实验简介
Hadoop 是什么
Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构。主要解决海量数据的存储和海量数据的分析计算问题。广义上来说 HADOOP 通常是指一个更广泛的概念—— HADOOP 生态圈。
Hadoop 的优势:
高可靠性:因为 Hadoop 假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。高效性:在 MapReduce 的思想下, Hadoop 是并行工作的,以加快任务处理速度。高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
Hadoop 组成:
Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。Hadoop MapReduce: 一个分布式的离线并行计算框架。Hadoop YARN: 作业调度与集群资源管理的框架。Hadoop Common:支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)。
实验任务说明
本文意在通过 hadoop 集群,完成贝叶斯文本分类的任务。
有关利用 朴素贝叶斯算法 进行文本分类的原理参见上节内容,这里不做过多说明。
本实验是在 Windown 8 操作系统下,通过搭建 VMware Workstation 虚拟机的方式进行 hadoop 集群的部署。本次实验部署了 3 台 hadoop 虚拟机的节点,集群部署规划如下表:
| hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager |
NodeManager |
有关于虚拟机安装与 hadoop 集群环境搭建这里略。
贝叶斯分类器任务框架
数据集简介
数据集文件夹为 NBCorpus,里面一共两个子文件夹 Country 和 Industry,实验要求从中选取一个完成即可。
Country 和 Industry 下每个子目录就是一个文档类别,但有的子目录下文件非常少,因此要选择文件比较多的目录(至少二个)进行训练和测试。
每个文件已经分好词,一行一个单词。
训练集和测试集的选取
我在数据集中选择了 Country 文件夹下的 CHINA 和 CANA 作为本次实验的样本,其中 CHINA 类中包含 255 个文本,CANA 类中包含 263 个文本。按照 70% 与 30% 的比例选取训练集和测试集。表格如下:
| CHINA | CANA | |
|---|---|---|
| 文档总数 | 255 | 263 |
| 训练集数 | 178 | 184 |
| 测试集数 | 77 | 79 |
手动随机抽取相应数量的文档放入相应的数据输入路径,训练集与测试集相应的路径如下所示:
e:/INPUT/TRAIN/CHINA/,训练集类CHINA文档路径e:/INPUT/TRAIN/CANA/,训练集类CANA文档路径e:/INPUT/TEST/CHINA/,测试集类CHINA文档路径e:/INPUT/TEST/CANA/,测试集类CANA文档路径
实验任务分解
Bayes 分类器的 MapReduce 实现分为 训练 和 测试 两个阶段。
其中 训练 阶段需要编写两个 MapReduce 任务,MapReduce 任务一 完成计算文档 d 出现在类 c 中的先验概率的所需数据,我将该阶段称为 训练先验概率 阶段;MapReduce 任务二 完成计算词项 t 出现在类 c 中的条件概率的所需数据,我将该阶段称为 训练条件概率 阶段。
其中 测试 阶段需要编写一个 MapReduce 任务三,用于完成 预测 测试集中文档所属的类别,我将其称为 预测 阶段。另外还要编写一个java程序,用于对 任务三 中预测的结果进行 评估,我将其称为 评估 阶段。
实验任务所有代码均在 eclipse 编辑器中完成。我在 eclipse 创建了一个名为 Naive Bayes 的 project,src 文件夹下创建三个 package,分别取名为 DocCount,WordCount 以及 Predition,分别用于完成 MapReduce 任务一、MapReduce 任务二 以及 MapReduce 任务三。最后的 评估 阶段代码写在了 Predition 这个包中。项目中的代码结构如下图所示:
MapReduce 任务一 训练先验概率
任务说明
- 需要编写一个单独的
MapReduce Job,计算结果写入文件; - 实现一个自定义的
InputFormat和RecordReader,每读取一个文件(实际上不需要读取文件内容),输出<ClassName,1>,其中ClassName为读取的文件所在的类别目录名,<ClassName,1>为Map的输入,Map不做任何处理,直接输出<ClassName,1>; Map的输出交给Combine处理,Combine的输入为<ClassName,{1,1,...,1}>,在Combine中计算1的个数,所以Combine的输出为<ClassName,Count>,Count为属于ClassName类别的文档个数,但是局部的;Combine的输出交给Reducer,Reducer的输入为<ClassName,{count1,count2, ..., countn}>,在Reduce里对count1,count2,…,countn求和,就得到了ClassName的总数TotalCount,Reducer的输出为<ClassName,TotalCount>并写到文件;- 该作业主要统计了每种类别文档的总数目,具体概率的计算放在了后面。作业的输出会产生多个文件,取决于
Reducer的个数,每个文件里一行的格式为:类名 文档总数
代码目录
DocCount
DocCountDriver.java: 主程序入口DocCountMapper.java: 实现Map阶段DocCountReducer.java: 实现Reduce阶段WholeFileInputFormat.java: 重写的InputFormat类WholeRecordReader.java: 重写的RecordReader类
重写 InputFormat 与 RecordReader
之所以要重写这个类,主要是因为 hadoop 中默认的 MapReduce 程序,每一个 Map 任务的调用输入的 key 为文档中每一行行号,数据类型为 LongWritable;value 为文档中的一行内容,数据类型为 Text。但是第一任务,我们要求每一个 Map 任务处理一个文档,而不是文档中的每一行记录,所以需要对 InputFormat 与 RecordReader 这两个类进行重写,以符合任务的需求。
重写的 InputFormat 的类文件 WholeFileInputFormat.java 内容如下:
1 | package DocCount; |
重写的 RecordReader 的类文件 WholeRecordReader.java 内容如下:
1 | package DocCount; |
MapReduce 任务
设计的 Map 任务程序 DocCountMapper.java 代码如下:
1 | package DocCount; |
设计的 Reduce 任务程序 DocCountReducer.java 代码如下:
1 | package DocCount; |
main 函数入口
对于程序的入口,我们专门写了一个类进行 main() 封装,命名为 Driver,程序 DocCountDriver.java 代码如下:
1 | package DocCount; |
程序运行结果
程序运行过程如图所示:
程序运行结束如图所示:
程序输出文件如图所示:
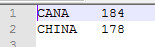
程序输出数据内容如下:
MapReduce 任务二 训练条件概率
任务说明
- 需要编写一个单独的MapReduce Job ,计算结果写入文件;
- 实现一个自定义的
Writable类型,要求Map每读取一个文件中的一行(一个单词),输出<<ClassName,Term>,1>,其中key为<ClassName,Term>,ClassName为读取的文件所在的类别目录名,Term为单词,1表示Term在ClassName的类里出现一次; Map的输出交给Combine处理,Combine的输入<<ClassName,Term>,{1,1,...,1}>,在Combine中计算1的个数,所以Combine的输出为<<ClassName,Term>,Count>,Count为Term在ClassName的类里出现的次数,但是局部的;Combine的输出交给Reducer,Reducer的输入为<<ClassName,Term>,{count1,count2,...,countn}>,在Reduce里把count1,count2,…,countn求和,就得到了Term在ClassName的类里出现的总次数TotalCount;Reduce输出<<ClassName,Term>,TotalCount>;- 该作业只统计了每个
<ClassName,Term>对出现的总次数,具体条件概率计算放在了后面。作业的输出会产生多个文件,取决于Reducer的个数,每个文件里一行的格式为:类名 单词 出现次数
代码目录
WordCount
WordCountDriver.java: 主程序入口WordCountMapper.java: 实现Map阶段WordCountReducer.java: 实现Reduce阶段TextPair.java:重写Wtrtable类,自定义一个<Text,Text>的数据类型
定义新的数据类型
Map 任务需要输出的键值为 <ClassName,Term>,然而我查了下 hadoop 的数据类型,如下表:
| Java | Hadoop Writable |
|---|---|
| boolean | BooleanWritalbe |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| string | Text |
| map | MapWritable |
| array | ArrayWritable |
上表中,左侧为 java 的数据类型,右侧为 hadoop 默认的数据类型,每行存储的数据是一样的,只不过一个是 java 的类,一个是 hadoop 的类。
看了下数据类型,只有 MapWritable 满足要求,因为要求输出为键值对形式。无奈这个类不太会用,程序各种编译不通过,所幸重新写了一个自定义的数据类型,取名为 TextPair,文件 TextPair.java 代码如下:
1 | package WordCount; |
MapReduce 任务
设计的 Map 任务程序 WordCountMapper.java 代码如下:
1 | package WordCount; |
设计的 Reduce 任务程序 WordCountReducer.java 代码如下:
1 | package WordCount; |
main 函数入口
main() 写在 WordCountDriver.java 中,代码如下:
1 | package WordCount; |
程序运行结果
程序运行过程如图所示:
程序运行结束如图所示:
程序输出文件如图所示:
程序输出数据内容如下:
MapReduce 任务三 预测
任务说明
- 预测前将训练得到文件加载到内存里,计算先验概率和每个类别里单词出现的条件概率,可以交给自定义
Mapper类和自定义Reducer类的包装类Prediction来处理,在Prediction类里定义成类变量来保存这些学习到的概率,这样Mapper类和Reducer类都可以访问到这些概率。保存这些概率的数据结构应该用HashTable,这样可以高效地读取所需的概率值; - 在
Prediction类实现一个静态方法,计算一个文档属于某类的条件概率P(class|doc),该方法无需用MapReduce实现,需要计算其中每个单词出现的频率,该方法命名为conditionalProbabilityForClass; - 每读取一个文件,这里需要把文件内容作为一个整体读取成为一个
String,产生<docId,content>作为Map的输入; - 在
Map里写一个for循环,对于每一个类别c在循环中调用conditionalProbabilityForClass函数,得到<docId,<ClassName,Prob>>,作为Map的输出。因此Map的输入为<docId,content>,Map的输出为list<docId,<ClassName,Prob>>; Reduce任务输入为<docId,list<ClassName,Prob>>,找到最大的Prob,输出<docId,最大Prob对应的ClassName>。
代码目录
Predition
PredictDriver.java: 主程序入口PredictMapper.java: 实现Map阶段PredictReducer.java: 实现Reduce阶段PredictTestInputFormat.java: 重写的InputFormat类PredictTestRecordReader.java: 重写的RecordReader类Prediction.java: 封装类,用于保存学习到的先验概率和条件概率,并定义一个方法实现P(c|d)的计算,并给Map调用
封装类说明
Prediction.java 用于在 MapReduce 运行之前,对之前的任务的运行结果进行预处理,之前的运行结果主要存放在 "e:/z_output_doc/" 和 "e:/z_output_word/" 下。将其数据取出,分别用于计算该文档 d 属于类 c 的先验概率 P(c),以及在类 c 中单词 t 出现的条件概率 p(t|c),并将计算结果存入相应的哈希表 class_prob 和 class_term_prob 中。并定义一个方法实现 P(c|d) 的计算,传给 Map 调用。封装类 Prediction.java 代码如下:
1 | package Predition; |
重写 InputFormat 与 RecordReader
之所以要重写这个类,原因前面做 MapReduce 任务一 说过,默认的类不满足任务需求,我们要求给 Map 的出入为整个文档的内容,并以字符串的形式传递,所以要进行改写。
重写的 InputFormat 的类文件 PredictTestInputFormat.java 内容如下:
1 | package Predition; |
重写的 RecordReader 的类文件 PredictTestRecordReader.java 内容如下:
1 | package Predition; |
MapReduce 任务
设计的 Map 任务程序 PredictMapper.java 代码如下:
1 | package Predition; |
设计的 Reduce 任务程序 PredictReducer.java 代码如下:
1 | import java.io.IOException; |
main 函数入口
main() 写在 PredictDriver.java 中,代码如下:
1 | package Predition; |
程序运行结果
程序运行过程如图所示:
程序运行结束如图所示:
程序输出文件如图所示:
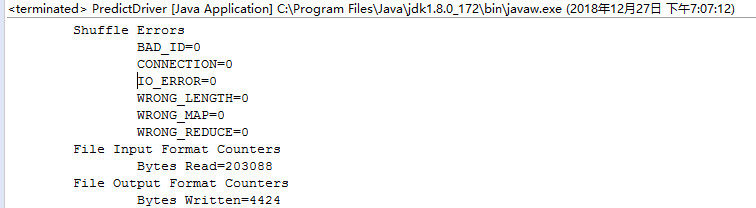
程序输出数据内容如下:
评估
任务说明
- 根据
MapReduce 任务三的预测结果,计算每一个类别的精确率与召回率; - 类别超过一个,评估算法对于所有类别的精确率与召回率的宏平均与微平均指标。
代码目录
Predition
Evaluation.java: 该类主要计算预测的评估指标
预测代码实现
Evaluation.java 代码内容如下:
1 | package Predition; |
运行结果
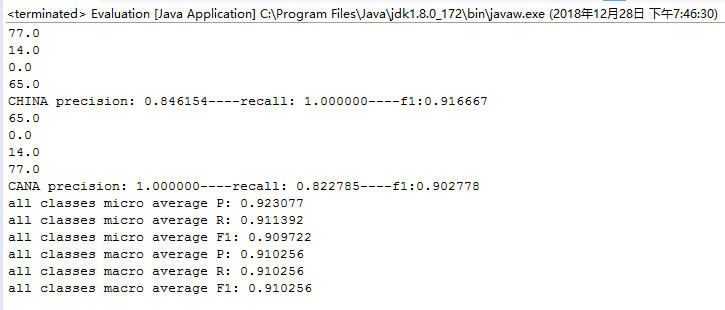
运行结果如下图所示:
对上表进行整理,结果如下:
| CHINA | Yes(Ground Truth) | No(Ground Truth) |
|---|---|---|
| Yes(Classified) | 77 | 14 |
| No(Classified) | 0 | 65 |
CHINA 类的精确率为 0.8461,CHINA 类的召回率为 1.00,F1值为 0.9167 。
| CANA | Yes(Ground Truth) | No(Ground Truth) |
|---|---|---|
| Yes(Classified) | 65 | 0 |
| No(Classified) | 14 | 77 |
CANA 类的精确率为 1.00,CANA 类的召回率为 0.8228,F1值为 0.9028 。
微平均的计算结果为
P: 0.923077
R: 0.911392
F1: 0.909722
宏平均的计算结果为
P: 0.910256
R: 0.910256
F1: 0.910256
