种 Distributed Representalion 的词向量。
为什么叫做 Distributed Representation?很多人问到这个问题我的一个理解是这样的:对于 one-hot representation,向量中只有一个非零分量,非常集中(有点孤注一掷的感觉);而对于 Distributed Representetion,向量中有大量非零分量,相对分散(有点风险平摊的感觉),把词的信息分布到各个分量中去了。这一点,跟并行计算里的分布式并行很像。
为更好地理解上述思想,我们来举一个通俗的例子。
例3.2假设在二维平面上分布有 a 个不同的点,给定其中的某个点,现在想在平面上找到与这个点最相近的一个点。
我们是怎么做的呢?首先,建立一个直角坐标系,基于该坐标系,其上的每个点就唯一地对应一个坐标(x, y);接着引入欧氏距离,最后分别计算这个点与其他 a-1 个点之间的距离,对应最小距离值的那个(或那些)点便是我们要找的点了。
上面的例子中,坐标 (x, y) 的地位就相当于词向量,它用来将中面上一个点的位置在数学上作量化。坐标系建立好以后,要得到某个点的坐标是很容易的。然而,在 NLP 任务中,要得到词向量就复杂得多了,而且词向量并不唯一,其质量依赖于训练语料、训练算法等因素。
如何获取词向量呢?有很多不同模型可用来估计词向量,包括有名的 LSA (Latent Semantic Analysis) 和 LDA (Latcnt Dirichlet Allocation)。此外,利用神经网络算法也是一一种常用的方法,上一小节介绍的神经概率语言模型就是一个很好的实例。当然,在那个模型中,目标是生成语言模型,词向量只是一个副产品。事实上,大部分情况下,词向量和语言模型都是捆绑在一起的,训练完成后两者同时得到。用神经网络来训练语言模型的思想最早由百度 IDL(深度学习研究院)的徐伟提出。这方面最经典的文章要数 Bengio 于 2003 年发表在 JMLR上的《A Neural Probabilistic Language Model》,其后有一系列相关的研究工作,其中也包括谷歌 Tomas Mikolov 团队的 word2vec。
一份好的词向量是很有价值的,下面介绍一个简单的例子,可以帮助我们更好地理解词向量的工作原理。
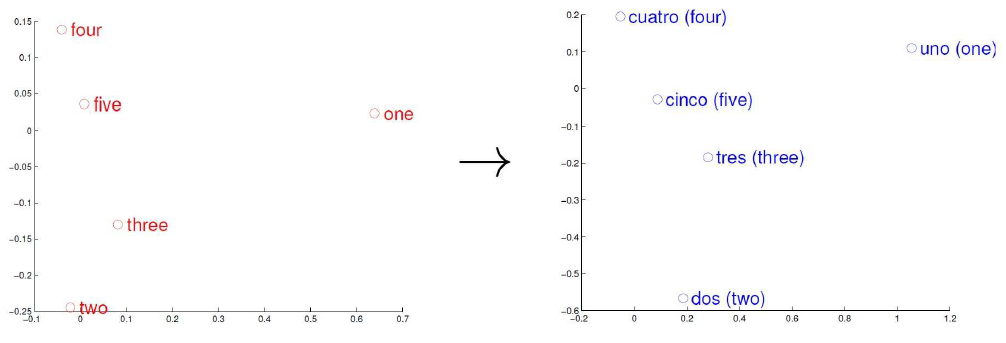
考虑英语和西班牙语两种语言,通过训练分别得到它们对应的词向量空间 $E$(nglish) 和 $S$(panish)。从英语中取出五个词one, two, three, four, five,设其在 $E$ 中对应的词向量分别为 $u_1,u_2,u_3,u_4,u_5$,为方便作图,利用主成分分析 (PCA) 降维,得到相应的二维向量 $v_1,v_2,v_3,v_4,v_5$,在二维平面上将这五个点描出来,如上图左图所示。
类似地,在西班牙语中取出(与one, two, three, four, five对应的)uno, dos, tres, cuatro, cinco,设其在 $S$ 中对应的词向量分别为 $s_1, s_2, s_3, s_4, s_5$,用 PCA 降维后的二维向量分别为 $t_1, t_2, t_3, t_4, t_s$,将它们在二维平面上描出来(可能还需作适当的旋转),如上图右图所示。
观察左、右两幅图,容易发现:五个词在两个向量空间中的相对位置差不多,这说明两种不同语言对应向量空间的结构之间具有相似性,从而进一步说明了在词向量空间中利用距离刻画词之间相似性的合理性。
注意,词向量只是针对“词”来提的,事实上,我们也可以针对更细粒度或更粗粒度来进行推广,如字向量,句子向量和文档向量,它们能为字、句子、文档等单元提供更好的表示。
基于 Hierarchical Softmax的模型
有了前面的准备,本节开始止式介绍 word2vec 中用到的两个重要模型—— CBOW 模型 (Continuous Bag-of Words Model) 和 Skip-gram 模型 (Continuous Skip-gran Model) 。关于这两个模型,作者 Tomas Mikolov 在文[5]给出了如图8和图9所示的示意图。
由图可见,两个模型都包含三层:输人层、投影层和输出层。前者是在已知当前词 $w_t$ 的上下文 $w_{t-2},w_{t-1},w_{t+1},w_{t+2}$ 的前提下预测当前词$w_t$(见图8);而后者恰恰相反,是在已知当前词 $w_t$ 的前提下,预测其上下文 $w_{t-2},w_{t-1},w_{t+1},w_{t+2}$ (见图9)。
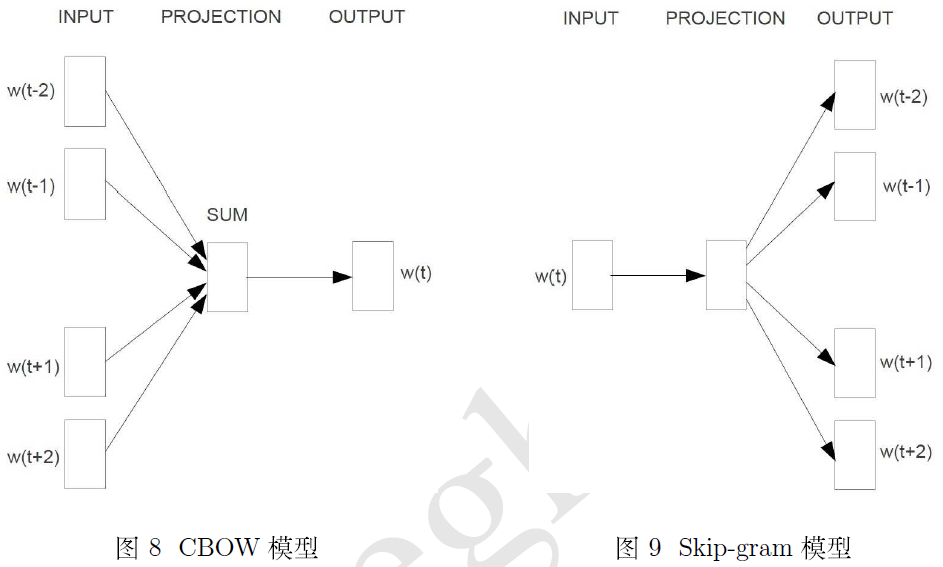
对于 CBOW 和 Skp-gram 两个模型,word2vec 给出了两套框架,它们分别基于 Hierarchical Softmax 和 Negative Sampling 来进行设计。本节介绍基于 Hierarchical Softmax 的 CBOW 和 Skip-gram 模型.
在上节中,我们提到,基于神经网络的语言模型的目标函数通常取为如下对数似然函数
$$\mathcal { L } = \sum _ { w \in \mathcal { C } } \log p ( w | Context ( w ) ) \tag{4.1}$$
其中的关键是条件概率函数 $p ( w | Context ( w ) )$ 的构造,文[2]中的模型就给出了这个函数的一种构造方法(见 (3.6)式 )。
对于 word2vec 中基于 Hierarchical Softmax 的 CBOW 模型,优化的目标函数也形如 (4.1);而对于基于 Hierarchical Softmax 的 Skip-gram 模型,优化的目标函数则形如
$$\mathcal { L } = \sum _ { w \in \mathcal { C } } \log p ( Context ( w ) | w ) \tag{4.2}$$
因此,讨论过程中我们应将重点放在 $p ( w | Context ( w ) )$ 或 $p ( Context ( w ) | w )$ 的构造上,意识到这一点很重要,因为它可以让我们目标明确、心无旁骛,不致于陷入到一些繁琐的细节当中去。接下来将从数学的角度对这两个模型进行详细介绍。
CBOW 模型
本小节介绍 word2vec 中的第一个模型—— CBOW 模型。
网络结构
图10给出了 CBOW 模型的网络结构,它包括三层:输入层、投影层和输出层。下面以样本 $(Context(w), w)$ 为例(这里假设 $Context(w)$ 由 $w$ 前后各 $c$ 个词构成),对这三个层做简要说明。
输入层:包含 $Context(w)$ 中 $2c$ 个词的词向量$\mathbf { v } ( Context ( w ) _ { 1 }),\mathbf { v } ( Context ( w ) _ { 2 }),\cdots,\mathbf { v } ( Context ( w ) _ { 2c }) \in \mathbb { R } ^ { m }$ 。这里 $m$ 的含义同上表示词向量的长度。
投影层:将输入层的 $2c$ 个向量做求和累加,即 $ \mathbf { x } _ { w } = \sum _ { i = 1 } ^ { 2 c } \mathbf { v } ( Context ( w ) _ { i } ) \in \mathbb { R } ^ { m }$。
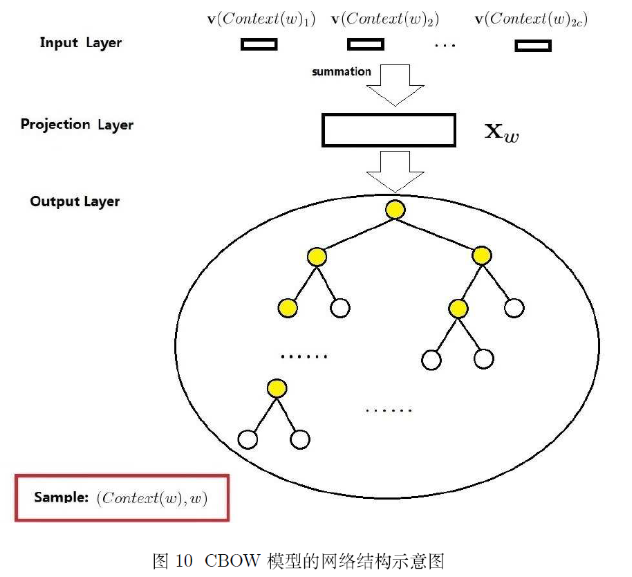
- 输出层:输出层对应一棵二叉树,它是以语料中出现过的词当叶子结点,以各词在语料中出现的次数当权值构造出来的
Huffman树。在这棵Huffman树中,叶子结点共 $ N(=| \mathcal { D } |)$ 个,分别对应词典 $\mathcal { D }$ 中的词,非叶子结点 N-1 个(图中标成黄色的那些结点)。
对比3.3节中神经概率语言模型的网络图(见图4)和 CBOW 模型的结构图(见图10),易知它们主要有以下三处不同:
- (从输入层到投影层的操作)前者是通过拼接,后者通过累加求和。
- (隐藏层)前者有隐藏层,后者无隐藏层。
- (输出层)前者是线性结构,后者是树形结构。
在3.3节介绍的神经概率语言模型中,我们指出,模型的大部分计算集中在隐藏层和输出层之间的矩阵向量运算,以及输出层上的 softmax 归一化运算。而从上面的对比中可见,CBOW 模型对这些计算复杂度高的地方有针对性地进行了改变,首先,去掉了隐藏层,其次,输出层改用了 Huffman树 ,从而为利用Hierarchical softmax 技术奠定了基础。
梯度计算
Hierarchical Softmax 是 word2vec 中用于提高性能的一项关键技术,为描述方使起见,在具体介绍这个技术之前,先引入若干相关记号。考虑 Huffman树 中的某个叶子结点,假设它对应词典 $\mathcal { D }$ 中的词 $w$,记
- $p^w$:从根结点出发到达 $w$ 对应叶子结点的路径;
- $l^w$:路径 $p^w$ 中包含结点的个数;
- $p_1^w,p_2^w,\cdots,p_{l^w}^w$:路径 $p^w$ 中的 $l^w$ 个结点,其中 $p_1^w$ 表示根结点,$p_{l^w}^w$ 表示词 $w$ 对应的结点;
- $d_1^w,d_2^w,\cdots,d_{l^w}^w \in \lbrace 0,1 \rbrace$:词 $w$ 的Huffman编码,它由 $l^w- 1$ 位编码构成,$d_j^w$ 表示路径 $p^w$ 中第 $j$ 个结点对应的编码(根结点不对应编码);
- $\theta_1^w,\theta_2^w,\cdots,\theta_{l^w-1}^w \in \mathbb { R } ^ { m }$:路径 $p^w$ 中非叶子结点对应的向量,$\theta_j^w$ 表示路径 $p^w$ 中第 $j$ 个非叶子结点对应的向量。
注4.1 按理说,我们要求的是词典 $\mathcal { D }$ 中每个词(即Huffman树中所有叶子节点)的向量,为什么这里还要为 Huffman树 中每一个非叶子结点也定义一个同长的向量呢?事实上,它们只是算法中的辅助向量,具体用途在下文中将会为大家解释清楚。
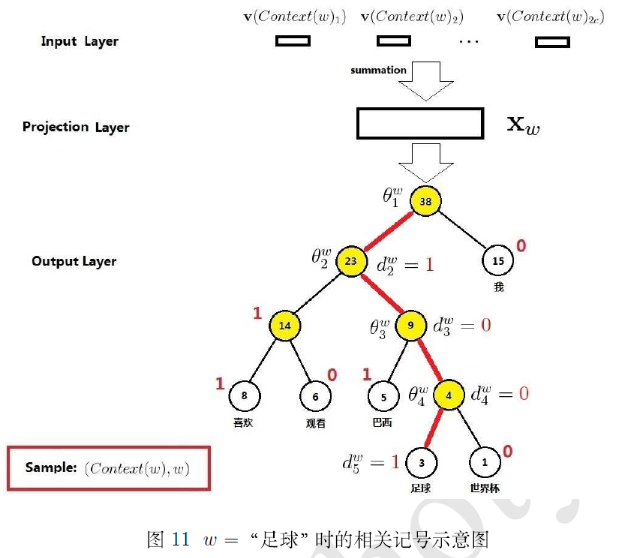
好了,引入了这么一大堆抽象的记号,接下来,我们还是通过一个简单的例子把它们落到实处吧,看图11,仍以预备知识中 例2.1 为例考虑词 $w$ =“足球” 的情形。
图11中由 4 条红色边串起来的 5 个节点就构成路径 $p^w$,其长度 $l^w=5$。$p_1^w,p_2^w,p_3^w,p_4^w,p_5^w$ 为路径 $p^w$ 上的 5 个结点,其中 $p_1^w$ 对应根结点。$d_2^w,d_3^w,d_4^w,d_5^w$ 分别为 1, 0, 0, 1,即“足球”的 Huffman编码 为 1001 。此外,$\theta_1^w,\theta_2^w,\theta_3^w,\theta_4^w$ 明分别表示路径 $p^w$ 上 4 个非叶了结点对应的向量。
那么,在如图10所示的网络结构下,如何定义条件慨率函数 $p ( w | Context ( w ) )$ 呢?更具体地说,就是如何利用向量 $\mathbf { x } _ { w } \in \mathbb { R } ^ { m }$ 以及 Huffman 树来定义函数 $p ( w | Context ( w ) )$ 呢?
以图11中词 $w$ =“足球”为例。从根结点出发到达“足球”这个叶子节点,中间共经历了4次分支(每条红色的边对应一次分支),而每一次分支都可视为进行了一次二分类。
既然是从二分类的角度来考虑问题,那么对于每一个非叶子结点,就需要为其左右孩了结点指定一个类别,即哪个是正类(标签为1),哪个是负类(标签为0)。碰巧除根结点以外,树中每个结点都对应了一个取值为 0 或 1 的 Huffman编码 因此,一种最白然的做法就是将 Huffman编码 为 1 的结点定义为正类,编码为 0 的结点定义为负类。当然,这只是个约定而已,你也可以将编码为 1 的结点定义为负类,而将编码为 0 的结点定义为正类。事实上,word2vec 选用的就是后者,为方便读者对照着文档看源码,下文中统一采用后者,即约定
$$Label\left( p _ { i } ^ { w } \right) = 1 - d _ { i } ^ { w } , i = 2,3 , \cdots , l ^ { w }$$
简言之就是,将一个结点进行分类时,分到左边就是负类,分到右边就是正类。
根据预备知识2.2中介绍的逻辑回归,易知,一个结点被分为正类的概率是
$$\sigma \left( \mathbf { x } _ { w } ^ { \top } \theta \right) = \frac { 1 } { 1 + e ^ { - \mathbf { x } _ { w } ^ { \top } \theta } }$$
被分为负类的概率当然就等于
$$1 - \sigma \left( \mathbf { x } _ { w } ^ { \top } \theta \right)$$
注意,上式中有个叫 $\theta$ 的向量,它是待定多数,显然在这里非叶子结点对应的那些向量 $\theta_i^w$ 就可以扮演参数 $\theta$ 的角色(这也是为什么将它们取名为 $\theta_i^w$ 的原因)。
对于从根结点出发到达“足球”这个叶子节点所经历的 4 次二分类,将每次分类结果的概率写出来就是
- 第1次:$ p(d_2^ w|\mathbf{x}_ w,\theta_1^w) = 1 - \sigma(\mathbf{x}_ w^\top\theta_1^w) $;
- 第2次: $ p(d_3^ w|\mathbf{x}_ w,\theta_2^w) = \sigma(\mathbf{x}_ w^\top\theta_2^w) $;
- 第3次: $ p(d_4^ w|\mathbf{x}_ w,\theta_3^w) = \sigma(\mathbf{x}_ w^\top\theta_3^w) $;
- 第4次: $ p(d_5^ w|\mathbf{x}_ w,\theta_4^w) = 1 - \sigma(\mathbf{x}_ w^\top\theta_4^w) $;
但是,我们要求的是 $p($足球$|Context($足球$))$,它跟这 4 个概率值有什么关系呢?关系就是
$$p(\text{足球}|Context(\text{足球})) = \prod _ { j = 2 } ^ { 5 } p \left( d _ { j } ^ { w } | \mathbf { x } _ { w } , \theta _ { j - 1 } ^ { w } \right)$$
至此,通过 $w$ = “足球”的小例子,Hierarchical Softmax 的基本思想其实就已经介绍完了。小结一下:对于词典 $\mathcal { D }$ 中的任意词 $w$,Huffman树 中必存在一条从根结点到词 $w$ 对应结点的路径 $p^w$(且这条路径是唯一的)。路径 $p^w$ 上存在 $l^w-1$ 个分支,将每个分支看做一次二分类,每一次分类就产生一个概率,将这些概率乘起来,就是所需的 $p(w|Context(w))$。
条件概率 $p(w|Context(w))$ 的一般公式可写为
$$p ( w | Context ( w ) ) = \prod _ { j = 2 } ^ { l ^ { w } } p \left( d _ { j } ^ { w } | \mathbf { x } _ { w } , \theta _ { j - 1 } ^ { w } \right) \tag{4.3}$$
其中
$$p \left( d _ { j } ^ { w } | \mathbf { x } _ { w } , \theta _ { j - 1 } ^ { w } \right) = \begin{cases} { \sigma \left( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } \right) , } & { d _ { j } ^ { w } = 0 } \\ { 1 - \sigma \left( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } \right) , } & { d _ { j } ^ { w } = 1 } \end{cases} $$
或者写成整体表达式
$$p \left( d _ { j } ^ { w } | \mathbf { x } _ { w } , \theta _ { j - 1 } ^ { w } \right) = \left[ \sigma \left( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } \right) \right] ^ { 1 - d _ { j } ^ { w } } \cdot \left[ 1 - \sigma \left( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } \right) \right] ^ { d _ { j } ^ { w } }$$
注4.2 在3.3节中,最后得到的条件概率为
$$p ( w | Context ( w ) ) = \frac { e ^ { y _ { w , i _ { w } } } } { \sum _ { i = 1 } ^ { N } e ^ { y _ { w , i } } }$$
具体见 (3.6)式 ,由于这里有个归一化操作,因此显然成立
$$\sum _ { w \in \mathcal { D } } p ( w | Context ( w ) ) = 1$$
然而,对于由 (4.3) 定义的概率,是否也能满足上式呢?这个问题留给读者思考。
将 (4.3) 代入对数似然函数 (4.1),便得
$$\mathcal { L } = \sum _ { w \in \mathcal { C } } \log \prod _ { j = 2 } ^ { l ^ { w } } \lbrace [ \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) ] ^ { 1 - d _ { j } ^ { w } } \cdot [ 1 - \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) ] ^ { d _ { j } ^ { w } } \rbrace$$
$$= \sum _ { w \in \mathcal { C } } \sum _ { j = 2 } ^ { l ^ { w } } \lbrace ( 1 - d _ { j } ^ { w } ) \cdot \log [ \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) ] + d _ { j } ^ { w } \cdot \log [ 1 - \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) ] \rbrace \tag{4.4}$$
为下面梯度推导方便起见,将上式中双重求和符号下花括号里的内容简记为 $\mathcal { L } ( w , j )$,即
$$\mathcal { L } ( w , j ) = \left( 1 - d _ { j } ^ { w } \right) \cdot \log \left[ \sigma \left( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } \right) \right] + d _ { j } ^ { w } \cdot \log \left[ 1 - \sigma \left( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } \right) \right] \tag{4.5}$$
至此,已经推导出对数似然函数 (4.4),这就是 CBOW 模型的目标函数,接下来讨论它的优化,即如何将这个函数最大化。word2vec 里面采用的是随机梯度上升法。而梯度类算法的关键是给出相应的梯度计算公式,因此接下来重点讨论梯度的计算。
随机梯度上升法的做法是:每取一个样本 $(Context(w), w)$,就对目标函数中的所有(相关)参数做一次刷新。观察目标函数 $\mathcal { L }$ 易知,该函数中的参数包括向量 $\mathbf { x } _ { w } , \theta _ { j - 1 } ^ { w } , w \in \mathcal { C } , j = 2 , \cdots , l ^ { w }$。为此,先给出函数 $\mathcal { L } ( w , j )$ 关于这些向量的梯度。
首先考虑 $\mathcal { L } ( w , j )$ 关于 $\theta_{j-1}^w$ 的梯度计算。
$$\frac { \partial \mathcal { L } ( w , j ) } { \partial \theta _ { j - 1 } ^ { w } } = \frac { \partial } { \partial \theta _ { j - 1 } ^ { w } } \lbrace ( 1 - d _ { j } ^ { w } ) \cdot \log [ \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) ] + d _ { j } ^ { w } \cdot \log [ 1 - \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) ] \rbrace $$
$$= ( 1 - d _ { j } ^ { w } ) [ 1 - \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) ] \mathbf { x } _ { w } - d _ { j } ^ { w } \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) \mathbf { x } _ { w }$$
$$= \lbrace ( 1 - d _ { j } ^ { w } ) [ 1 - \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) ] - d _ { j } ^ { w } \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) \rbrace \mathbf { x } _ { w }$$
$$= \left[ 1 - d _ { j } ^ { w } - \sigma \left( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } \right) \right] \mathbf { x } _ { w }$$
$$\begin{array}{llll}
\frac { \partial \mathcal { L } ( w , j ) } { \partial \theta _ { j - 1 } ^ { w } } & = & \frac { \partial } { \partial \theta _ { j - 1 } ^ { w } } \lbrace ( 1 - d _ { j } ^ { w } ) \cdot \log [ \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) ] + d _ { j } ^ { w } \cdot \log [ 1 - \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) ] \rbrace \\
& = & ( 1 - d _ { j } ^ { w } ) [ 1 - \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) ] \mathbf { x } _ { w } - d _ { j } ^ { w } \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) \mathbf { x } _ { w } \\
& = & \lbrace ( 1 - d _ { j } ^ { w } ) [ 1 - \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) ] - d _ { j } ^ { w } \sigma ( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } ) \rbrace \mathbf { x } _ { w } \\
& = & \left[ 1 - d _ { j } ^ { w } - \sigma \left( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } \right) \right] \mathbf { x } _ { w }
\end{array}$$
于是,$\theta_{j-1}^w$ 的更新公式可写为
$$\theta _ { j - 1 } ^ { w } : = \theta _ { j - 1 } ^ { w } + \eta \left[ 1 - d _ { j } ^ { w } - \sigma \left( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } \right) \right] \mathbf { x } _ { w }$$
其中 $\eta$ 表示学习率,下同。
接下来考虑 $\mathcal { L } ( w , j )$ 关于 $\mathbf { x } _ { w }$ 的梯度。观察 (4.5) 可发现,$\mathcal { L } ( w , j )$ 中关于变量 $\mathbf { x } _ { w }$ 和 $\theta_{j-1}^w$ 是对称的(即两者可交换位置),因此,相应的梯度 $\frac { \partial \mathcal { L } ( w , j ) } { \partial \mathbf { x } _ { w } }$ 也只需在 $\frac { \partial \mathcal { L } ( w , j ) } { \partial \theta _ { j - 1 } ^ { w } }$ 的基础上对这两个向量交换位置就可以了,即
$$\frac { \partial \mathcal { L } ( w , j ) } { \partial \mathbf { x } _ { w } } = \left[ 1 - d _ { j } ^ { w } - \sigma \left( \mathbf { x } _ { w } ^ { \top } \theta _ { j - 1 } ^ { w } \right) \right] \theta _ { j - 1 } ^ { w }$$
到这里,细心的读者可能已经看出问题来了:我们的最终目的是要求词典 $\mathcal { D }$ 中每个词的词向量,而这里的 $\mathbf { x } _ { w }$ 表示的是 $Context(w)$ 中各词词向量的累加。那么,如何利用 $\frac { \partial \mathcal { L } ( w , j ) } { \partial \mathbf { x } _ { w } }$ 来对 $\mathbf { v } ( \widetilde { w } ) , \tilde { w } \in \text { Context } ( w )$ 进行更新呢?word2vec 中的做法很简单,直接取
$$\mathbf { v } ( \widetilde { w } ) : = \mathbf { v } ( \widetilde { w } ) + \eta \sum _ { j = 2 } ^ { l ^ { w } } \frac { \partial \mathcal { L } ( w , j ) } { \partial \mathbf { x } _ { w } } , \quad \widetilde { w } \in \text { Context } ( w )$$
即把 $\sum _ { j = 2 } ^ { l ^ { w } } \frac { \partial \mathcal { L } ( w , j ) } { \partial \mathbf { x } _ { w } }$ 贡献到 $Context(w)$ 中每一个词的词向量上。这个应该很好理解,既然 $\mathbf{ x } _ {w}$ 本身就是 $Context(w)$ 中各词词向量的累加,求完梯度后当然也应该将其贡献到每个分量上去。
注4.3 当然,读者这里需要考虑的是:采用平均贡献会不会更合理?即使用公式
$$\mathbf { v } ( \widetilde { w } ) : = \mathbf { v } ( \widetilde { w } ) + \frac { \eta } { | Context ( w ) | } \sum _ { j = 2 } ^ { l ^ { w } } \frac { \partial \mathcal { L } ( w , j ) } { \partial \mathbf { x } _ { w } } , \quad \widetilde { w } \in Context( w )$$
其中 $|Context(w)|$ 表示 $Context(w)$ 中词的个数。
下面以样本 $(Comtext(w),w)$ 为例,给出CBOW模型中采用随机梯度上升法更新各参数的伪代码。

注意,步3.3和步3.4不能交换次序,即 $\theta _ { j - 1 } ^ { w }$ 应等贡献到 $e$ 后再做更新。
注4.4 结合上面的伪代码:简单给出其与 word2vec 源码中的对应关系如下:$syn0$ 对应 $\mathbf { v } ( \cdot )$,$syn1$ 对应 $\theta _ { j - 1 } ^ { w }$,$neu1$ 对应 $\mathbf { X } _ { w }$,$neu1e$对应 $e$ 。
Skip-gram 模型
本小节介绍 word2vec 中的另一个模型 —— Skip-gram模型,由于推导过程与CBOW大同小异,因此会沿用上小节引入的记号。
网络结构
图12给出了Skip-gram模型的网络结构,同CBOW模型的网络结构一样,它也包括三层:输入层、投影层和输出层。下面以样本 $(w, Context(w))$ 为例,对这三个层做简要说明。
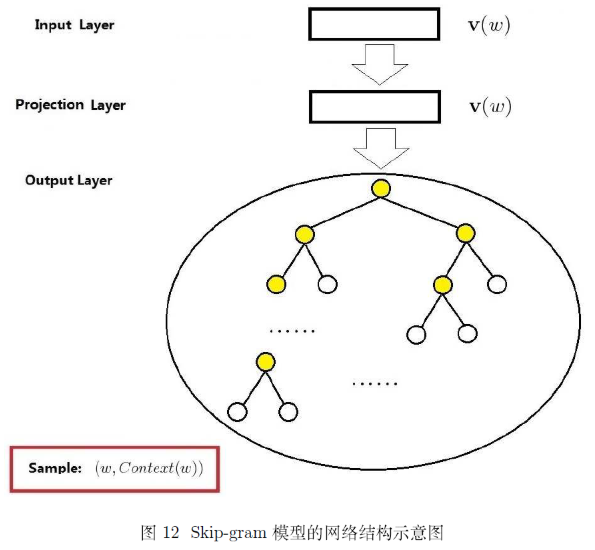
- 输人层:只含当前样本的中心词 $w$ 的词向量 $\mathbf { v } ( w ) \in \mathbb { R } ^ { m }$;
- 投影层:这是个恒等投影,把 $\mathbf { v } ( w )$ 投影到 $\mathbf { v } ( w )$。因此,这个投影层其实是多余的,这里之所以保留投影层主要是方便和CBOW模型的网络结构做对比;
- 输出层:和CBOW模型一样,输出层也是一棵 Huffman 树。
梯度计算
对于Skip-gram模型,已知的是当前词 $w$,需要对其上下文 $Context(w)$ 中的词进行预测,因此日标函数应该形如(4.2), 且关键是条件概率函数 $p(Context(w)|w)$ 的构造, Skip-gram模型中将其定义为
$$p ( \text {Context} ( w ) | w ) = \prod _ { u \in Context(w) } p ( u | w )$$
上式中的 $p(u|w)$ 可按照上小节介绍的 Hierarchical Softmax 思想,类似于 (4.3) 地写为
$$p ( u | w ) = \prod _ { j = 2 } ^ { l ^ { u } } p \left( d _ { j } ^ { u } | \mathbf { v } ( w ) , \theta _ { j - 1 } ^ { u } \right)$$
其中
$$p \left( d _ { j } ^ { u } | \mathbf { v } ( w ) , \theta _ { j - 1 } ^ { u } \right) = \left[ \sigma \left( \mathbf { v } ( w ) ^ { \top } \theta _ { j - 1 } ^ { u } \right) \right] ^ { 1 - d _ { j } ^ { u } } \cdot \left[ 1 - \sigma \left( \mathbf { v } ( w ) ^ { \top } \theta _ { j - 1 } ^ { u } \right) \right] ^ { d _ { j } ^ { u } } \tag{4.6}$$
将 (4.6) 依次代回,可得对数似然函数 (4.2) 的具体表达式
$$
\begin{array}{llll} \mathcal{L} &=\sum_{w \in \mathcal{C}} \log \prod_{u \in C \text { ontext }(w)} \prod_{j=2}^{l^{u}} \lbrace \left[\sigma\left(\mathbf{v}(w)^{\top} \theta_{j-1}^{u}\right)\right]^{1-d_{j}^{u}} \cdot\left[1-\sigma\left(\mathbf{v}(w)^{\top} \theta_{j-1}^{u}\right)\right]^{d_{j}^{u}} \rbrace \\\\ &=\sum_{w \in \mathcal{C}} \sum_{u \in \text { Context }(w)} \sum_{j=2}^{l^{u}} \lbrace (1-d_{j}^{u}) \cdot \log [\sigma\left(\mathbf{v}(w)^{\top} \theta_{j-1}^{u}\right)]+d_{j}^{u} \cdot \log [1-\sigma\left(\mathbf{v}(w)^{\top} \theta_{j-1}^{u}\right)] \rbrace \end{array} \tag{4.7}
$$
同样,为下面梯度推导方便起见,将三重求和符号下花括号里的内容简记为 $\mathcal { L } ( w , u , j )$,即
$$\mathcal { L } ( w , u , j ) = \left( 1 - d _ { j } ^ { u } \right) \cdot \log \left[ \sigma ( \mathbf { v } ( w ) ^ { \top } \theta _ { j - 1 } ^ { u } ) \right] + d _ { j } ^ { u } \cdot \log \left[ 1 - \sigma \left( \mathbf { v } ( w ) ^ { \top } \theta _ { j - 1 } ^ { u } \right) \right]$$
至此,已经推导出对数似然函数的表达式 (4.7),这就是Skip-gram模型的目标函数。接下来同样利用随机梯度上升法对其进行优化,关键是要给出两类梯度。
首先考虑 $\mathcal{L}(w, u, j)$ 关于 $\theta_{j-1}^{u}$ 的梯度计算(与CBOW模型对应的推导完全类似类似)。
$$\frac { \partial \mathcal { L } ( w , u , j ) } { \partial \theta _ { j - 1 } ^ { u } } = \frac { \partial } { \partial \theta _ { j - 1 } ^ { u } } \lbrace \left( 1 - d _ { j } ^ { u } \right) \cdot \log \left[ \sigma \left( \mathbf { v } ( w ) ^ { \top } \theta _ { j - 1 } ^ { u } \right) \right] + d _ { j } ^ { u } \cdot \log \left[ 1 - \sigma \left( \mathbf { v } ( w ) ^ { \top } \theta _ { j - 1 } ^ { u } \right) \right] \rbrace$$
$$= \left( 1 - d _ { j } ^ { u } \right) \left[ 1 - \sigma \left( \mathbf { v } ( w ) ^ { \top } \theta _ { j - 1 } ^ { u } \right) \right] \mathbf { v } ( w ) - d _ { j } ^ { u } \sigma \left( \mathbf { v } ( w ) ^ { \top } \theta _ { j - 1 } ^ { u } \right) \mathbf { v } ( w )$$
$$= \lbrace \left( 1 - d _ { j } ^ { u } \right) \left[ 1 - \sigma \left( \mathbf { v } ( w ) ^ { \top } \mathbf { v } _ { j - 1 } ^ { u } \right) \right] - d _ { j } ^ { u } \sigma \left( \mathbf { v } ( w ) ^ { \top } \theta _ { j - 1 } ^ { u } \right) \rbrace \mathbf { v } ( w )$$
$$= \left[ 1 - d _ { j } ^ { u } - \sigma \left( \mathbf { v } ( w ) ^ { \top } \theta _ { j - 1 } ^ { u } \right) \right] \mathbf { v } ( w )$$
于是,$\theta _ { j - 1 } ^ { u }$ 的更新公式可写为
$$\theta _ { j - 1 } ^ { u } : = \theta _ { j - 1 } ^ { u } + \eta \left[ 1 - d _ { j } ^ { u } - \sigma \left( \mathbf { v } ( w ) ^ { \top } \theta _ { j - 1 } ^ { u } \right) \right] \mathbf { v } ( w )$$
接下来考虑 $\mathcal { L } ( w , u , j )$ 关于 $\mathbf { v } ( w )$ 的梯度。同样利用 $\mathcal { L } ( w , u , j )$ 中 $\mathbf { v } ( w )$ 和 $\theta _ { j - 1 } ^ { w }$ 的对称性,有
$$\frac { \partial \mathcal { L } ( w , u , j ) } { \partial \mathbf { v } ( w ) } = \left[ 1 - d _ { j } ^ { u } - \sigma \left( \mathbf { v } ( w ) ^ { \top } \theta _ { j - 1 } ^ { u } \right) \right] \theta _ { j - 1 } ^ { u }$$
于是,$\mathbf { v } ( w )$ 的更新公式可以改写为
$$\mathbf { v } ( w ) : = \mathbf { v } ( w ) + \eta \sum _ { u \in C o n t e x t ( w ) } \sum _ { j = 2 } ^ { l ^ { u } } \frac { \partial \mathcal { L } ( w , u , j ) } { \partial \mathbf { v } ( w ) }$$
下面以样本 $( w , Context ( w ) )$ 为例,给出 Skip-gram 模型采用随机梯度上升法更新各参数的伪代码

但是, word2vec 源码中,并不是等 $Context ( w )$ 中所有的词处理完后才刷新 $\mathbf { v } ( w )$ ,而是每处理完 $Context ( w )$ 中的一个词 $u$ ,就及时刷新一次 $\mathbf { v } ( w )$,具体为

同样,需要注意的是,循环体内的步3和步4不能交换次序,即 $\theta_{j-1}^{u}$ 要等贡献到 $e$ 后才更新。
基于 Negative Sampling 的模型
本节将介绍基于 Negative Sampling 的 CBOW 和 Skip-gram 模型。Negative Sampling(简称为 NEG)是 Tomas Mikolov 等人在文 《Distributed Representations of Words and Phrases and their Compositionality》 中提出的,它是 NCE (Noise ContrastiveEstimation)的一个简化版本,目的是用来提高训练速度并改善所得词向量的质量。与 Hierarchical Softmax 相比,NEG不再使用使用(复杂的) Huffman树 ,而是利用(相对简单的)随机负采样,能大幅度提高性能,因而可作为 Hierarchical Softmax 的一种替代。
注5.1 NCE的细节有点复杂,其本质是利用已知的概率密度函数来估计未知的概率密度函数。简单来说,假设未知的概率密度函数为 $X$,已知的概率密度为 $Y$,如果得到了$X$ 和 $Y$ 的关系,那么 $X$ 也就可以求出来了。具体可参考文献 《Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics》。
CBOW 模型
在 CBOW 模型中,已知词 $w$ 的上下文 $Context(w)$,需要预测 $w$,因此,对于给定的 $Context(w)$,词 $w$ 就是一个正样本,其它词就是负样本了。负样本那么多,该如何选取呢?这个问题比较独立,我们放到后面再进行介绍。
假定现在已经选好了一个关于 $w$ 的负样本子集 $N E G(w) \neq \emptyset$ 。且对 $\forall \widetilde{w} \in \mathcal{D}$ ,定义
$$
L^{w}(\widetilde{w})=\left\lbrace \begin{array}{llll}{1,} & {\widetilde{w}=w} \\ {0,} & {\widetilde{w} \neq w}\end{array} \right.
$$
表示词 $\tilde{\omega}$ 的标签,即正样本标签为1,负样本标签为0。
对于一个给定的正样本 $(\text {Context}(w), w)$,我们希望最大化
$$
g(w)=\prod_{u \in{w} \cup N E G(w)} p(u | Context(w)) \tag{5.1}
$$
其中
$$
p(u | \text { Context }(w))=\begin{cases} {\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right),} & {L^{w}(u)=1} \\ {1-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right),} & {L^{w}(u)=0}\end{cases}
$$
或者写成整体表达式
$$
p(u | \text { Context }(w))=[\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)]^{L^{w}(u)} \cdot[1-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)]^{1-L^{w}(u)} \tag{5.2}
$$
这里 $\mathbf{X}_ w$ 仍表示 $Context (w)$ 中各词的词向量之和,而 $\theta^{u} \in \mathbb{R}^{m}$ 表示词 $u$ 对应的一个(辅助)向量,为待训练参数。
为什么要最大化 $g(w)$ 呢?让我们先来看看 $g(w)$ 的表达式,将(5.2)带入(5.1),有
$$
g(w)=\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{w}\right) \prod_{u \in N E G(w)}[1-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)]
$$
其中 $\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{w}\right)$ 表示当上下文为 $Context(w)$ 时,预测中心词为 $w$ 的概率,而 $\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{w}\right), u \in N E G(w)$ 则表示当上下文为 $Context(w)$ 时,预测中心词为 $u$ 的概率(这里可看成一个ニ分类问题,具体可参见预备知识中的逻辑回归)。从形式上看,最大化 $g(w)$,相当于最大化 $\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{w}\right)$ ,同吋最小化所有的 $\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right), u \in N E G(w)$ 。这不正是我们希望的吗?増大正样本的概率同时降低负样本的概率。于是,对于一个給定的语料库 $C$,函数
$$
G=\prod_{w \in \mathcal{C}} g(w)
$$
就可以作为整体优化的目标。当然,为计算方便,对 $G$ 取对数,最终的目标函数(为和前面章节统一起见,这里仍将其记为$\mathcal{L}$)就是
$$
\begin{array}{llll} \mathcal{L} &=\log G=\log \prod_{w \in \mathcal{C}} g(w)=\sum_{w \in \mathcal{C}} \log g(w) \\\\ &=\sum_{w \in \mathcal{C}} \log \prod_{u \in{w} \cup N E G(w)}\lbrace \left[\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right]^{L^{w}(u)} \cdot\left[1-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right]^{1-L^{w}(u)}\rbrace \\\\ &=\sum_{w \in \mathcal{C}} \sum_{u \in{w} \cup N E G(w)}\lbrace L^{w}(u) \cdot \log \left[\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right]+\left[1-L^{w}(u)\right] \cdot \log \left[1-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right]\rbrace \end{array} \tag{5.3}
$$
将上式进行改写可得
$$
\begin{array}{llll} \mathcal{L} &=\sum_{w \in \mathcal{C}} \sum_{u \in{w} \cup N E G(w)}\lbrace L^{w}(u) \cdot \log \left[\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right]+\left[1-L^{w}(u)\right] \cdot \log \left[1-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right]\rbrace \\\\ &=\sum_{w \in \mathcal{C}}\lbrace \log \left[\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{w}\right)\right]+\sum_{u \in N E G(w)} \log \left[1-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right]\rbrace \\\\ &=\sum_{w \in \mathcal{C}}\lbrace \log \left[\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{w}\right)\right]+\sum_{u \in N E G(w)} \log \left[\sigma\left(-\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right]\rbrace \end{array}
$$
上式中花括号中的项就是 Tomas Mikolov 等人在论文中提到的目标函数。
为下面梯度推导方便起见,将(5.3)式中花括号里的内容记为 $\mathcal{L}(w, u)$,即
$$
\mathcal{L}(w, u)=L^{w}(u) \cdot \log \left[\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right]+\left[1-L^{w}(u)\right] \cdot \log \left[1-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right] \tag{5.4}
$$
接下来利用随机梯度上升法对(5.3)进行优化,关键是要给出 $\mathcal{L}$ 的两类梯度。首先考虑 $\mathcal{L}(w, u)$ 关于 $\theta^{u}$ 的梯度计算。
$$
\begin{array}{llll} \frac{\partial \mathcal{L}(w, u)}{\partial \theta^{u}} &=\frac{\partial}{\partial \theta^{u}}\lbrace L^{w}(u) \cdot \log \left[\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right]+\left[1-L^{w}(u)\right] \cdot \log \left[1-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right]\rbrace \\ &=L^{w}(u)\left[1-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right] \mathbf{x}_ {w}-\left[1-L^{w}(u)\right] \sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right) \mathbf{x}_ {w} \\ &=\lbrace L^{w}(u)\left[1-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right]-\left[1-L^{w}(u)\right] \sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\rbrace \mathbf{x}_ {w} \\ &=\left[L^{w}(u)-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right] \mathbf{x}_ {w} \end{array}
$$
于是,$\theta^{u}$ 的更新公式可写为
$$
\theta^{u}:=\theta^{u}+\eta\left[L^{w}(u)-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right] \mathbf{x}_ {w}
$$
接下来考虑 $\mathcal{L}(w, u)$ 关于 $\mathbf{X}_ {w}$ 的梯度。同样利用 $\mathcal{L}(w, u)$ 中 $\mathbf{X}_ {w}$ 和 $\theta^{u}$ 的对称性,有
$$
\frac{\partial \mathcal{L}(w, u)}{\partial \mathbf{x}_ {w}}=\left[L^{w}(u)-\sigma\left(\mathbf{x}_ {w}^{\top} \theta^{u}\right)\right] \theta^{u}
$$
于是,利用 $\frac{\partial \mathcal{L}(w, u)}{\partial \mathbf{x}_ {w}}$,可得 $\mathbf{v}(\widetilde{w}), \widetilde{w} \in Context(w)$ 的更新公式为
$$
\mathbf{v}(\widetilde{w}):=\mathbf{v}(\widetilde{w})+\eta \sum_{u \in{w} \cup N E G(w)} \frac{\partial \mathcal{L}(w, u)}{\partial \mathbf{x}_ {w}}, \quad \widetilde{w} \in \text { Context }(w)
$$
下面以样本 $(\text {Context}(w), w)$ 为例,给出基于 Negative Sampling 的 CBOW 模型中采用随机梯度上升法更新各参数的伪代码

