虚拟机环境搭建
本机操作系统配置如下:
- linux 版本:CentOS Linux release 7.4.1708(Core)
运行命令cat /etc/redhat-release - cpu info:Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz
运行命令grep "model name" /proc/cpuinfo | cut -f2 -d: - cpu cores:4
运行命令cat /proc/cpinfo | grep "cpu cores" | uniq - MemTotal:7872792 kB
运行命令grep MemTotal /proc/meminfo - 位数:64
运行命令getconf LONG_BIT或echo $HOSTTYPE
安装 vmware
首先去官网下载 vmware ,根据系统版本选择 windows 或者 linux,我选择的 vmeare 版本是 VMware-Workstation-Full-14.1.3-9474260.x86_64.bundle 。
进入下载目录后,先给运行文件赋予执行权限,命令如下:1
sudo chmod +x VMware-Workstation-Full-14.1.3-9474260.x86_64.bundle
然后运行文件,命令如下:1
sudo ./VMware-Workstation-Full-14.1.3-9474260.x86_64.bundle
跳出安装界面,不断点击下一步,进行安装即可。
在 wmware 中安装 CentOS
进入 CentOS官网 找到相应的镜像,点击下载。
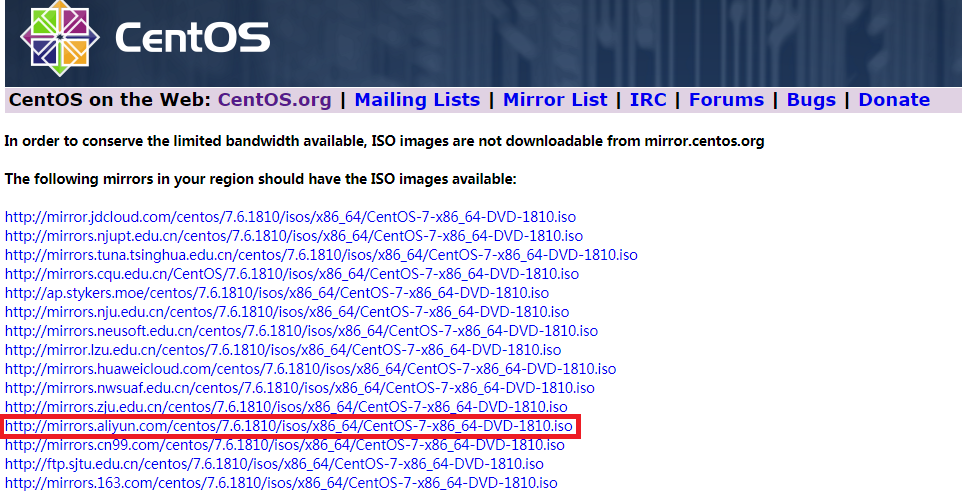
我选择的是阿里云的镜像。然后打开安装好的 wmware 软件
点击自定义安装

选择 Workstation 12.x 选项
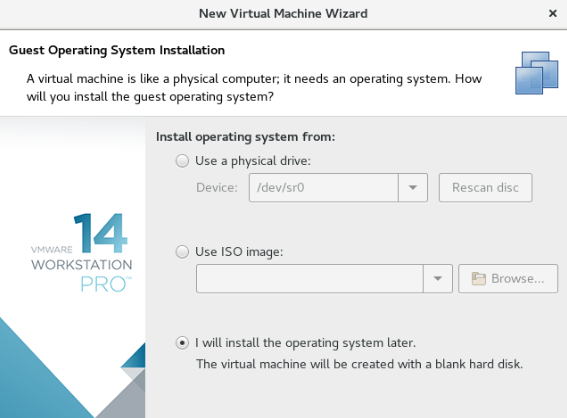
选择之后载入系统镜像(其实选择直接载入也是一样的)
选择相应的系统,与系统版本
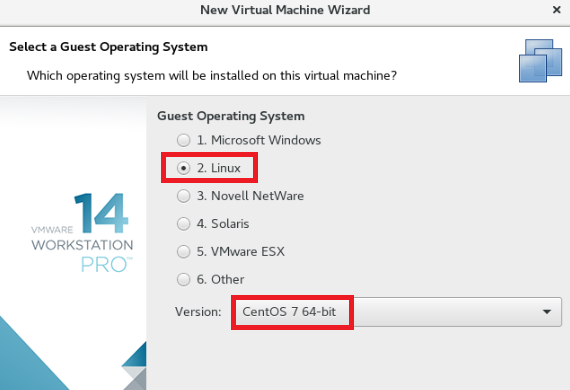
选择虚拟机安装目录
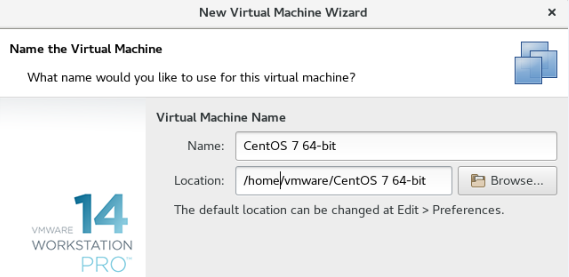
根据电脑系统情况,选择处理器和核数
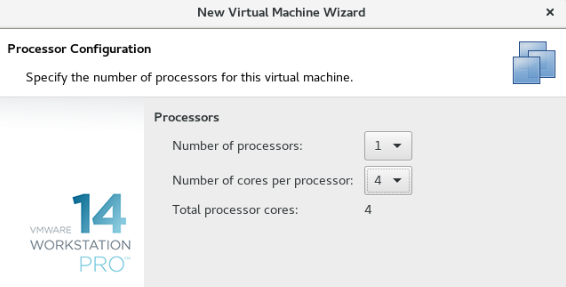
选择内存大小
添加网络类型
I/O控制器选择推荐的就好了
磁盘类型,同样选择推荐
创建新的虚拟盘

按需设置磁盘大小
指定磁盘文件
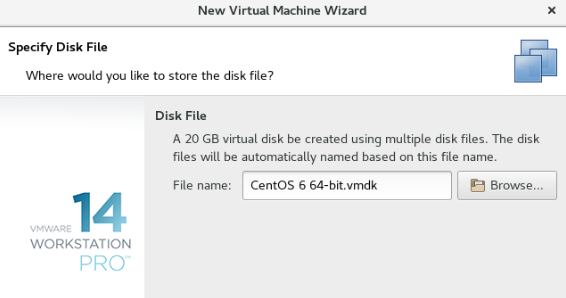
点击自定义硬件
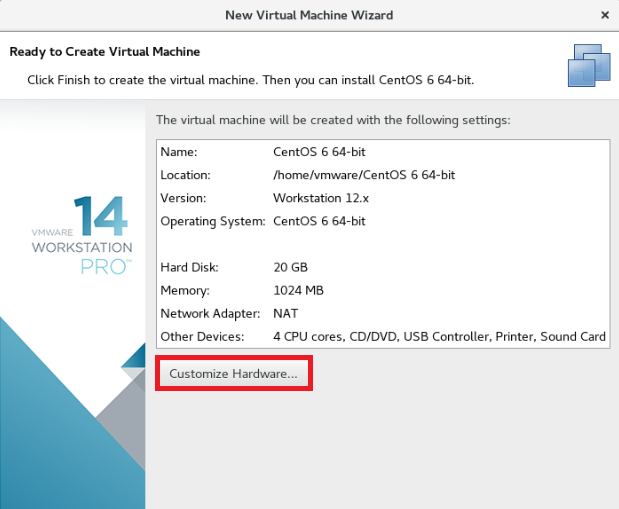
光驱中选择已经下载好的镜像文件,点击关闭
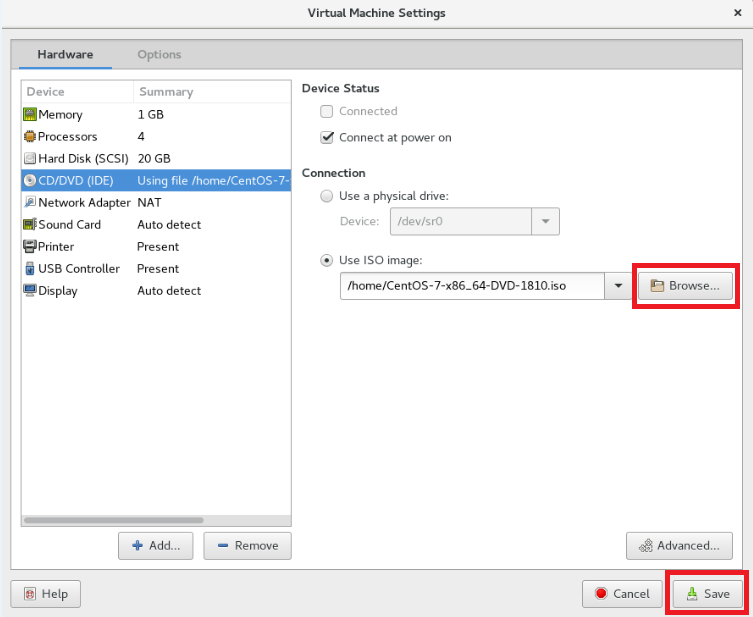
CentOS 启动初始化设置
启动虚拟机
选择语言
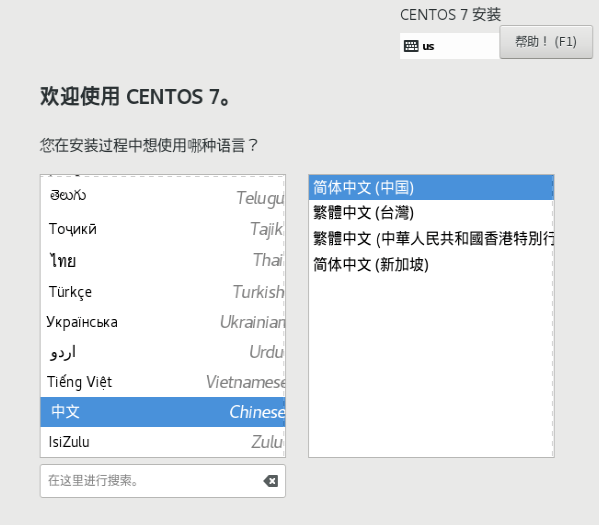
软件选择,不选默认是最小安装
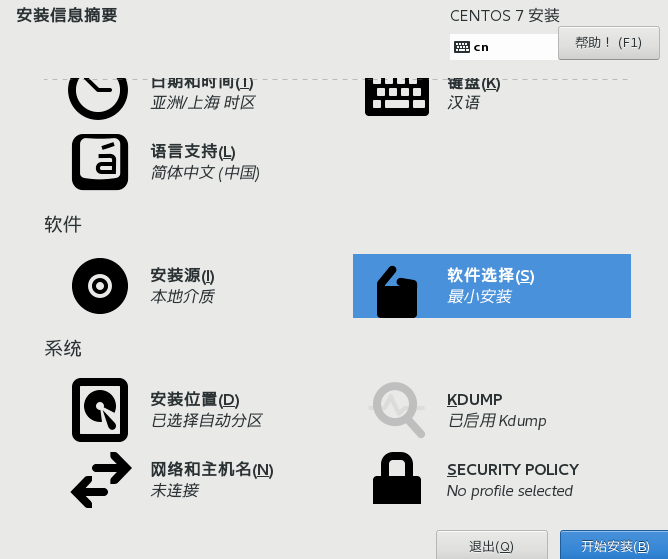
勾选图形化界面,有图形化比较好操作,如果 linux 窗口命令玩的溜也可以最小化安装
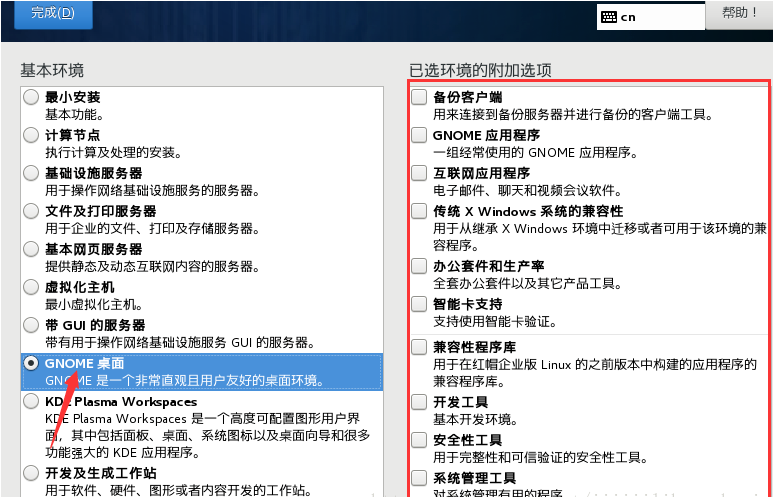
点击完成,点击开始安装,稍等大概 5 分钟左右,安装成功,期间设置 root 账户密码,user 账户密码
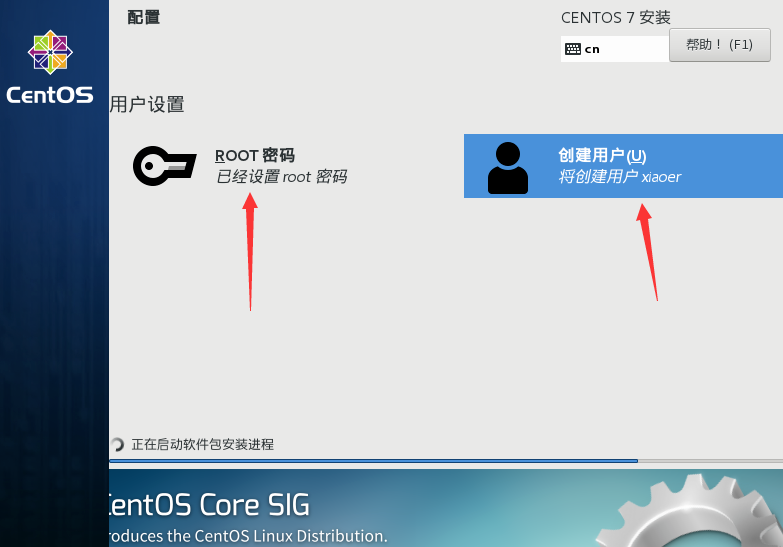
重启电脑,配置完成
安装 VMTools 工具
什么是 VM tools ? 顾名思义就是 Vmware 的一组工具。主要用于虚拟主机显示优化与调整,另外还可以方便虚拟主机与本机的交互,如允许共享文件夹,甚至可以直接从本机向虚拟主机拖放文件、鼠标无缝切换、显示分辨率调整等,十分实用。
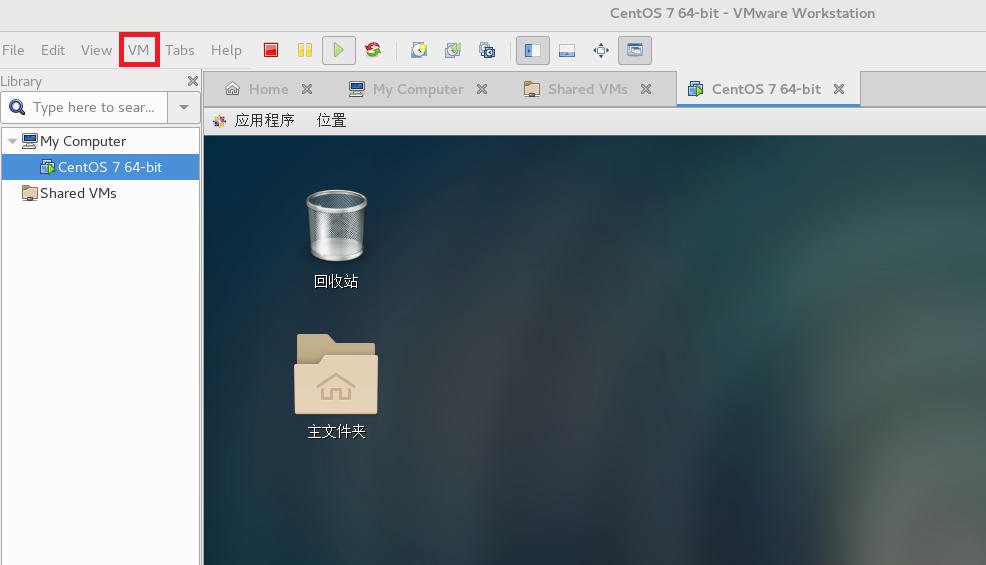
重启虚拟机后,点击左上角 VM 图标,选择 Install VMware Tools 选项
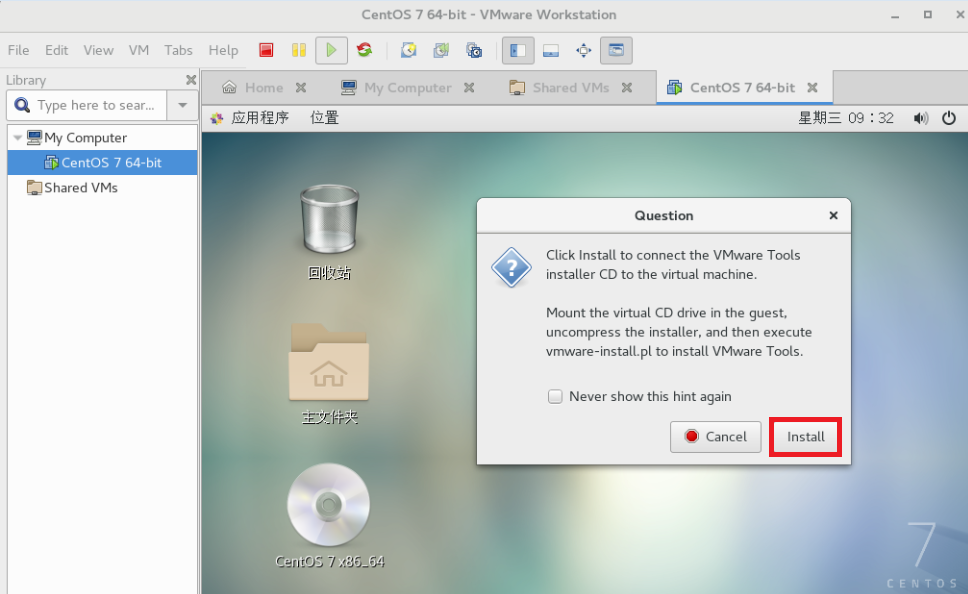
打开终端,使用 root 权限运行如下命令,挂载 CD-DVD
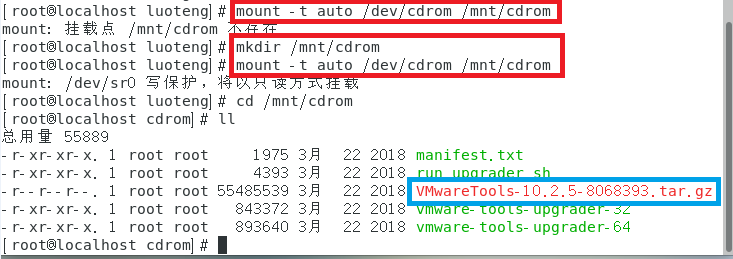
1 | >>> mount -t auto /dev/cdrom /mnt/cdrom |
若文件夹 /mnt/cdrom 不存在,手动创建一下,再次运行上述命令
进入挂载的文件夹 /mnt/cdrom 后运行命令 ll 查看文件内容,如下图
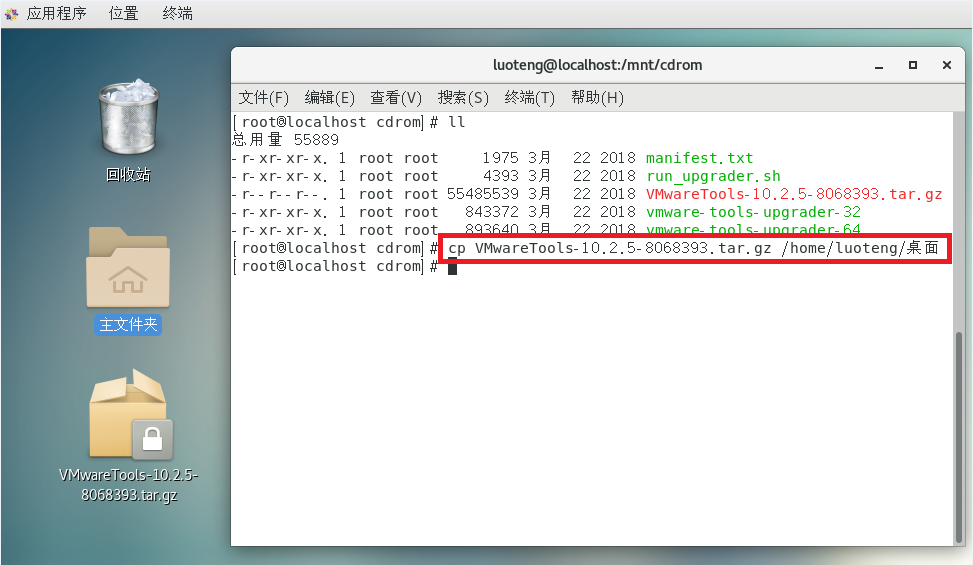
运行如下命令,文件 VMwareTools-10.2.5-8068393.tar.gz 保存到你希望存放的位置,我直接放在了桌面上1
>>> cp VMwareTools-10.2.5-8068393.tar.gz /home/luoteng/桌面
解压 VMwareTools 文件,运行如下命令或者鼠标右键文件选择解压1
>>> tar -zxvf VMwareTools-10.2.5-8068393.tar.gz
解压完成,进入解压后的文件夹 wmware-tools-distrib 如下图所示
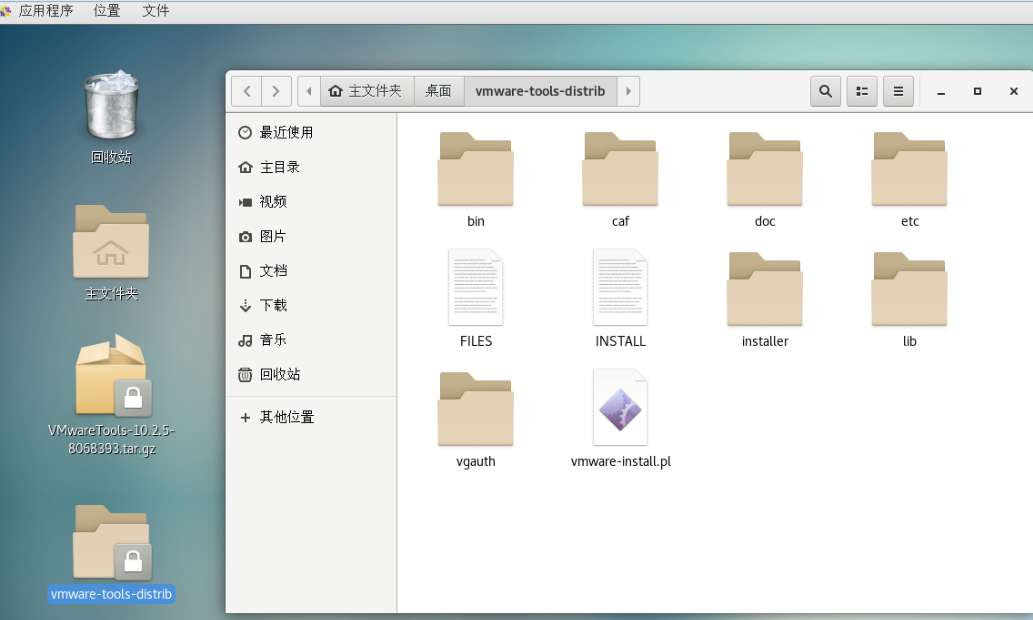
打开终端,首先进入解压文件目录,运行如下命令,进行安装1
2>>> cd wmware-tools-distrib
>>> ./vmware-install.pl
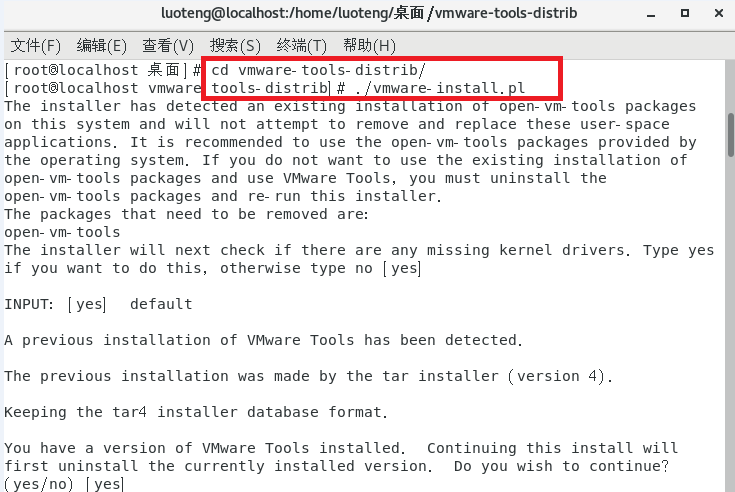
然后根据屏幕提示一路回车。到此整个安装过程算是完成了。
如果安装过程中出现问题,建议安装之前执行一下安装 GCC 和 PERL,命令如下:1
2
3>>> yum install perl gcc kernel-devel
>>> yun -y install kernel-devel-$(uname -r)
>>> yum -y install net-tools perl gcc gcc-c++
如下图:
图 04_07
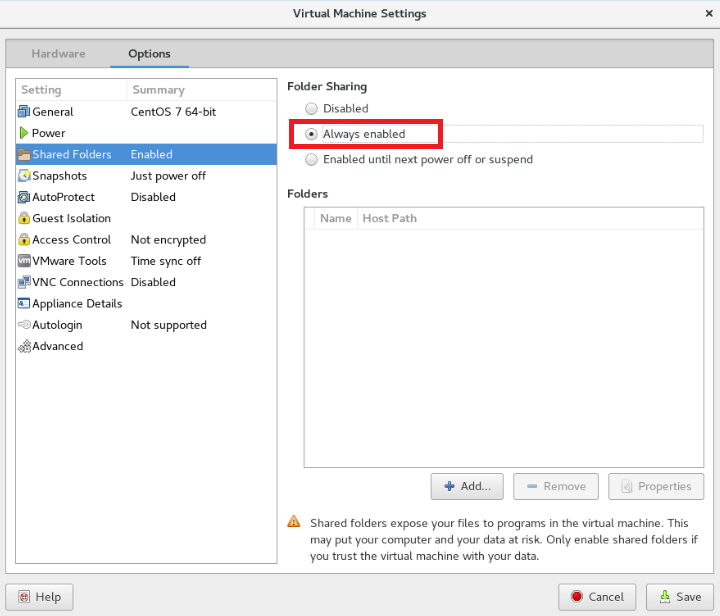
配置共享目录
点击左上角 VM 图标,选择 Settings 选项,选择 Always enabled
设置共享文件夹名字和路径,点击确定 OK ,然后保存 Save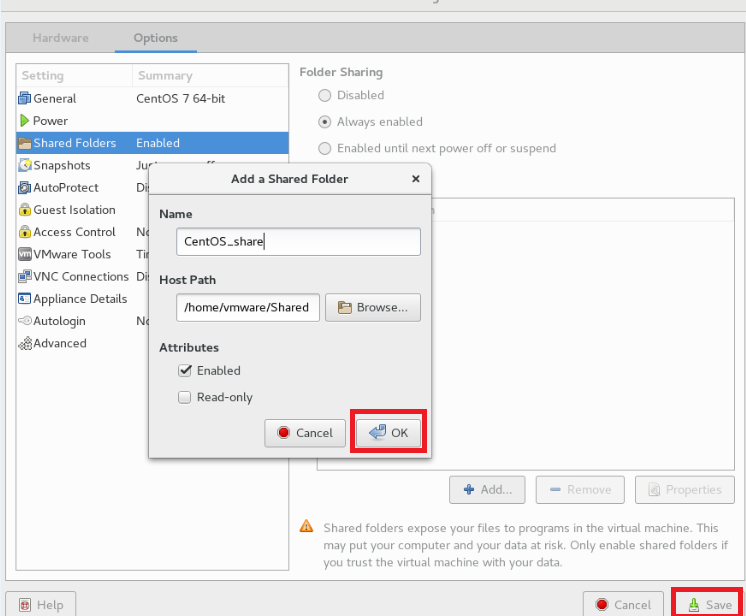
hadoop 运行环境搭建
克隆虚拟机
鼠标移至待复制的虚拟机上,右键 -> Manage -> Clone
创建完整克隆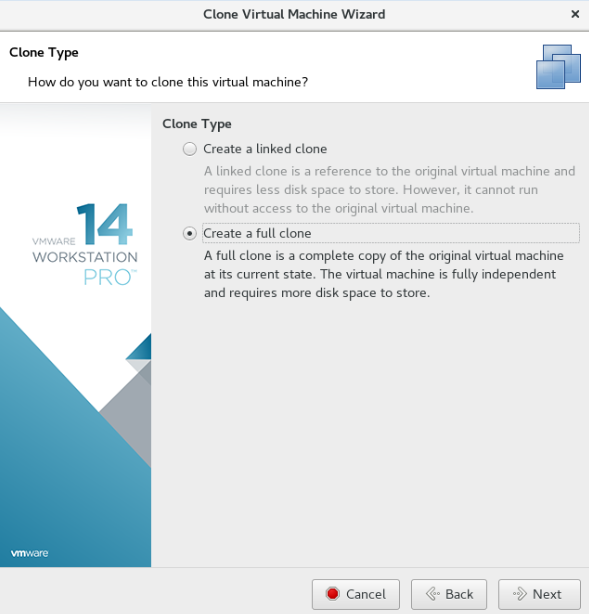
设置虚拟机名称和存放位置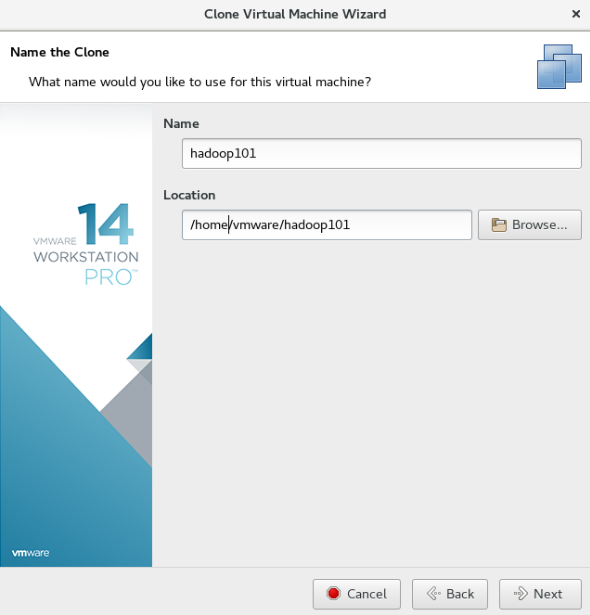
点击完成,等待几分钟,克隆完毕
配置网络
点击左上角 Edit 图标,选择 Virtual Network Editor 选项,查看 IP 地址是否设置正确,如下图
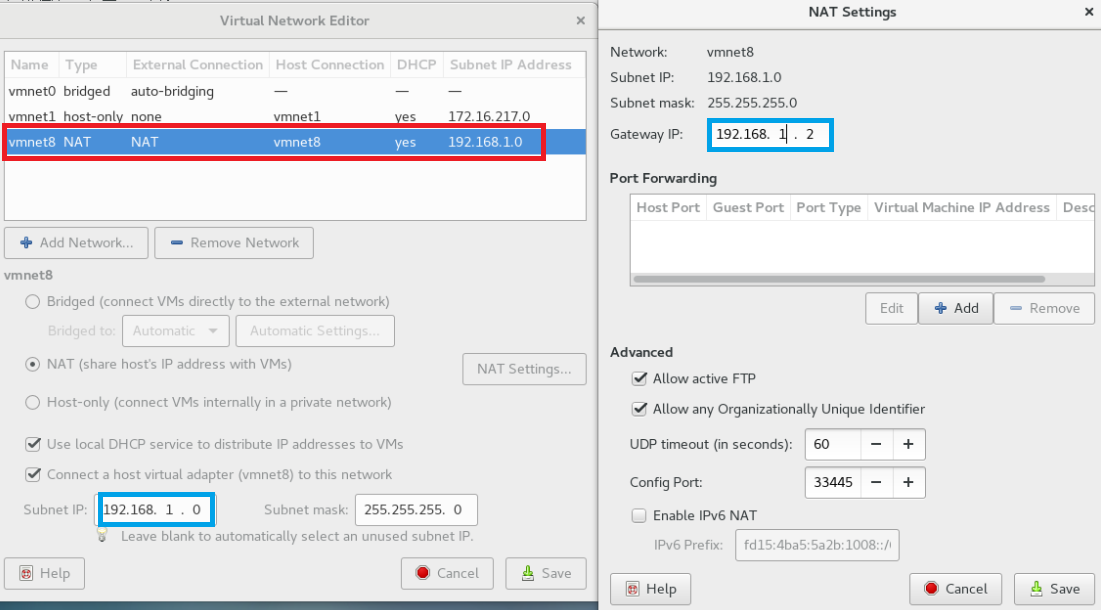
设置静态 ip
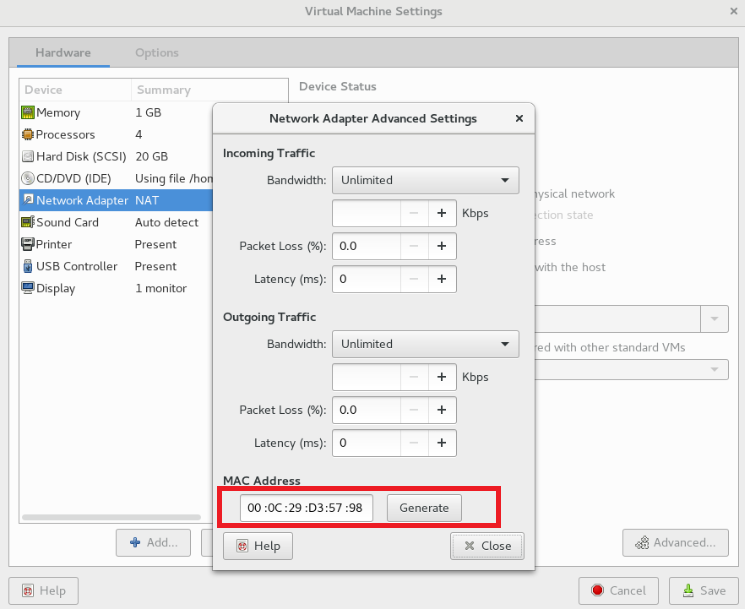
点击左上角 VM 图标,选择 Settings 选项,查看网络适配器中的物理地址,没有点击生成一个(必须关闭虚拟机才能生成),如下图
或者在终端运行命令 ifconfig 也可以查看,如下图
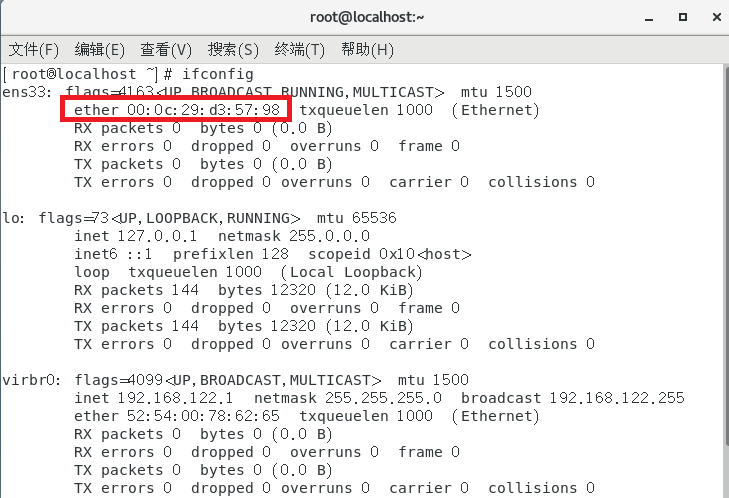
启动虚拟机,在终端命令窗口中输入如下命令,对文件进行修改(不同机器文件名 ens33 会有所不同):1
>>> vim /etc/sysconfig/network-scripts/ifcfg-ens33
需要修改的内容有 6 项
- HWADDR=00:0C:29:D3:57:98
- IPADDR=192.168.1.101
- GATEWAY=192.168.1.2
- ONBOOT=yes
- BOOTPROTO=static
- DNS1=8.8.8.8
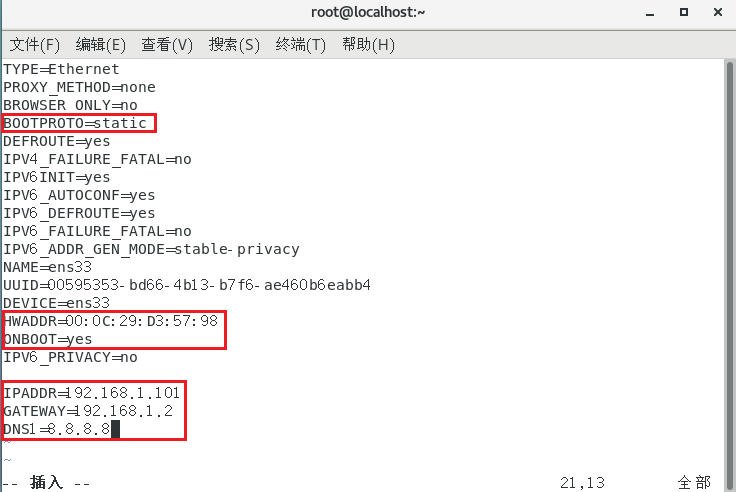
修改完成后退出,运行下面命令重启网络服务,然后重新启动虚拟机
1 | >>> service network restart |
修改主机名
修改 linux 的 hosts 文件,进入 Linux 系统查看虚拟机的主机名。通过 hostname 命令查看。
如果感觉此主机名不合适,我们可以进行修改。CentOS 6 通过编辑 /etc/sysconfig/network 文件, CentOS 7 通过编辑 /etc/hostname 文件。我将虚拟机主机名改为 hadoop101
1 | >>> vim /etc/hostname |
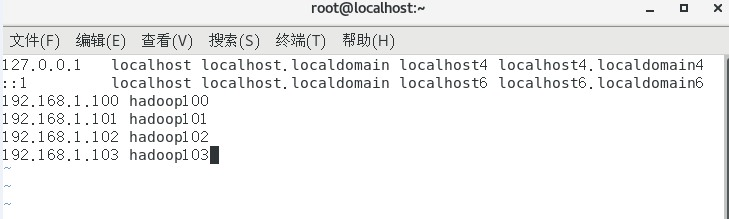
打开虚拟机的 /etc/hosts 文件,添加如下内容
- 192.168.1.100 hadoop100
- 192.168.1.101 hadoop101
- 192.168.1.102 hadoop102
- 192.168.1.103 hadoop103
1 | >>> vim /etc/hosts |
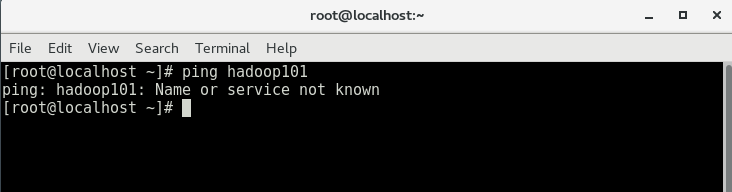
我们在主机的终端下运行一下 ping hadoop101 ,发现主机无法识别虚拟机的名称,如下图:
同样按照上面的方法修改下主机的 /etc/hosts 文件,如下图
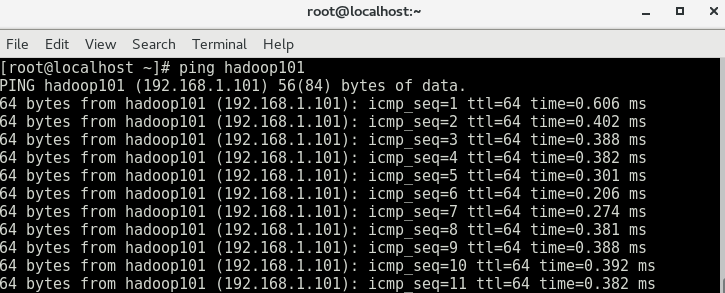
在运行一下命令 ping hadoop101 ,OK,主机与虚拟机已经能够连接,如图
关闭防火墙
查看防火墙开机启动状态1
>>> systemctl status firewalld
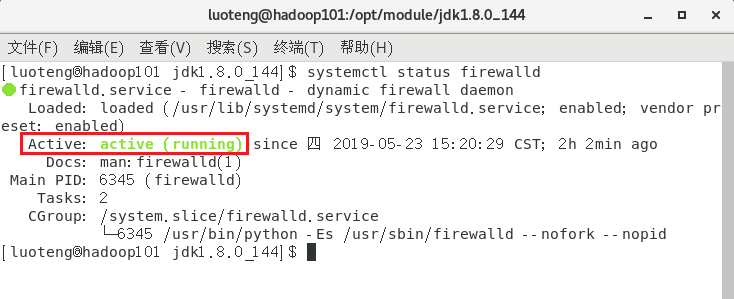
如图上方框所示,说明防火墙处于启动状态,运行下面第一条命令进行临时关闭(重启后又回到启动状态),运行下面第二条命令进行永久关闭(如果想恢复 disable 改为 enable)1
2>>> sudo systemctl stop firewalld
>>> sudo systemctl disable firewalld
运行命令后我们在看一下防火墙状态,如下图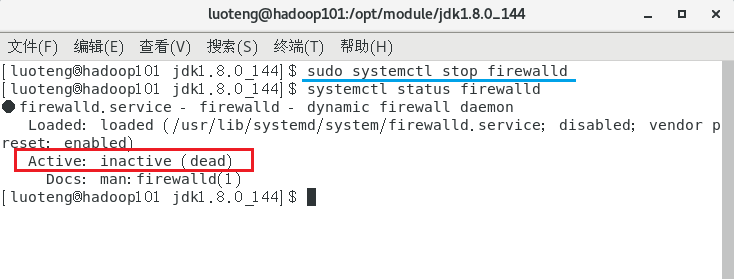
设置用户具有 root 权限
运行如下命令,进入相应文件1
>>> vim /etc/sudoers
修改以下内容,如图
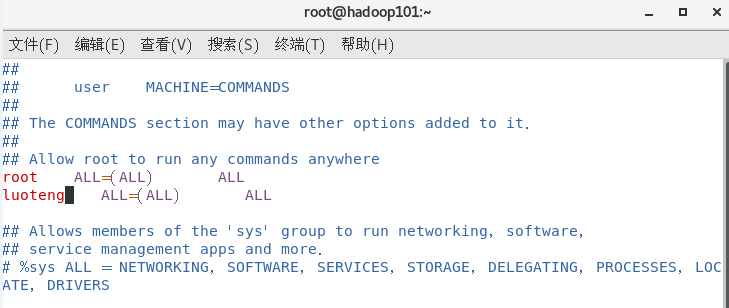
修改完毕,现在可以用 luoteng 帐号登录,然后用命令 su- ,即可获得 root 权限进行操作。
下载 jdk
若虚拟机自带 jdk 1.7 以上版本可以跳过下载和安装步骤。
首先进入Oracle官网,如下图
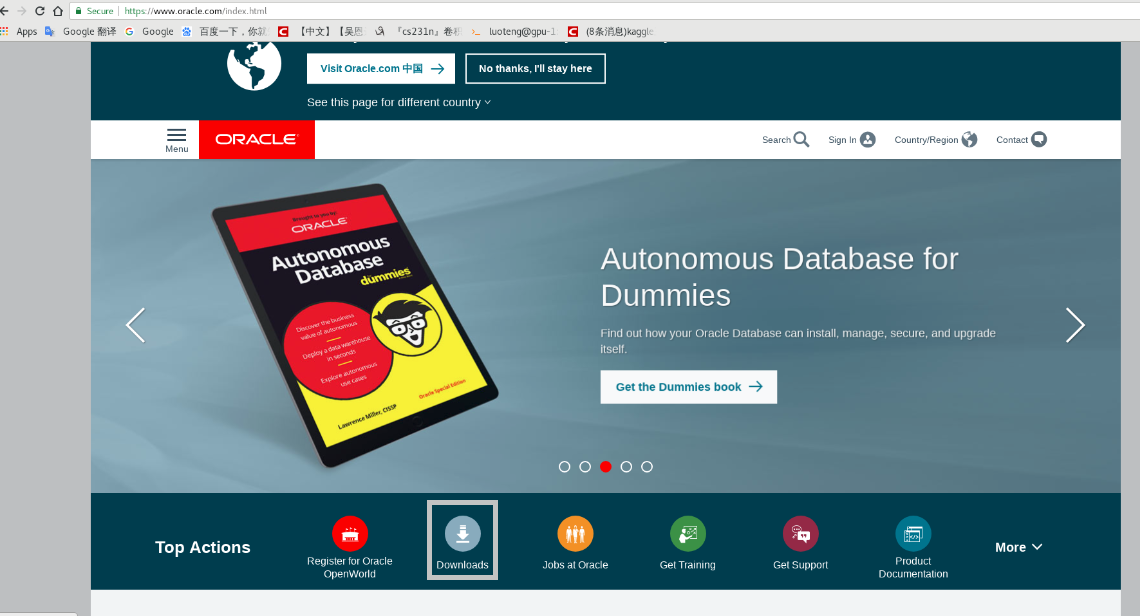
点击 Downloads 进入下载界面,如下图

点击 Java for Developers 进入下一页面,移动至最底端,如图
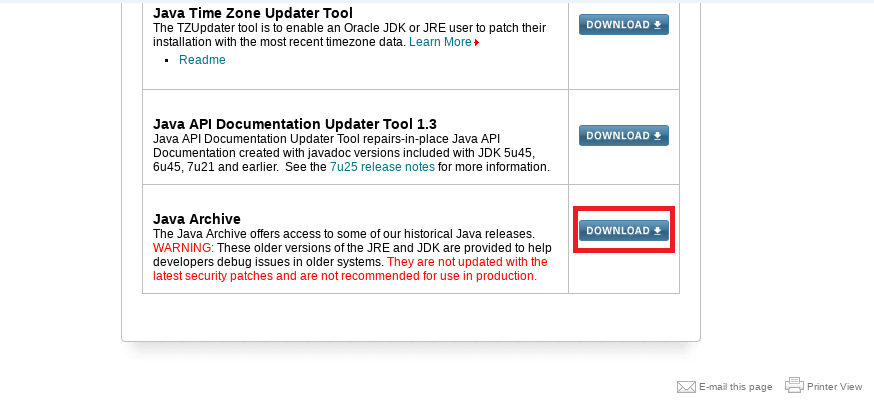
点击 DOWNLOAD ,找到 Java SE 8 历史版本页面入口,如图
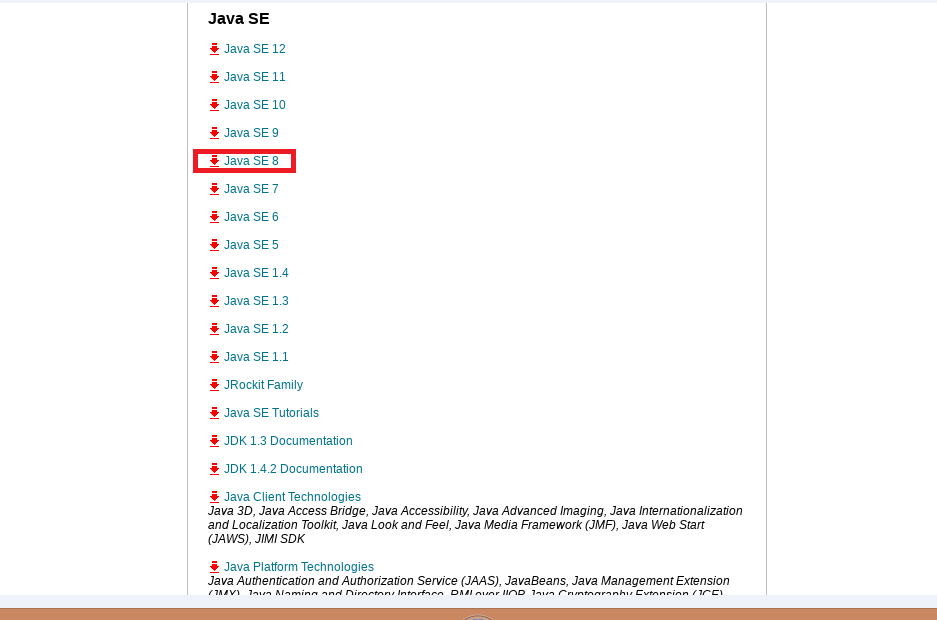
点击 Java SE 8 ,找到 jdk-8u144-linux-x64.tar.gz 进行下载,如下图所示
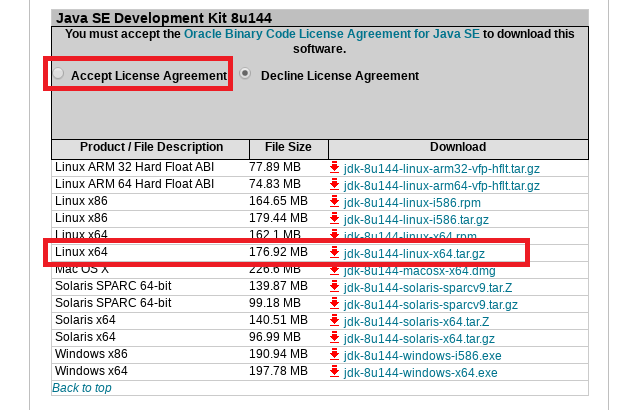
注意点击上方 Accept License Agreement 点的原圆点,否则无法下载资源,另外下载前需要注册一下 Oracle 账号
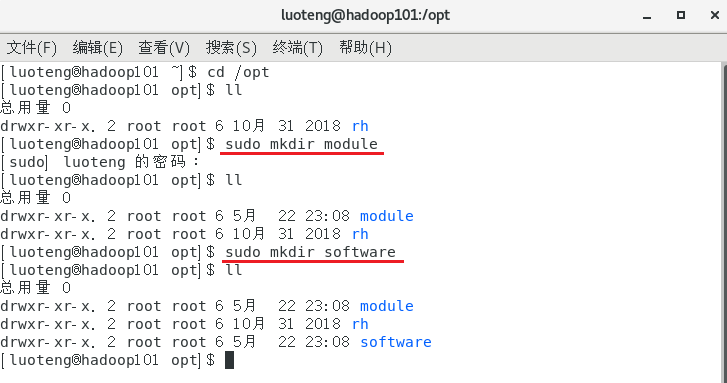
在 /opt 目录下创建 module 和 software 两个文件夹,一个用来存放 jar 包,一个用来 存放 jar 包解压后的文件。1
2>>> sudo mkdir module
>>> sudo mkdir software
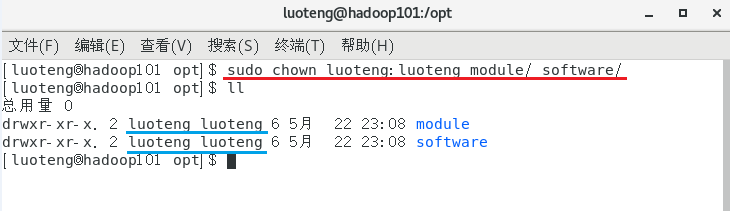
运行命令 ll 发现文件夹的所有者为 root 账号,为了方便以后用 luoteng 账号操作,修改 module software 文件夹的所有者。1
>>> sudo chown luoteng:luoteng module/ software/
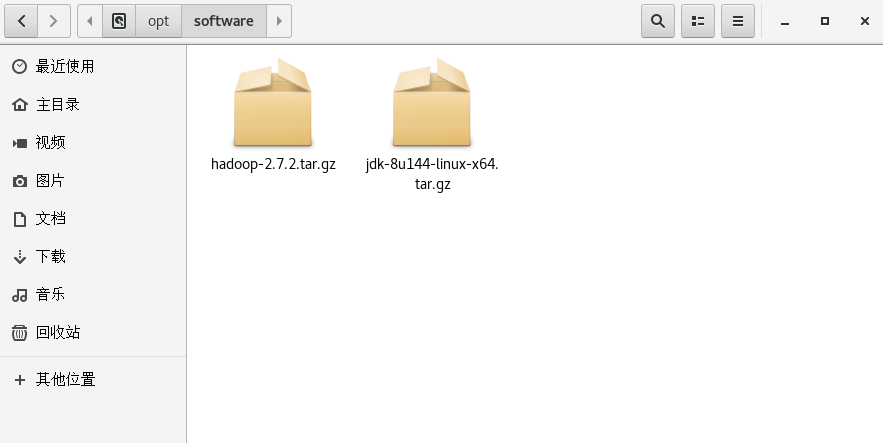
把上面下载好的 jdk 文件放入目录 software ,同时把事前准备好的 hadoop jar 包也放入目录 software ,待安装文件准备就绪,准备安装。
安装 jdk
解压 jdk 到 /opt/module 目录下1
>>> tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
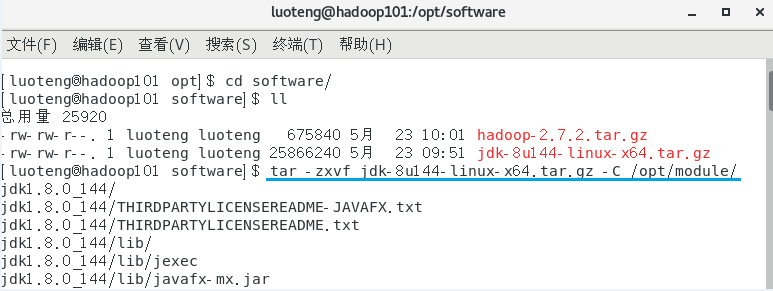
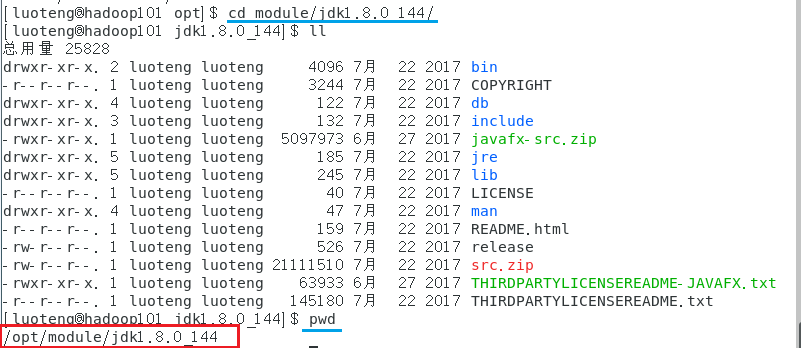
配置 jdk 环境变量,首先进入目录 /opt/module/jdk1.8.0_144 ,运行命令 pwd 获取路径地址,如下图
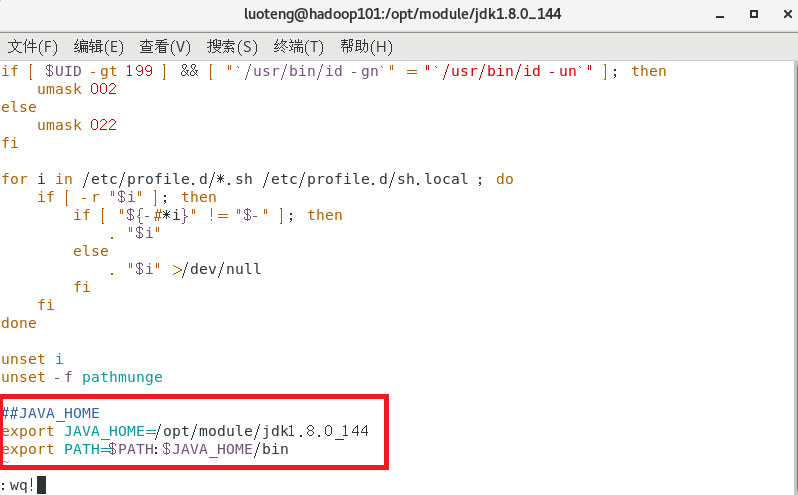
运行命令 sudo vim /etc/profile 打开 /etc/profile 文件,在末尾作如下修改:
2
3
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
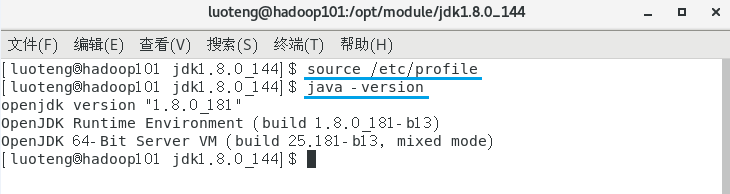
运行如下命令,让修改的文件生效,并测试一下 jdk 是否安装成功1
2>>> source /etc/profile
>>> java -version
配置 hadoop
安装 hadoop
进入到 Hadoop 安装包路径下,解压 hadoop 到 /opt/module 目录下1
>>> tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
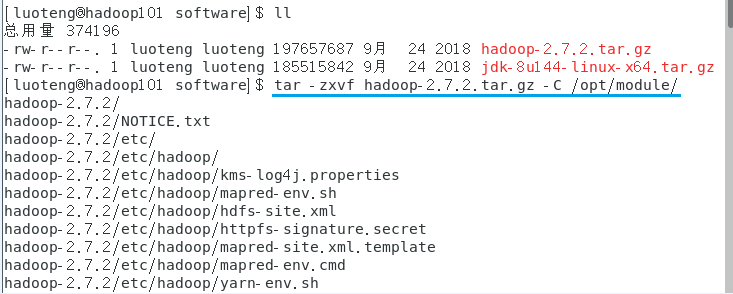
查看是否解压成功1
>>> ls /opt/module/
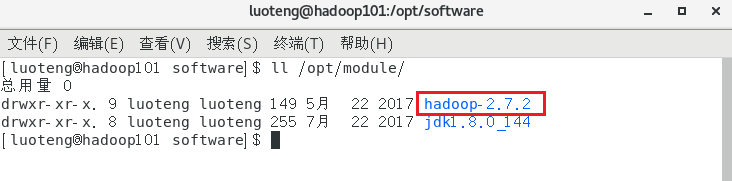
配置环境变量,首先进入目录 /opt/module/hadoop-2.7.2 ,运行命令 pwd 获取路径地址,如下图
运行命令 sudo vim /etc/profile 打开 /etc/profile 文件,在末尾作如下修改:
2
3
4
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
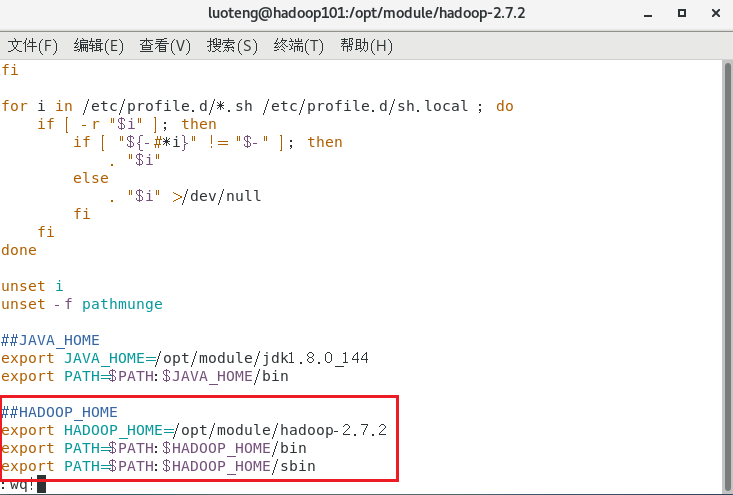
运行如下命令,让修改的文件生效,并测试一下 hadoop 是否安装成功1
2>>> source /etc/profile
>>> hadoop
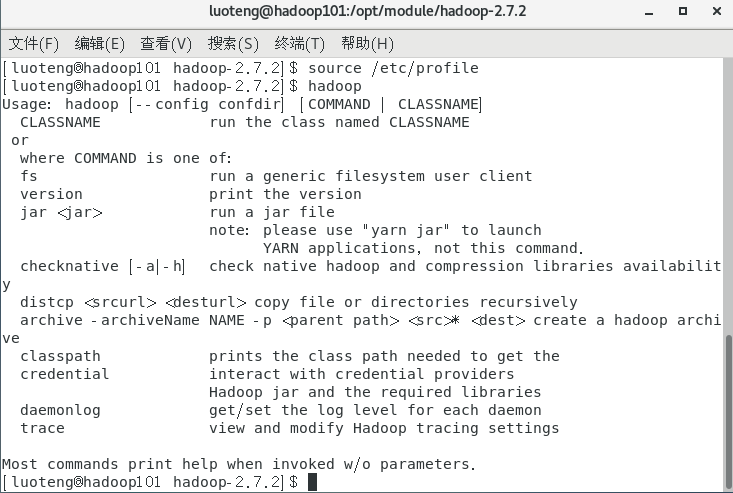
如上图所示,表示安装完成。
hadoop 文件说明
进入 hadoop 的 bin 目录下,看下都有哪些命令,如下图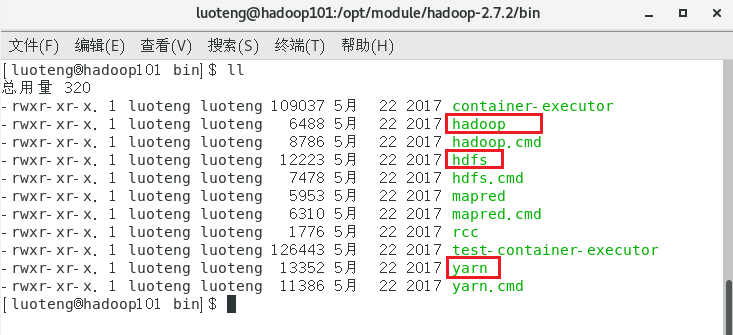
hdfs 管理分布式文件系统,hadoop 管理整个集群,yarn 负责资源调度。
进入 hadoop 的 etc/hadoop 目录,里面存放所有的 hadoop 的配置文件,看下都有哪些配置文件,如下图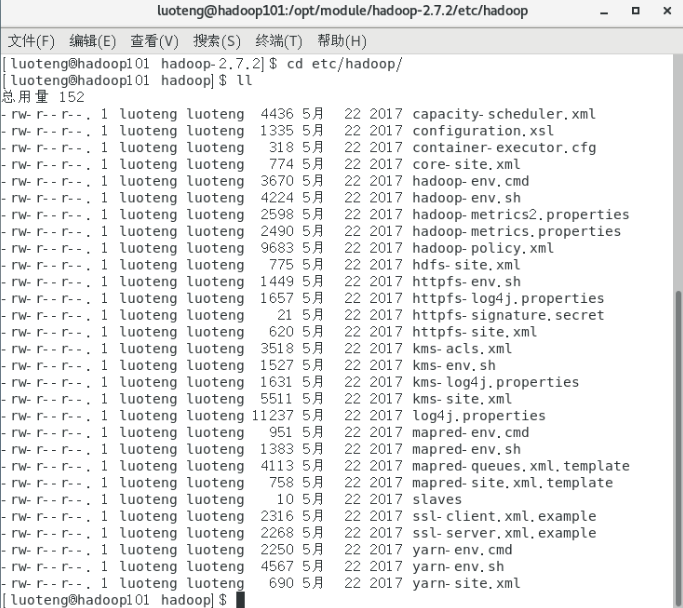
进入 hadoop 的 sbin 目录,里面存放启动集群和停止集群的命令,看下都有哪些命令,如下图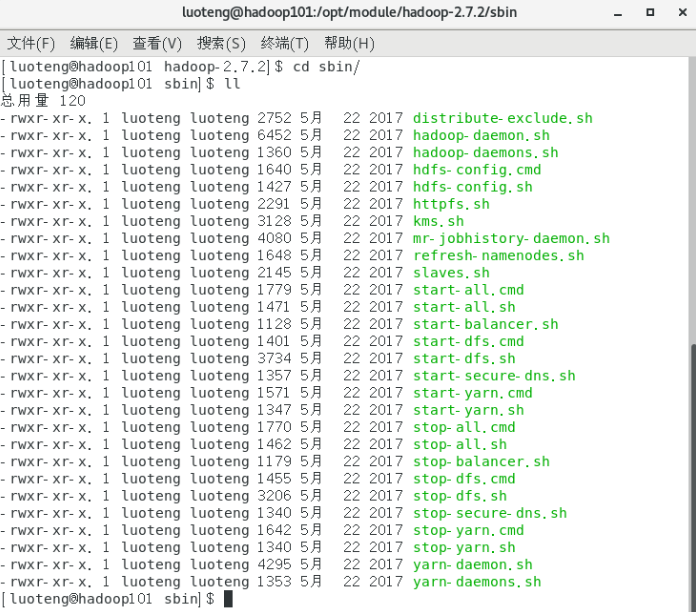
完全分布式部署 Hadoop
- 准备 3 台客户机(关闭防火墙、 静态 ip、主机名称)
- 安装 jdk
- 配置环境变量
- 安装 hadoop
- 配置环境变量
- 安装 ssh
- 配置集群
- 启动测试集群
hadoop 的完全分布式部署步骤总结如上,其中 1~5 上文都有讲解,我们就不一台一台的配置客户机,直接拿配置好的虚拟机进行克隆。
准备虚拟机
我们在 hadoop101 的基础上克隆在克隆两台虚拟机。克隆好的虚拟机记得一定更改相应的 ip 地址,主机名称,物理地址等信息。
我们将两台克隆好的虚拟机分别命名为 hadoop102 和 hadoop103 ,网络IP地址分别设置为 192.168.1.102 和 192.168.1.103 。如下图所示: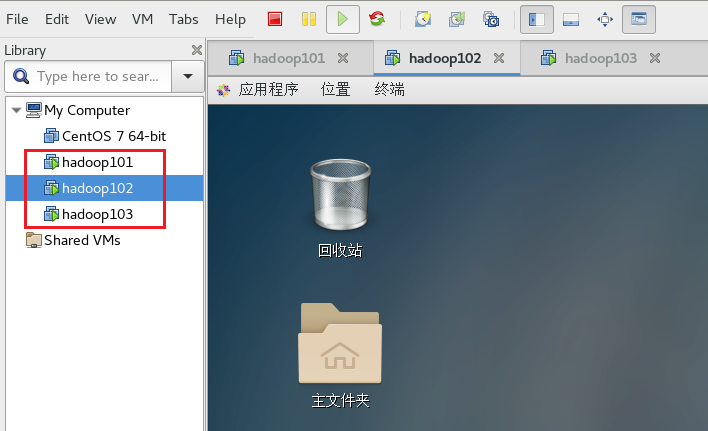
远程同步工具 rsync
rsync 远程同步工具,主要用于备份和镜像。具有速度快、 避免复制相同内容和支持符号链接的优点。
rsync 和 scp 区别: 用 rsync 做文件的复制要比 scp 的速度快,rsync 只对差异文件做更新。scp 是把所有文件都复制过去。
相关命令
- 查看 rsync 使用说明
man rsync | more - 基本语法
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
选项:- -r 递归
- -v 显示复制过程
- -l 拷贝符号连接
编写集群分发脚本
在 hadoop101 的 home/user/bin 目录下创建文件 xsync 。
首先运行命令 mkdir bin 创建文件夹 bin ,再运行命令 touch xsync 创建 xsync 文件。如下图所示: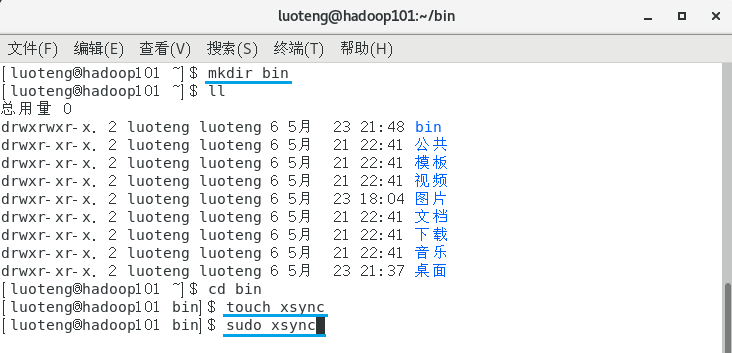
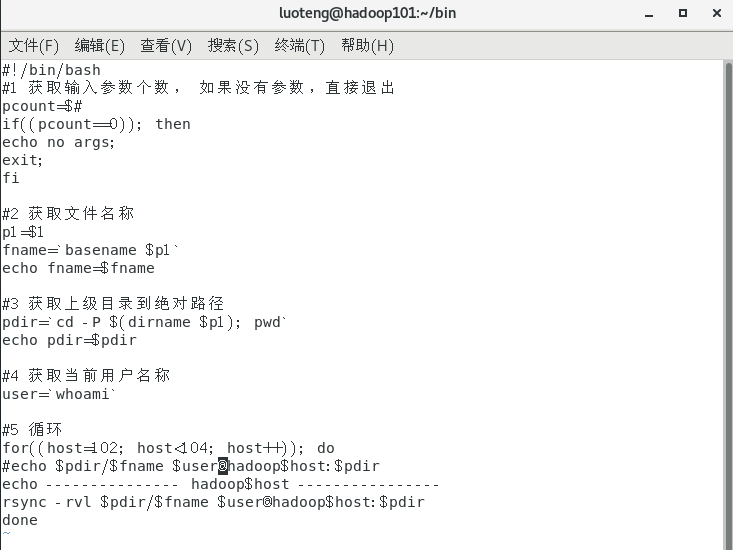
运行命令 sudo vim xsync ,然后在文件中写入如下内容:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26#!/bin/bash
#1 获取输入参数个数, 如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=102; host<104; host++)); do
#echo $pdir/$fname $user@hadoop$host:$pdir
echo --------------- hadoop$host ----------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
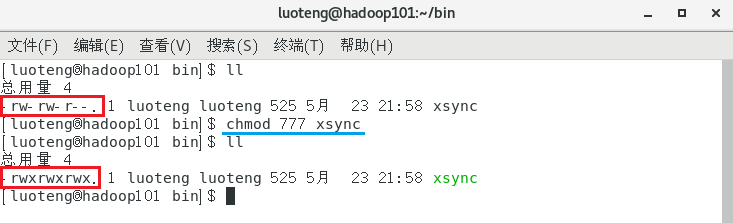
修改脚本 xsync 具有执行权限1
>>> chmod 777 xsync
测试 xsync 脚本,将 hadoop101 的 bin 目录及文件分发到 hadoop102 和 hadoop03 上,运行如下命令1
>>> xsync bin/
运行结果如下图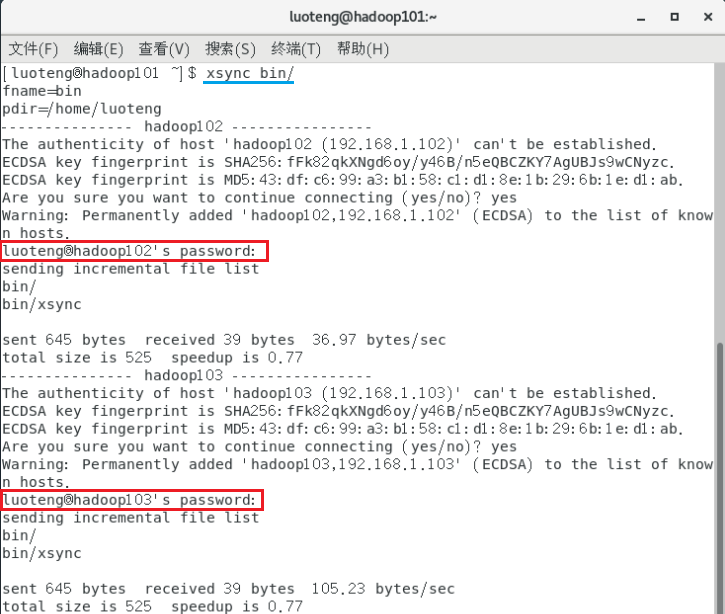
上图中每次分发文件都需要输入密码(红框部分),如果有 100 台服务器岂不是要输入 100 次?下面我们设置一下 SSH 免密码登陆,设置后可以解决输入密码问题。
SSH 免密登陆
ssh 免密登陆原理如下图所示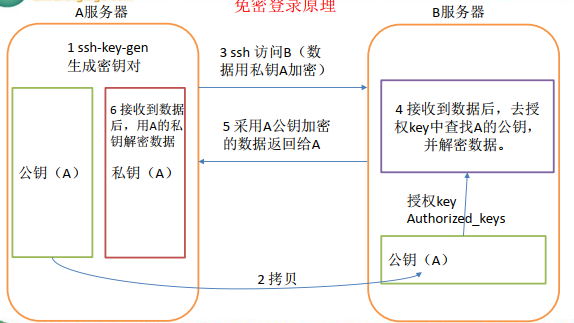
无密钥配置操作步骤:
进入到我的 home 目录的
.ssh文件夹下(如果没有该文件夹,可以运行下 ssh 命令会自动生成一个)1
>>> cd ~/.ssh
生成公钥和私钥
1
>>> ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件
id_rsa(私钥)、id_rsa.pub(公钥)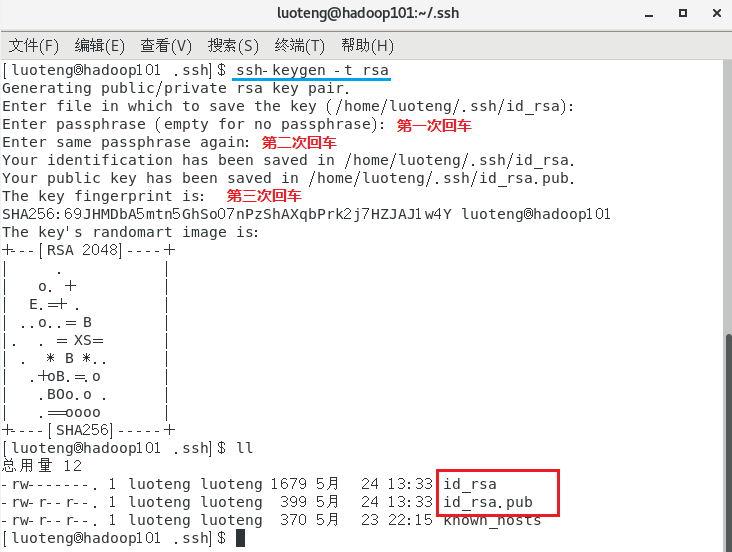
将公钥拷贝到要免密登录的目标机器上
1
2
3>>> ssh-copy-id hadoop102
>>> ssh-copy-id hadoop103
>>> ssh-copy-id hadoop101运行完成后,我们发现目标机器上的
.ssh/文件夹下会多出一个authorized_keys文件,如下图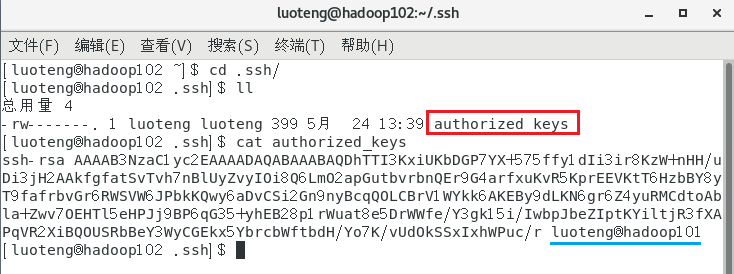
同样的操作步骤在 hadoop102 上执行一边。因为后面集群配置的时候我们将 hadoop101 设置为 NameNode ,将 hadoop102 设置为 ResourceManager,这两个节点都需要进行文件分发操作。
同理,我们只让 hadoop101 上的 luoteng 账户进行分发授权,root 账户还没有免密登陆授权,所以在 hadoop101 上 hadoop101 切换下 root 账号,同样操作步骤再来一轮。
我们在进行 ssh 远程登录,就不需要输入密码了,如下图所示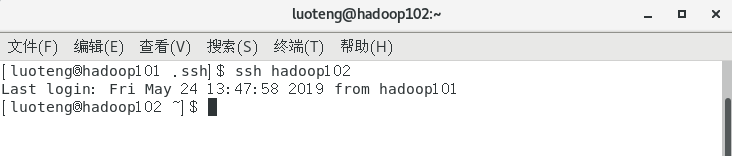
.ssh 文件夹下的文件功能解释
- ~/.ssh/known_hosts :记录 ssh 访问过计算机的公钥(public key)
- id_rsa :生成的私钥
- id_rsa.pub :生成的公钥
- authorized_keys :存放授权过得无秘登录服务器公钥
集群配置
集群部署规划
| hadoop101 | hadoop102 | hadoop103 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN | NodeManager |
ResourceManager NodeManager |
NodeManage |
配置 core-site.xml
进入目录 etc/hadoop ,打开 core-site.xml 文件1
>>> vim core-site.xml
在文件中写入如下内容:1
2
3
4
5
6
7
8
9
10<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
如下图所示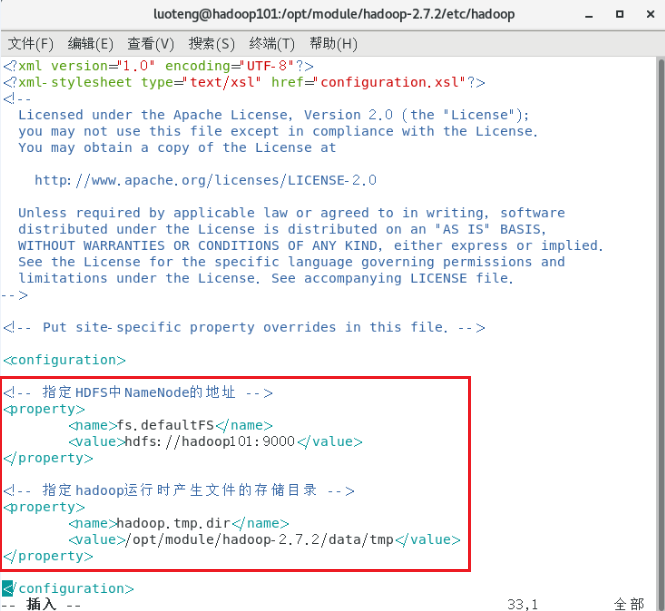
配置 Hdfs
打开 hadoop-env.sh 文件1
>>> vim hadoop-env.sh
修改文件内容 export JAVA_HOME=/opt/module/jdk1.8.0_144 ,如下图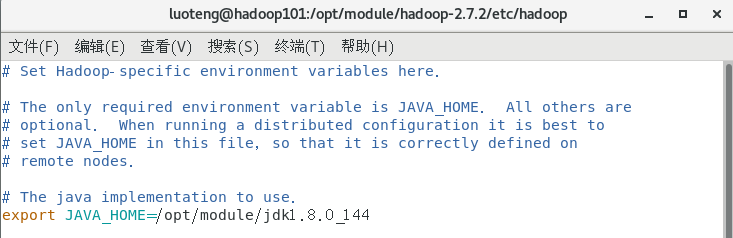
打开 hdfs-site.xml 文件1
>>> vim hdfs-site.xml
在文件中写入如下内容:1
2
3
4
5
6
7
8
9
10
11<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
如下图所示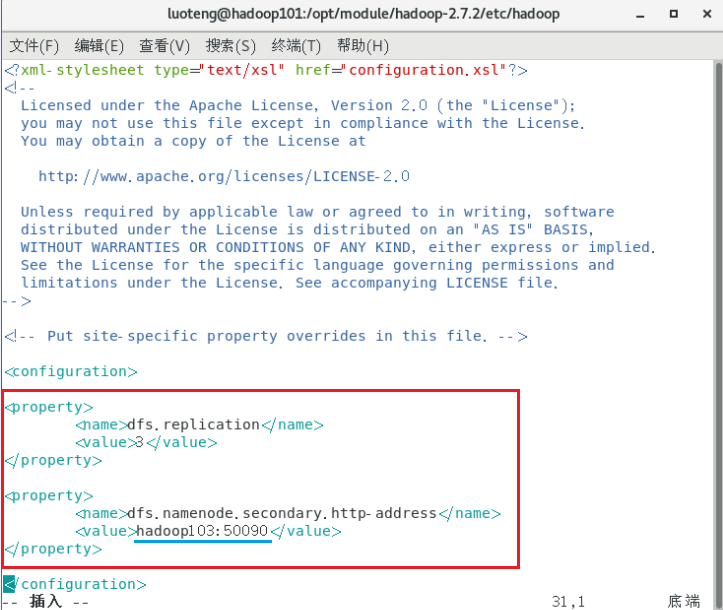
配置 yarn
打开 yarn-env.sh 文件1
>>> vim yarn-env.sh
修改文件内容 export JAVA_HOME=/opt/module/jdk1.8.0_144 ,如下图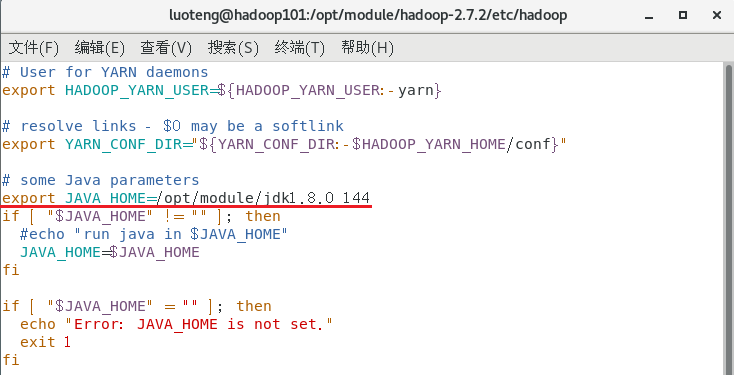
打开 yarn-site.xml 文件1
>>> vim yarn-site.xml
在文件中写入如下内容:1
2
3
4
5
6
7
8
9
10
11<!-- reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 YARN 的 ResourceManager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
如下图所示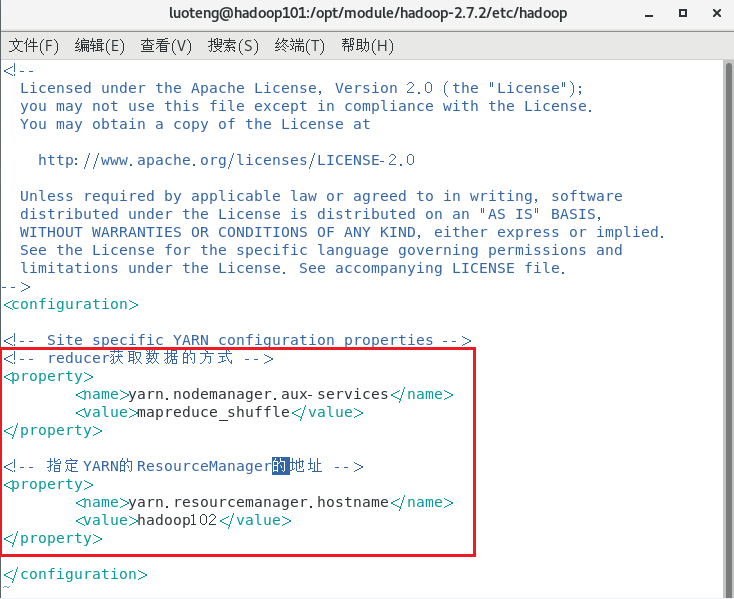
配置 mapreduce
打开 mapred-env.sh 文件1
>>> vim mapred-env.sh
修改文件内容 export JAVA_HOME=/opt/module/jdk1.8.0_144 ,如下图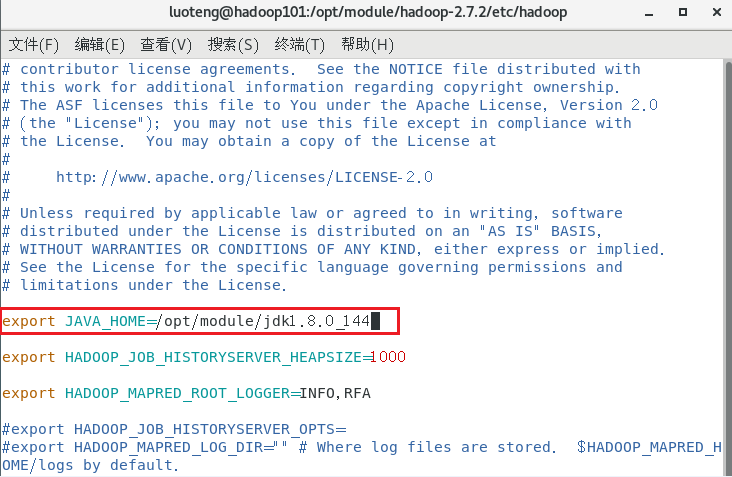
首先将配置文件 mapred-site.xml.template 拷贝一份,命名为 mapred-site.xml1
>>> cp mapred-site.xml.template mapred-site.xml
打开 mapred-site.xml 文件1
>>> vim mapred-site.xml
在文件中写入如下内容:1
2
3
4
5<!-- 指定 mr 运行在 yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
如下图所示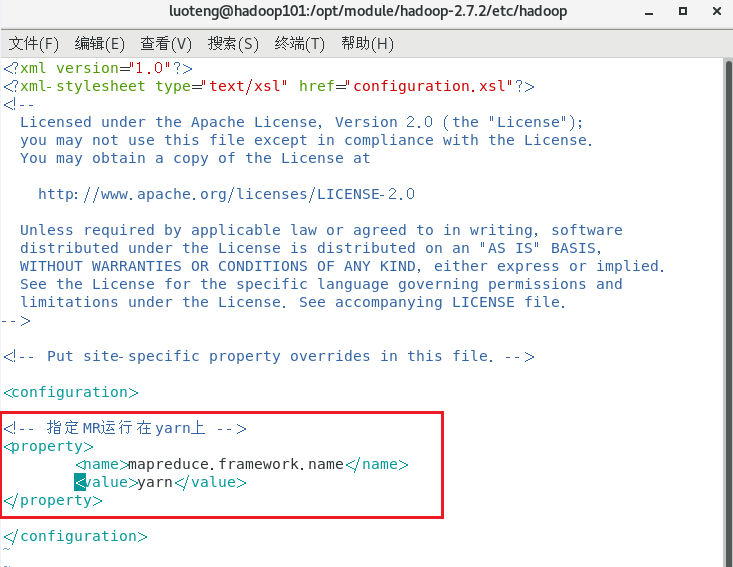
配置 slaves
打开 slaves 文件1
>>> vim slaves
在该文件中添加(有几个 DataNode 就添加几个节点)1
2
3hadoop101
hadoop102
hadoop103
如下图所示
注意该文件下不能有空格,也不允许有换行。配置该文件的主要目的是群起集群,如果不配置该文件,集群只能一个节点一个节点启动。
在集群上分发配置文件
退回到 etc 目录下,运行下面命令,将 hadoop 文件夹下所有文件进行分发操作1
>>> xsync hadoop/
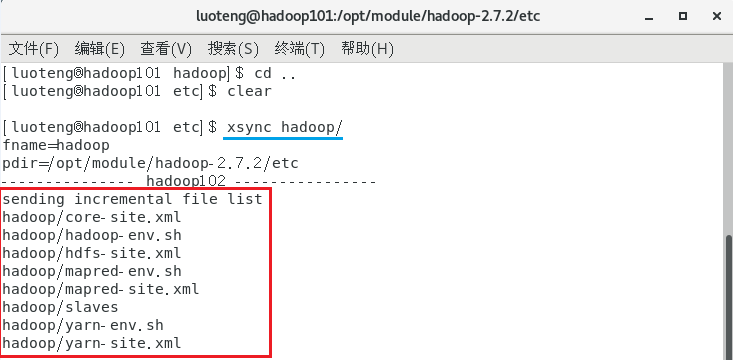
如上图,我们注意到,由于前面配置过 ssh 免密登陆,这里不需要输入密码了,完美!
群启集群
如果集群是第一次启动,需要格式化 NameNode ,命令如下:1
>>> bin/hdfs namenode -format
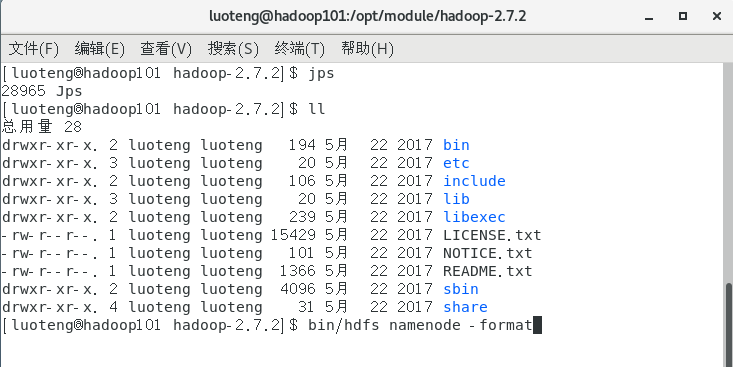
我们看到 hadoop 跟目录下没有 data 和 logs 文件夹,是因为这是第一次启动集群,如果不是第一次启动集群而进行格式化操作,需要运行命令 rm -rf data/ logs/ 删除 data 和 logs 文件夹的内容,在进行格式化操作,否则会出现问题。
见到如下图所示的样子,表示格式化完成。
启动集群,在 hadoop101 节点的 /opt/module/hadoop-2.7.2 目录下,运行命令:1
>>> sbin/start-dfs.sh
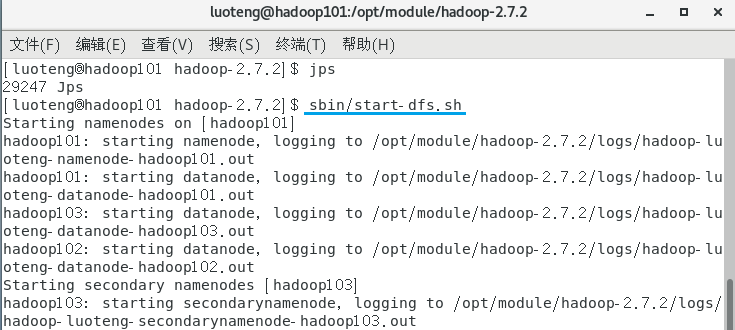
启动 yarn ,在 hadoop102 节点的 /opt/module/hadoop-2.7.2 目录下,运行命令:1
>>> sbin/start-yarn.sh
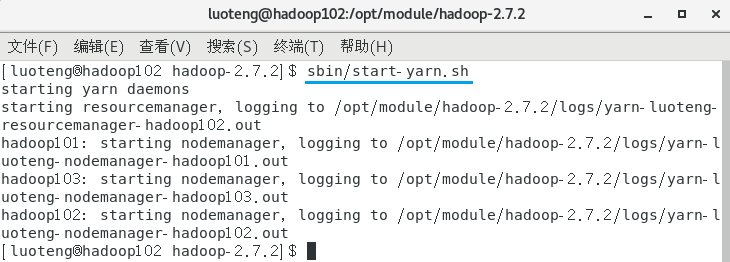
集群启动后,我们分别在三个节点上输入命令 jps 看下启动的节点是否跟我们预先设定的集群部署规划一致:
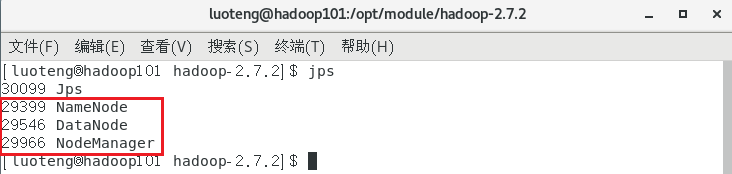
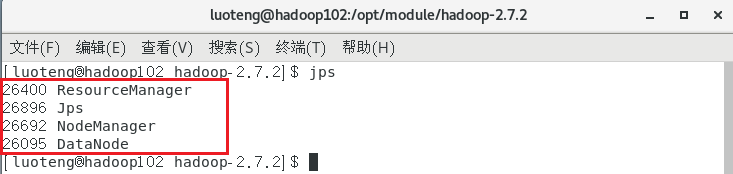
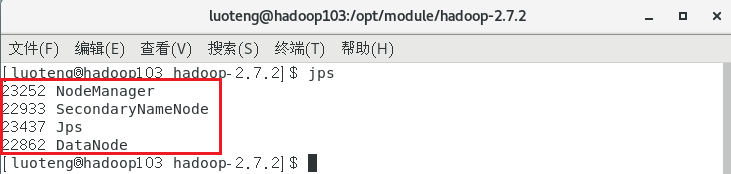
网页中查看
集群启动之后,我们可以通过网页对 hadoop 的 HDFS 文件系统和 yarn 管理系统进行查看。
web 端查看 HDFS 文件系统,在网页中输入:
如下图所示: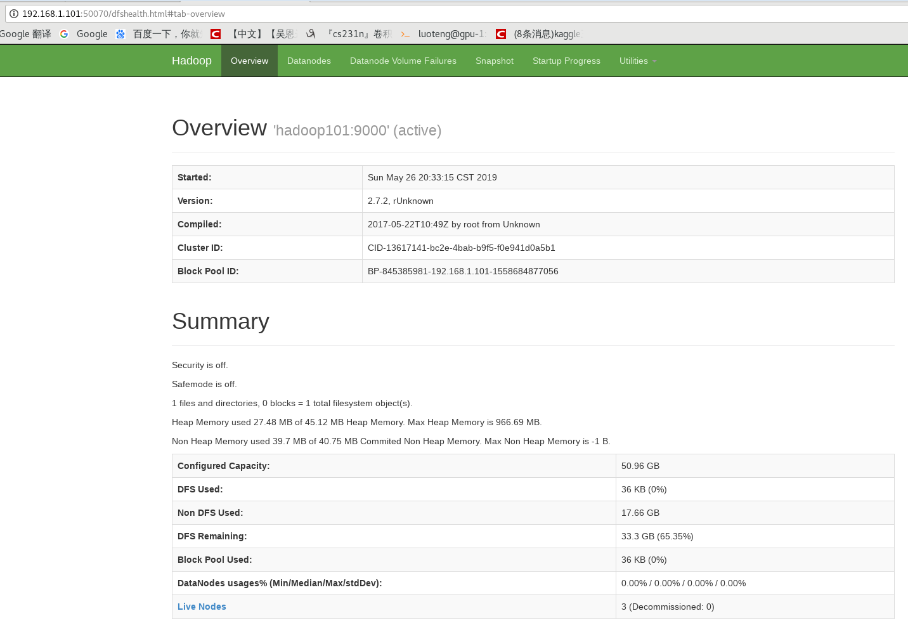
点击标签 Utilities -> Browse the file system ,即可以浏览文件。
yarn 的浏览器页面查看地址:
如下图所示: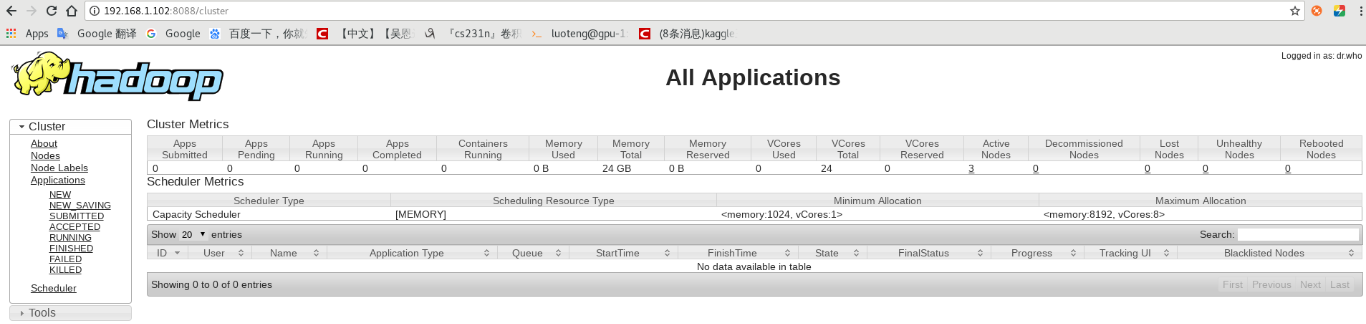
集群启动与停止
集群停止命令很简单,只需要将启动的 start 改成 stop 即可。
各个服务组件逐一启动
分别启动 hdfs 组件
1
>>> hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
启动 yarn
1
>>> yarn-daemon.sh start|stop resourcemanager|nodemanager
各个模块分开启动(配置 ssh 是前提) 常用
整体启动/停止 hdfs
1
2>>> start-dfs.sh
>>> stop-dfs.sh整体启动/停止 yarn
1
2>>> start-yarn.sh
>>> stop-yarn.sh全部启动(不建议使用)
1
2>>> start-all.sh
>>> stop-all.sh
